TL;DR
环境准备
- mongoDB
预备知识
MongoDB常见的数据类型
| 数据类型 | 示例 | 说明 |
|---|---|---|
| Null | {"x" : null} |
|
| Boolean | {"x" : true} |
|
| Number | {"x" : 3.14} {"x" : 3} {"x" : NumberInt("3")} {"x" : NumberLong("3")} |
默认64位浮点数,整数需要使用NumberInt和NumberLong |
| String | {"x" : "foobar"} |
编码格式为UTF-8 |
| Date | {"x" : new Date()} |
64位时间戳(从January 1, 1970),不存时区。通过new Date()进行调用。 |
| Regular expression | {"x" : /foobar/i} |
javascript 正则 |
| Array | {"x" : ["a", "b", "c"]} |
|
| Embedded document | {"x" : {"foo" : "bar"}} |
|
| Object ID | {"x" : ObjectId()} |
文档12字节的ID |
| Binary data | 一个任意字节的字符串。是保存非UTF-8字符串到数据库的唯一方法。 | |
| Code | {"x" : function() { /* ... */ }} |
数据操作
数据库连接
连接字符串
MongoDB的连接字符串为如下格式

示例连接地址 mongodb://user:[email protected]:27017/?maxPoolSize=20&w=majority
官方提供的连接字符选项说明
Option Name Type Default Value Description connectTimeoutMS integer 30000Specifies the number of milliseconds to wait before timeout on a TCP connection. maxPoolSize integer 100Specifies the maximum number of connections that a connection pool may have at a given time. replicaSet string nullSpecifies the replica set name for the cluster. All nodes in the replica set must have the same replica set name, or the Client will not consider them as part of the set. maxIdleTimeMS integer 0Specifies the maximum amount of time a connection can remain idle in the connection pool before being removed and closed. The default is 0, meaning a connection can remain unused indefinitely.minPoolSize integer 0Specifies the minimum number of connections that the driver maintains in a single connection pool. socketTimeoutMS integer 0Specifies the number of milliseconds to wait for a socket read or write to return before returning a network error. The 0default value indicates that there is no timeout.serverSelectionTimeoutMS integer 30000Specifies the number of milliseconds to wait to find an available, suitable server to execute an operation. heartbeatFrequencyMS integer 10000Specifies the number of milliseconds to wait between periodic background server checks. tls boolean falseSpecifies whether to establish a Transport Layer Security (TLS) connection with the instance. This is automatically set to truewhen using a DNS seedlist (SRV) in the connection string. You can override this behavior by setting the value tofalse.w string or integer nullSpecifies the write concern. To learn more about values, see the server documentation on Write Concern options. directConnection boolean falseSpecifies whether to force dispatch all operations to the host specified in the connection URI.
MongoDB连接字符串中,auth参数和dbsource参数用于实现数据库认证和授权功能。
auth参数指定进行认证的用户和密码,格式为:
authSource=admin&authMechanism=SCRAM-SHA-1&authMechanismProperties=SERVICE_NAME:service_name
其中,authSource为存储用户凭证的数据库,默认为admin; authMechanism为认证机制,默认为SCRAM-SHA-1; authMechanismProperties指定了认证使用的服务名称,可以为空。
dbsource参数指定要使用的数据库,格式为:dbsource=database_name 其中,database_name为要连接的数据库名称。如果不指定该参数,则默认使用连接字符串中指定的authSource数据库。
示例:
mongodb://user:password@localhost:27017/?authSource=admin&authMechanism=SCRAM-SHA-1&authMechanismProperties=SERVICE_NAME:mongo-service&dbsource=mydatabase
解释:
- user和password为认证所需的用户名和密码;
- localhost:27017为MongoDB的地址和端口号;
- authSource=admin表示使用admin数据库进行认证;
- authMechanism=SCRAM-SHA-1指定使用SCRAM-SHA-1算法进行认证;
- authMechanismProperties=SERVICE_NAME:mongo-service指定使用名为mongo-service的服务;
- dbsource=mydatabase指定要使用的数据库名称为mydatabase。
数据库驱动
这里以Golang语言为例。本文使用MongoDB标准数据库驱动,未使用ODM框架如mgm、upper/db、mango等。引入方法
import "go.mongodb.org/mongo-driver/mongo"
Demo程序如下:
package main
import (
"context"
"fmt"
"go.mongodb.org/mongo-driver/mongo"
"go.mongodb.org/mongo-driver/mongo/options"
"go.mongodb.org/mongo-driver/mongo/readpref"
)
// Connection URI
const uri = "mongodb://user:[email protected]:27017/?maxPoolSize=20&w=majority"
func main() {
// Create a new client and connect to the server
client, err := mongo.Connect(context.TODO(), options.Client().ApplyURI(uri))
if err != nil {
panic(err)
}
defer func() {
if err = client.Disconnect(context.TODO()); err != nil {
panic(err)
}
}()
// Ping the primary
if err := client.Ping(context.TODO(), readpref.Primary()); err != nil {
panic(err)
}
fmt.Println("Successfully connected and pinged.")
}
BSON简介
MongoDB中的JSON文档存储在名为BSON(二进制编码的JSON)的二进制表示中。与其他将JSON数据存储为简单字符串和数字的数据库不同,BSON编码扩展了JSON表示,使其包含额外的类型,如int、long、date、浮点数和decimal128。这使得应用程序更容易可靠地处理、排序和比较数据。
连接MongoDB的Go驱动程序中有两大类型表示BSON数据:D和Raw。
类型D家族被用来简洁地构建使用本地Go类型的BSON对象。这对于构造传递给MongoDB的命令特别有用。D家族包括四类:
D:一个BSON文档。这种类型应该在顺序重要的情况下使用,比如MongoDB命令。M:一张无序的map。它和D是一样的,只是它不保持顺序。A:一个BSON数组。E:D里面的一个元素。
要使用BSON,需要先导入下面的包:
import "go.mongodb.org/mongo-driver/bson"
下面是一个使用D类型构建的过滤器文档的例子,它可以用来查找name字段与’张三’或’李四’匹配的文档:
bson.D{{
"name",
bson.D{{
"$in",
bson.A{"张三", "李四"},
}},
}}
Raw类型家族用于验证字节切片。你还可以使用Lookup()从原始类型检索单个元素。如果你不想要将BSON反序列化成另一种类型的开销,那么这是很有效的一种手段。下面介绍MongoDB的一些基本操作。
新增数据
insertOne
insertOne用于插入一条记录:
db.movies.insertOne({"title" : "Stand by Me"})
insertMany
insertMany用于插入多条记录:
db.movies.insertMany([{"title" : "Ghostbusters"},
{"title" : "E.T."},
{"title" : "Blade Runner"}]);
删除数据
deleteOne
db.movies.deleteOne({"_id" : 4})
deleteMany
db.mailing.list.deleteMany({"opt-out" : true})
drop
drop用于删除collection
db.movies.drop()
更新数据
一般更新
一般更新使用findOneAndReplace updateOne updateMany方法。
常见逻辑操作符
| 操作符 | 含义 | 示例 |
|---|---|---|
| $inc | 数值类型数据增加。可用于数值类型 integer long double decimal的增加及减小。 |
db.analytics.updateOne({"url" : "www.example.com"}, {"$inc" : {"pageviews" : 1}}) |
| $mul | 乘法($mul)运算符用于将一个数字字段的值乘以 给定的数字。 | db.movies.findOneAndUpdate( {"title" : "Macbeth"},{$mul : {"rating" : 2}},{returnNewDocument : true}) |
| $rename | $rename操作符用于重命名字段。 | db.movies.findOneAndUpdate({"title" : "Macbeth"},{$rename : {"num_mflix_comments" : "comments", "imdb_rating" : "rating"}}, {returnNewDocument : true}) |
| $set | 更新字段值,不存在会自动创建。 | db.user.updateOne({_id:2},{"$set":{"lovemusic":"jaychou"}}); |
| $setOnInsert | $setOnInsert与$set类似,但是,它只在upsert插入操作时设置给定的字段。如果要更新的文档存在则不更新。 | db.products.update( { _id: 1 }, { $set: { item: "apple" }, $setOnInsert: { defaultQty: 100 } }, { upsert: true } ) |
| $unset | 删除键及对应的值 | 示例1db.user.updateOne({_id:2},{"$unset":{"lovemusic":"jaychou"}});示例2db.user.update({"email_state":{"$exists":true}},{"$unset":{"email_state",""}},{multi:true});该语句将删除表的email_state字段 |
| $push | 当字段为数组对象时,更新字段使用。可以往数组对象添加记录。 | db.blog.posts.updateOne({"title" : "A blog post"},{"$push" : {"comments" :{"name" : "joe", "email" : "[email protected]","content" : "nice post."}}}) |
| $each | 和$push配合使用,适用于一次操作添加多个记录的情况 | db.stock.ticker.updateOne({"_id" : "GOOG"}, {"$push" : {"hourly" : {"$each" : [562.776, 562.790, 559.123]}}}) |
| $slice | 配合$push和$each使用,用于限制字段数组的最大长度。右侧的示例意思为,将数组内容限制为10条记录,导入优先级从后向前。单独使用,可以实现TOP的效果 | 配合使用db.movies.updateOne({"genre" : "horror"}, {"$push" : {"top10" : {"$each" : ["Nightmare on Elm Street", "Saw"], "$slice" : -10}}})单独使用db.blog.posts.findOne(criteria, {"comments" : {"$slice" : 10}})返回前10条记录db.blog.posts.findOne(criteria, {"comments" : {"$slice" : [23, 10]}})返回从24条开始的10条数据 db.blog.posts.findOne(criteria, {"comments" : {"$slice" : -1}})返回最后一条评论 |
| $sort | 配合$push和$each使用,用于设置添加记录字段的排序,1升序 -1 降序 | db.movies.updateOne({"genre" : "horror"}, {"$push" : {"top10" : {"$each" : [{"name" : "Nightmare on Elm Street", "rating" : 6.6}, {"name" : "Saw", "rating" : 4.3}], "$slice" : -10, "$sort" : {"rating" : -1}}}}) |
| $ne | 判断记录是否已经存在于数组。可以理解为Is Not Exist | db.papers.updateOne({"authors cited" : {"$ne" : "Richie"}},{$push : {"authors cited" : "Richie"}}) |
| $currentDate | $currentDate用于设置一个给定字段的值为当前的 日期或时间戳。 | db.movies.findOneAndUpdate( {"title" : "Macbeth"}, {$currentDate : { "created_date" : true, "last_updated.date" : {$type : "date"}, "last_updated.timestamp" : {$type : "timestamp"},}}, {returnNewDocument : true}) |
| $addToSet | 功能与$ne有部分重叠,添加前会检查是否存在以避免重复,适用于$ne不适用的场景且有更好的描述性。 | db.users.updateOne({"_id" : ObjectId("4b2d75476cc613d5ee930164")},{"$addToSet" : {"emails" : "[email protected]"}}) |
| $pop | 从数组尾部移除。{"$pop" : {“key” : 1}}从尾部移除1条记录,{"$pop" : {“key” : -1}}从前面移除1条记录。 | |
| $pull | 移除所有满足条件的记录。例如记录为[1,2,3,1]调用$pull删除1,则只剩下[2,3] | 插入几条数据db.lists.insertOne({"todo" : ["dishes",dishes", "laundry", "dry cleaning"]}) 删除一条数据 db.lists.updateOne({}, {"$pull" : {"todo" : "dishes"}}) |
| $ | 位置运算符,用于替代筛选记录的Index。该运算符只更新第一个匹配的记录。 | db.blog.updateOne({"comments.author" : "John"},{"$set" : {"comments.$.author" : "Jim"}}) |
| arrayFilters | db.blog.updateOne({"post" : post_id },{ $set: { "comments.$[elem].hidden" : true } },{ arrayFilters: [ { "elem.votes": { $lte: -5 } } ]}) |
Upsert更新
Upsert是一种特殊的更新。如果记录不存在会合并筛选条件和更新记录来自动创建记录。示例:
db.post.updateOne({title:"my love song"},{$set:{content:{head:"js",body:"javascript"}}},{upsert:true});
查询数据
MongoDB 常用查询的逻辑操作符如下:
| 运算符 | 含义 |
|---|---|
| $lt | < |
| $lte | <= |
| $gt | > |
| $gte | >= |
| $ne | != |
| $in | in |
| $nin | not in |
| $or | or |
| $not | not |
| $nor | $nor操作符在语法上与$or相似,但行为方式相反。$nor运算符$nor操作符以数组的形式接受多个条件表达式,并且 返回不满足任何给定条件的文档。db.movies.find({$nor:[{"rated" : "G"},{"year" : 2005}, {"num_mflix_comments" : {$gte : 5}}]}) |
| $mod | mod取模运算。如 db.users.find({"id_num" : {"$mod" : [5, 1]}})返回用户id为1 , 6 , 11 , 16等符合取模运算的记录。 |
| $regex | 正则匹配 |
| $all | 所有 满足条件的记录 |
| $size | 将数组长度作为查询的一部分。如db.food.find({"fruit" : {"$size" : 3}})表示查询所有fruit字段值为3元素数组的记录。 |
| $elemMatch | 强迫MongoDB用一个单个数组元素进行比较,不匹配非数组元素.db.test.find({"x" : {"$elemMatch" : {"$gt" : 10, "$lt" : 20}}})表示查询字段为数组且数组元素均满足 10<x<20的记录。 |
| $where | |
| $match | db.companies.aggregate([{$match: {founded_year: 2004}}])等价于db.companies.find({founded_year: 2004}) |
find/findOne
find用于查询所有满足条件的记录。示例:
db.users.find({"username" : "joe"})
注:传入{}表示全部查询。
- 指定返回字段的查询,示例:
db.users.find({}, {"username" : 1, "email" : 1})
默认是要返回_id字段,如果要隐藏,则上面的语句需要改成下面的语句(其他字段如果需要隐藏,操作也是类似):
db.users.find({}, {"username" : 1,"email" : 1, "_id" : 0})
- 比较查询
db.users.find({"age" : {"$gte" : 18, "$lte" : 30}})
- IN查询
db.raffle.find({"ticket_no" : {"$in" : [725, 542, 390]}})
- OR查询
db.raffle.find({"$or" : [{"ticket_no" : 725}, {"winner" : true}]})
- 查询字段为null的记录
db.c.find({"z" : {"$eq" : null, "$exists" : true}})
默认查询不存在的记录会返回所有的记录,所以需要添加$exist来检查记录是否存在。
-
数组查询,如一个表有下面的记录:

则可以使用语句
db.food.find({"fruit" : "banana"})进行查询。如果要查询多条数据,可以使用$all来查询,示例语句db.food.find({fruit : {$all : ["apple", "banana"]}})表示查询所有fruit为apple和banana的记录。 -
正则模糊匹配查询
db.users.find( {"name" : {"$regex" : /joe/i } })注:MongoDB的正则引擎为
PCRE
sort
设置按记录字段的排序。
db.c.find().sort({username : 1, age : -1})
注:1 表示升序排列 -1 表示降序排列。
skip
跳过数据条数。类似于limit,区别在于Skip设置的是数据数量的下限。
db.c.find().skip(3)
当Skip的数字较大时,请勿使用skip,这会影响数据库的性能。
limit
限制返回记录条数。limit设置的是数据数量的上限。
db.c.find().limit(3)
distinct
查询去重。
db.movies.distinct("rated", {"year" : 1994})
countDocuments/count/estimatedDocumentCount
查询统计
db.movies.countDocuments({"year": 1999})
聚合查询 Aggregation
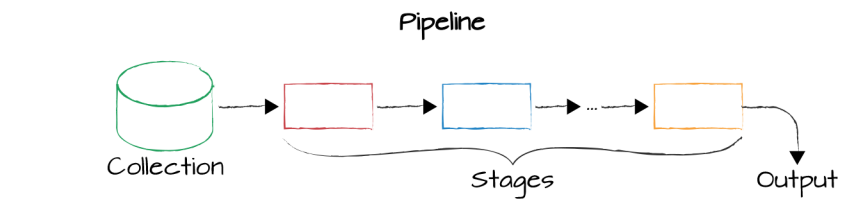
MongoDB聚合查询用于对数据文档进行变换和组合。实现上,MongoDB聚合管道基于数据流的概念,数据进入管道经过多个stage操作(主要有筛选、投射、分组、排序、限制及跳过),最终输出。常用管道操作符参考下表:
| 操作符 | 简述 |
|---|---|
| $project | 投射操作符,用于重构每一个文档的字段,可以提取字段,重命名字段,甚至可以对原有字段进行操作后新增字段。如db.users.aggregate([{ $project : { userId: '$_id', _id: 0 } }]);将_id 字段重命名为userId ,不显示字段_id。 |
| $match | 匹配操作符,用于对文档集合进行筛选。 |
| $group | 分组操作符,用于对文档集合进行分组。_id字段是必须的。db.users.aggregate([{$group : {_id: '$sex',avgAge: { $avg: '$age' }, count: { $sum: 1 }}} ]);将用户按性别分组并显示各性别的平均年龄,最后返回各性别人数。db.users.aggregate([{$match:{locale:{$eq:"zh-Hans"}}},{$group: {_id: "$username",Email: {$addToSet: "$email",}}}])返回语言为中文的用户邮件地址并按用户名分组 |
| $unwind | 拆分操作符,用于将数组中的每一个值拆分为单独的文档。 |
| $sort | 排序操作符,用于根据一个或多个字段对文档进行排序。如db.users.aggregate([{ $sort : { age: 1 } }]);将用户按字段age升序排列。 |
| $limit | 限制操作符,用于限制返回文档的数量。 |
| $skip | 跳过操作符,用于跳过指定数量的文档。 |
| $lookup | 连接操作符,用于连接同一个数据库中另一个集合,并获取指定的文档,类似于populate。 |
| $count | 统计操作符,用于统计文档的数量。 |
| $sum | 对文档字段求和。 |
| $avg | 对文档字段进行平均值计算。 |
| $bucket | $bucket是MongoDB中的聚合操作符,它可以将文档根据指定的条件划分到不同的桶(bucket)中。$bucket接受以下参数:groupBy - 要进行分组的字段boundaries - 一个数组,定义每个桶的边界范围default - 默认的桶,不在boundaries范围内的文档会分到这个桶output - 定义每个桶返回的内容。一个示例用法如下:db.scores.aggregate([{$bucket: {groupBy: "$score",boundaries: [0, 50, 70, 90, 100], default: "Other",output: {"count": { $sum: 1 },"grades" : { $push: "$grade" }}}}])这个示例根据score字段将文档分到5个桶中,并统计每个桶中的文档数量以及文档的grade字段。 |
| $facet | $facet用于在聚合管道中执行多个聚合操作,并将各个管道的结果组合成一个文档返回。$facet的参数是一个文档,键是管道的名称,值是定义管道各个阶段的聚合操作符数组。例如:db.sales.aggregate([{$facet: {"topProducts": [{ $sortByCount: "$product" },{ $limit: 5 }],"avgPrice": [{ $group: { _id: null, avg: { $avg: "$price" } } } ] }}])这个示例使用$facet执行两个聚合管道:topProducts: 返回销量最高的5个商品avgPrice: 计算所有商品的平均价格$facet将两个管道的结果合并到一个文档中返回。 |
下面这部分文档引用自MongoDB 聚合初学者指南 可以下载pdf
这是如何构建聚合查询的示例:
db.*collectionName*.aggregate(*pipeline*, *options*),
- 其中 collectionName – 是集合的名称,
- pipeline – 是一个包含聚合阶段的数组,
- options – 聚合的可选参数
这是聚合管道语法的示例:
pipeline = [
{ $match : { … } },
{ $group : { … } },
{ $sort : { … } }
]
聚合在内存中进行。每个阶段最多可使用 100 MB RAM。如果超过此限制,您将从数据库收到错误。
如果它成为一个不可避免的问题,您可以选择分页到磁盘,唯一的缺点是您将等待更长的时间,因为在磁盘上工作比在内存中工作要慢。要选择页面到磁盘方法,您只需将选项 allowDiskUse 设置为 true,如下所示:
db.collectionName.aggregate(pipeline, { allowDiskUse : true })
请注意,此选项并不总是可用的共享服务。例如 Atlas M0、M2 和 M5 集群禁用此选项。聚合查询返回的文档(无论是作为游标还是通过 $out 存储在另一个集合中)的大小限制为 16MB。也就是说,它们不能大于 MongoDB 文档的最大大小。如果您可能会超出此限制,那么您应该指定聚合查询的输出将作为游标而不是文档。
数据库定义与设计
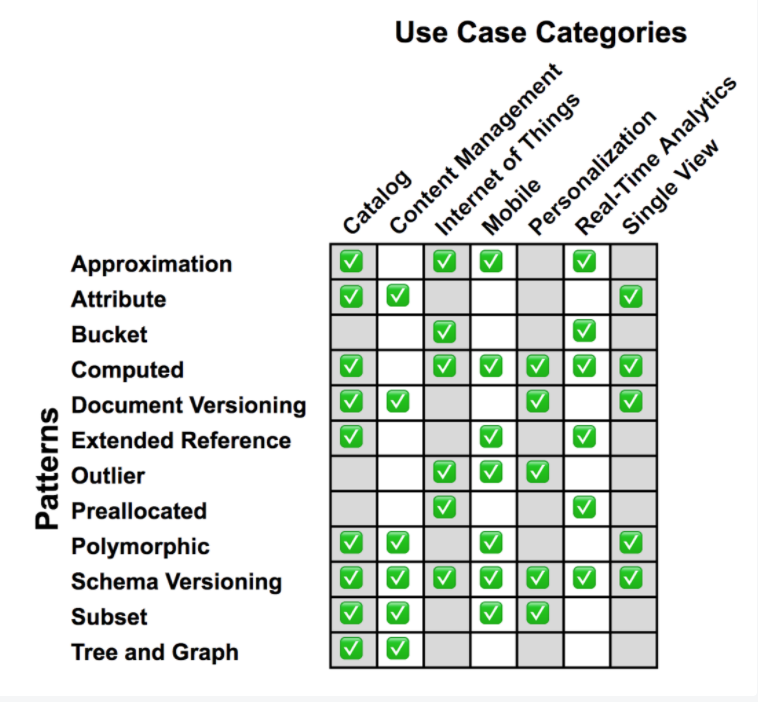
按官方博客的MongoDB设计模式,大致可分为下面几种(机翻整理)。
| 模式名 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| Approximation | 当频繁进行昂贵的计算并且这些计算的精度不是最高优先级时,近似模式很有用。 | 对数据库的写入更少。保持统计上有效的数字。 | 没有表示确切的数字。必须在应用程序中执行。 |
| Attribute | 属性模式对于基于具有许多相似字段的大型文档的问题很有用,但是有一个共享共同特征的字段子集,我们希望对该字段子集进行排序或查询。当我们需要排序的字段仅在一小部分文档中找到时。或者当文档中同时满足这两个条件时。 | 需要更少的索引。查询变得更容易编写并且通常更快。 | |
| Bucket | 当需要管理流数据时,桶模式是一个很好的解决方案,例如时间序列、实时分析或物联网 (IoT) 应用程序。 | 减少集合中的文档总数。提高索引性能。可以通过利用预聚合来简化数据访问。 | |
| Computed | 当存在读取密集型数据访问模式并且该数据需要由应用程序重复计算时,计算模式是一个很好的探索选择。 | 减少频繁计算的 CPU 工作量。查询变得更容易编写并且通常更快。 | 可能很难确定对这种模式的需求。除非需要,否则应避免应用或过度使用该模式。 |
| Document Versioning | 当您需要在 MongoDB 中维护以前版本的文档时,文档版本控制模式是一种可能的解决方案。 | 即使在现有系统上也易于实施。对最新版本的查询没有性能影响。 | 写入次数翻倍。查询需要针对正确的集合。 |
| Extended Reference | 当您的应用程序经历大量 JOIN 操作以汇集经常访问的数据时, 您会发现扩展引用模式最有用。 | 当有很多 JOIN 操作时提高性能。更快的读取和 JOIN 总数的减少。 | 数据重复。 |
| Outlier | 您是否发现有一些查询或文档不适合您的其他典型数据模式?这些例外是否在推动您的应用解决方案?如果是这样,异常值模式是解决这种情况的绝妙方法。 | 防止一些文档或查询确定应用程序的解决方案。查询是针对“典型”用例量身定制的,但仍会处理异常值。 | 通常为特定查询量身定制,因此临时查询可能表现不佳。这种模式的大部分是通过应用程序代码完成的。 |
| Pre-allocation | 当您知道您的文档结构并且您的应用程序只需要用数据填充它时,预分配模式是正确的选择。 | 事先知道文档结构时的设计简化。 | 简单性与性能。 |
| Polymorphic | 多态模式是当存在多种文档的相似性多于差异并且需要将文档保存在单个集合中时的解决方案。 | 易于实施。查询可以跨单个集合运行。 | |
| Schema Versioning | 几乎每个应用程序都可以从模式版本控制模式中受益,因为数据模式的更改经常发生在应用程序的生命周期中。此模式允许文档的先前版本和当前版本并排存在于集合中。 | 无需停机。控制模式迁移。减少未来的技术债务。 | 在迁移期间可能需要为同一字段创建两个索引。 |
| Subset | 子集模式解决了由于文档中的大部分数据未被应用程序使用而导致工作集超出 RAM 容量的问题。 | 减少工作集的整体大小。最常用数据的磁盘访问时间更短。 | 我们必须管理子集。提取额外数据需要额外访问数据库。 |
| Tree | 当数据具有层次结构并且经常被查询时,树模式是要实现的设计模式。 | 通过避免多次 JOIN 操作来提高性能。 | 需要在应用程序中管理对图形的更新。 |
近似模式Approximation
想象一个相当大的城市,大约有 39,000 人。随着人们进出城市、婴儿出生和人们死亡,确切的数字非常不稳定。我们可以花时间尝试每天获得准确数量的居民。但大多数时候,39,000 这个数字“足够好”。同样,在我们开发的许多应用程序中,知道一个“足够好”的数字就足够了。如果“足够好”的数字足够好,那么这是将近似模式应用于您的模式设计的绝佳机会。
近似模式
当我们需要显示具有挑战性或资源昂贵的计算(时间、内存、CPU 周期)来计算以及精度不是最高优先级时,我们可以使用*近似模式。*再想想人口问题。准确计算该数字的成本是多少?自从我开始计算以来,它会改变还是可能改变?如果报告为 39,000 而实际上是 39,012,对城市的规划战略有何影响?
从应用程序的角度来看,我们可以构建一个近似因子,这将允许更少的数据库写入,并且仍然提供统计上有效的数字。例如,假设我们的城市规划策略是基于每 10,000 人需要一辆消防车。100 人似乎是一个很好的规划“更新”期。“我们正在接近下一个门槛,更好地开始预算。”
然后在应用程序中,我们可以构建一个计数器,而不是每次更改都更新数据库中的人口,并且只更新 100 次,即 1% 的时间。我们的写入在这里显着减少,在这个例子中减少了 99%。另一种选择可能是有一个返回随机数的函数。例如,如果该函数返回一个从 0 到 100 的数字,那么它将在大约 1% 的时间内返回 0。当满足该条件时,我们将计数器增加 100。
我们为什么要关心这个?好吧,当处理大量数据或大量用户时,写入操作对性能的影响也会很大。你扩大的规模越大,影响也越大,而且在规模上,这通常是你最重要的考虑因素。通过减少写入并减少不需要“完美”的数据的资源,它可以带来性能的巨大改进。
示例用例
人口模式是近似模式的一个例子。我们可以使用此模式的另一个用例是网站视图。一般来说,知道是否有 700,000 人访问了该网站,还是 699,983 人并不重要。因此,我们可以在我们的应用程序中构建一个计数器,并在达到我们的阈值时在数据库中更新它。
这可能会极大地降低网站的性能。将时间和资源花在业务关键的数据写入上是有意义的。将它们全部花在页面计数器上似乎并不是对资源的充分利用。
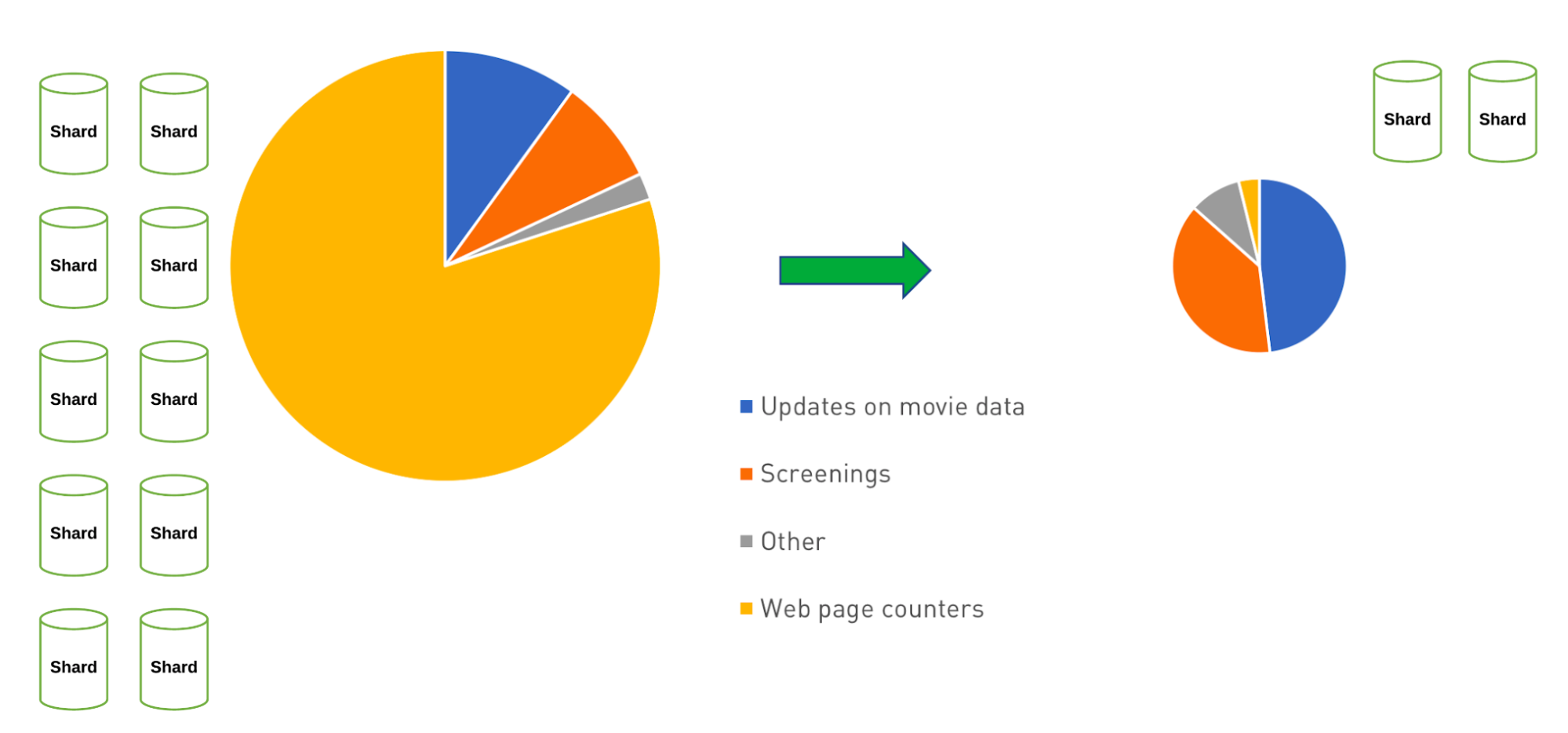
电影网站 - 减少写作工作量
在上图中,我们看到了如何使用近似模式并不仅减少计数器操作的写入,而且我们还可以看到通过减少这些写入来降低架构复杂性和成本。这可以进一步节省写入数据的时间。*与我们之前探讨的计算模式*类似,它不必频繁地运行计算,从而节省了整体 CPU 使用率。
结论
对于处理难以计算和/或计算成本高昂的数据并且这些数字的准确性不是关键任务的应用程序,*近似模式是一种出色的解决方案。*我们可以减少对数据库的写入,从而提高性能,并且仍然保持统计上有效的数字。然而,使用这种模式的代价是没有表示确切的数字,并且必须在应用程序本身中完成实现。
属性模式Attribute
属性模式特别适合以下情况:
- 我们有包含许多相似字段的大型文档,但是有一个具有共同特征的字段子集,我们希望对该字段子集进行排序或查询,或者
- 我们需要排序的字段只能在一小部分文档中找到,或者
- 上述两个条件都在文件中得到满足。
出于性能原因,为了优化我们的搜索,我们可能需要许多索引来解释所有子集。创建所有这些索引可能会降低性能。属性模式为这些情况提供了一个很好的解决方案。
属性模式
让我们考虑一下电影的集合。这些文档可能在所有文档中都涉及类似的字段:标题、导演、制片人、演员等。假设我们要搜索发布日期。这样做时我们面临的一个挑战是哪个发布日期?电影通常在不同国家的不同日期上映。
{
title: "Star Wars",
director: "George Lucas",
...
release_US: ISODate("1977-05-20T01:00:00+01:00"),
release_France: ISODate("1977-10-19T01:00:00+01:00"),
release_Italy: ISODate("1977-10-20T01:00:00+01:00"),
release_UK: ISODate("1977-12-27T01:00:00+01:00"),
...
}
搜索发布日期需要同时查看多个字段。为了快速搜索上映日期,我们的电影收藏需要几个索引:
{release_US: 1}
{release_France: 1}
{release_Italy: 1}
...
通过使用属性模式,我们可以将这个信息子集移动到一个数组中并减少索引需求。我们将此信息转换为键值对数组:
{
title: "Star Wars",
director: "George Lucas",
…
releases: [
{
location: "USA",
date: ISODate("1977-05-20T01:00:00+01:00")
},
{
location: "France",
date: ISODate("1977-10-19T01:00:00+01:00")
},
{
location: "Italy",
date: ISODate("1977-10-20T01:00:00+01:00")
},
{
location: "UK",
date: ISODate("1977-12-27T01:00:00+01:00")
},
…
],
…
}
通过在数组中的元素上创建一个索引,索引变得更易于管理:
{ "releases.location": 1, "releases.date": 1}
通过使用属性模式,我们可以为我们的文档添加组织以获取常见特征并解释稀有/不可预测的字段。例如,在新的或小型的电影节上上映的电影。此外,转向键/值约定允许使用非确定性命名和轻松添加限定符。例如,如果我们的数据收集是关于瓶装水,我们的属性可能类似于:
"specs": [
{ k: "volume", v: "500", u: "ml" },
{ k: "volume", v: "12", u: "ounces" }
]
在这里,我们将信息分解为键和值,“k”和“v”,并添加第三个字段“u”,它允许单独存储度量单位。
{"specks.k": 1, "specs.v": 1, "specs.u": 1}
示例用例
属性模式非常适合具有相同值类型的字段集的模式,例如日期列表。在处理产品特性时,它也能很好地工作。某些产品(例如服装)的尺寸可能以小号、中号或大号表示。同一集合中的其他产品可能以数量表示。还有一些可以用物理尺寸或重量来表示。
资产管理领域的一位客户最近使用属性模式部署了他们的解决方案。客户使用该模式来存储给定资产的所有特征。这些特征在资产中很少常见,或者在设计时很难预测。关系模型通常使用复杂的设计过程以用户定义字段的形式表达相同的想法。
虽然产品目录中的许多字段相似,例如名称、供应商、制造商、原产国等,但项目的规格或属性可能不同。如果您的应用程序和数据访问模式依赖于同时搜索许多不同的字段,则属性模式为数据提供了良好的结构。
结论
属性模式提供了更轻松的文档索引,针对每个文档的许多相似字段。通过将这个数据子集移动到一个键值子文档中,我们可以使用非确定性的字段名称,为信息添加额外的限定符,更清楚地说明原始字段和值的关系。当我们使用属性模式时,我们需要更少的索引,我们的查询变得更容易编写,我们的查询变得更快。
桶模式 Bucket
这种模式在处理物联网 (IoT)、实时分析或一般时间序列数据时特别有效。通过将数据分组在一起,我们可以更轻松地组织特定的数据组,提高发现历史趋势或提供未来预测的能力,并优化我们对存储的使用。
桶模式
随着一段时间内的数据流(时间序列数据)进入,我们可能倾向于将每个测量值存储在自己的文档中。然而,这种倾向是处理数据的一种非常相关的方法。如果我们有一个传感器每分钟测量一次温度并将其保存到数据库中,我们的数据流可能类似于:
{
sensor_id: 12345,
timestamp: ISODate("2019-01-31T10:00:00.000Z"),
temperature: 40
}
{
sensor_id: 12345,
timestamp: ISODate("2019-01-31T10:01:00.000Z"),
temperature: 40
}
{
sensor_id: 12345,
timestamp: ISODate("2019-01-31T10:02:00.000Z"),
temperature: 41
}
随着我们的应用程序在数据和索引大小方面的扩展,这可能会带来一些问题。例如,我们最终可能不得不为每一个单独的测量建立索引sensor_id,timestamp以便以 RAM 为代价实现快速访问。但是,通过利用文档数据模型,我们可以按时间将这些数据“存储”到包含特定时间跨度的测量值的文档中。我们还可以以编程方式向这些“桶”中的每一个添加附加信息。
通过将桶模式应用于我们的数据模型,我们在节省索引大小、潜在的查询简化以及在文档中使用预聚合数据的能力方面获得了一些好处。从上面获取数据流并将 Bucket Pattern 应用到它,我们最终会得到:
{
sensor_id: 12345,
start_date: ISODate("2019-01-31T10:00:00.000Z"),
end_date: ISODate("2019-01-31T10:59:59.000Z"),
measurements: [
{
timestamp: ISODate("2019-01-31T10:00:00.000Z"),
temperature: 40
},
{
timestamp: ISODate("2019-01-31T10:01:00.000Z"),
temperature: 40
},
…
{
timestamp: ISODate("2019-01-31T10:42:00.000Z"),
temperature: 42
}
],
transaction_count: 42,
sum_temperature: 2413
}
通过使用存储桶模式,我们将数据“存储”到了一个一小时的存储桶中。这个特定的数据流仍然会增长,因为它目前只有 42 个测量值;该小时还有更多测量值要添加到“存储桶”中。当它们被添加到measurements数组中时,transaction_count将增加并且sum_temperature也将被更新。
使用预先汇总的sum_temperature值,就可以轻松地拉起特定的桶并确定该桶的平均温度 ( sum_temperature / transaction_count)。在处理时间序列数据时,了解 2018 年 7 月 13 日加利福尼亚州康宁市下午 2:00 至下午 3:00 的平均温度通常比了解下午 2:03 的温度更有趣和重要。通过分桶和进行预聚合,我们能够更轻松地提供该信息。
此外,随着我们收集越来越多的信息,我们可能会确定将所有源数据保存在存档中会更有效。例如,我们需要多久获取一次康宁 1948 年以来的温度?能够将这些数据桶移动到数据存档中可能是一个很大的好处。
示例用例
使时间序列数据在现实世界中有价值的一个例子来自博世的物联网实施。他们在汽车现场数据应用程序中使用 MongoDB 和时间序列数据。该应用程序从整个车辆的各种传感器捕获数据,从而改进对车辆本身和组件性能的诊断。
其他示例包括已将这种模式纳入金融应用程序以将交易组合在一起的主要银行。
结论
在处理时间序列数据时,在 MongoDB 中使用 Bucket Pattern 是一个不错的选择。它减少了集合中的文档总数,提高了索引性能,并且通过利用预聚合,它可以简化数据访问。
计算模式Computed
*我们已经研究了在“使用模式构建”*系列中优化存储数据的各种方法。现在,我们将研究模式设计的不同方面。通常,仅存储数据并使其可用并不是那么有用。当我们可以从中计算值时,数据的有用性变得更加明显。最新的亚马逊 Alexa 的总销售收入是多少?有多少观众观看了最新的大片?这些类型的问题可以从存储在数据库中的数据中回答,但必须进行计算。
每次请求时都运行这些计算成为一个高度资源密集型的过程,尤其是在巨大的数据集上。CPU 周期、磁盘访问、内存都可能涉及。
想一想电影信息 Web 应用程序。每次我们访问该应用程序查找电影时,该页面都会提供有关该电影已播放的电影院数量、观看该电影的总人数以及总收入的信息。如果应用程序必须为每次页面访问不断计算这些值,它可能会在流行电影上使用大量处理资源
然而,大多数时候,我们不需要知道这些确切的数字。我们可以在后台进行计算并偶尔更新主电影信息文档。然后,这些计算使我们能够显示数据的有效表示,而无需在 CPU 上付出额外的努力。
计算模式
当我们有需要在应用程序中重复计算的数据时,就会使用计算模式。当数据访问模式是读取密集型时,也会使用计算模式。例如,如果您每小时有 1,000,000 次读取,但每小时只有 1,000 次写入,则在写入时进行计算会将计算次数除以 1000。
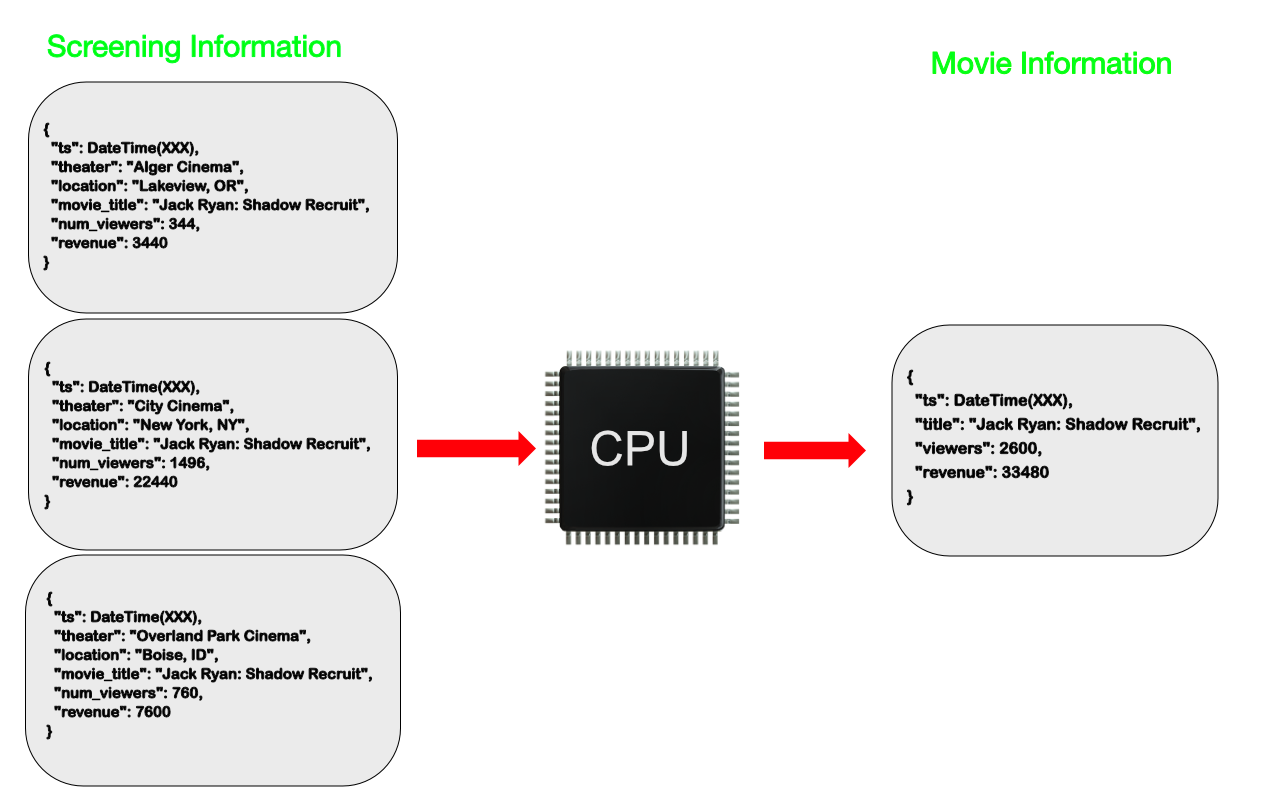
在我们的电影数据库示例中,我们可以根据我们对特定电影的所有放映信息进行计算,计算结果,并将它们与电影本身的信息一起存储。在低写入环境中,可以结合源数据的任何更新来完成计算。在有更多定期写入的情况下,可以按定义的时间间隔进行计算 - 例如每小时。由于我们不会干扰筛选信息中的源数据,因此我们可以在任何时间点继续重新运行现有计算或运行新计算,并且知道我们会得到正确的结果。
执行计算的其他策略可能涉及,例如,向文档添加时间戳以指示其上次更新时间。然后应用程序可以确定何时需要进行计算。另一种选择可能是有一个需要完成的计算队列。选择更新策略最好留给应用程序开发人员。
示例用例
计算模式可用于需要对数据进行计算的任何地方。需要总和的数据集(例如收入或观众)就是一个很好的例子,但时间序列数据、产品目录、单一视图应用程序和事件溯源也是这种模式的主要候选者。
这是许多客户已经实施的模式。例如,客户对车辆数据进行大量聚合查询,并将结果存储给服务器以显示接下来几个小时的信息。
一家出版公司编译所有类型的数据以创建像“100 Best …”这样的有序列表。这些列表只需要偶尔重新生成一次,而基础数据可能会在其他时间更新。
结论
这种强大的设计模式可以减少 CPU 工作量并提高应用程序性能。它可用于对集合中的数据进行计算或操作,并将结果存储在文档中。这允许避免重复进行相同的计算。每当您的系统重复执行相同的计算并且您具有较高的读写比率时,请考虑Computed Pattern。
文档版本控制模式 Document Versioning
数据库,如 MongoDB,非常擅长查询大量数据并经常更新这些数据。然而,在大多数情况下,我们只对数据的最新状态执行查询。我们需要查询数据的先前状态的情况呢?如果我们需要对文档进行版本控制怎么办?这是我们可以使用文档版本控制模式的地方。
这种模式是关于保持文档的版本历史可用和可用。我们可以构建一个系统,将专用版本控制系统与 MongoDB 结合使用。一个系统用于少数更改的文档,而 MongoDB 用于其他文档。这可能会很麻烦。然而,通过使用文档版本控制模式,我们能够避免使用多个系统来管理当前文档及其历史记录,方法是将它们保存在一个数据库中。
文档版本控制模式
这种模式解决了希望在 MongoDB 中保留某些文档的旧版本而不是引入第二个管理系统的问题。为此,我们向每个文档添加一个字段,以便我们跟踪文档版本。然后数据库将有两个集合:一个包含最新(和查询最多的数据),另一个包含所有数据的修订。
文档版本控制模式对数据库中的数据和应用程序所做的数据访问模式做了一些假设。
- 每个文档没有太多的修订。
- 没有太多要版本的文档。
- 执行的大多数查询都是在文档的最新版本上完成的。
如果您发现这些假设不适合您的用例,则此模式可能不太适合。您可能需要更改实现文档版本控制模式版本的方式,或者您的用例可能只需要不同的解决方案。
示例用例
文档版本控制模式在需要一组数据的特定时间点版本的高度监管行业中非常有用。金融和医疗保健行业就是很好的例子。保险和法律行业是其他一些行业。有许多用例可以跟踪数据的某些部分的历史记录。
想想保险公司如何利用这种模式。每个客户都有一个“标准”保单和一个特定于该客户的第二部分,如果你愿意的话,一个保单附加条款。第二部分将包含一份保单附加项列表和一份正在投保的特定项目列表。随着客户更改投保的特定项目,需要更新此信息,同时还需要提供历史信息。这在房主或租房者保险单中相当普遍。例如,如果某人有超出所提供的典型承保范围的特定项目,他们将作为附加险单独列出。保险公司的另一个用例可能是保留他们随时间邮寄给客户的“标准保单”的所有版本。
如果我们看一下文档版本控制模式的要求,这似乎是一个很好的用例。保险公司可能有几百万客户,对“附加”列表的修改可能不会太频繁,并且大多数对保单的搜索将是最新版本。
在我们的数据库中,每个客户可能都有一个current_policy文档——包含客户特定信息——在一个current_policies集合中,policy_revision文档在一个policy_revisions集合中。此外,standard_policy对于大多数客户来说,会有一个相同的集合。当客户购买新项目并希望将其添加到他们的保单中时,policy_revision会使用该文档创建一个新current_policy文档。然后增加文档中的版本字段以将其标识为最新修订并添加客户的更改。

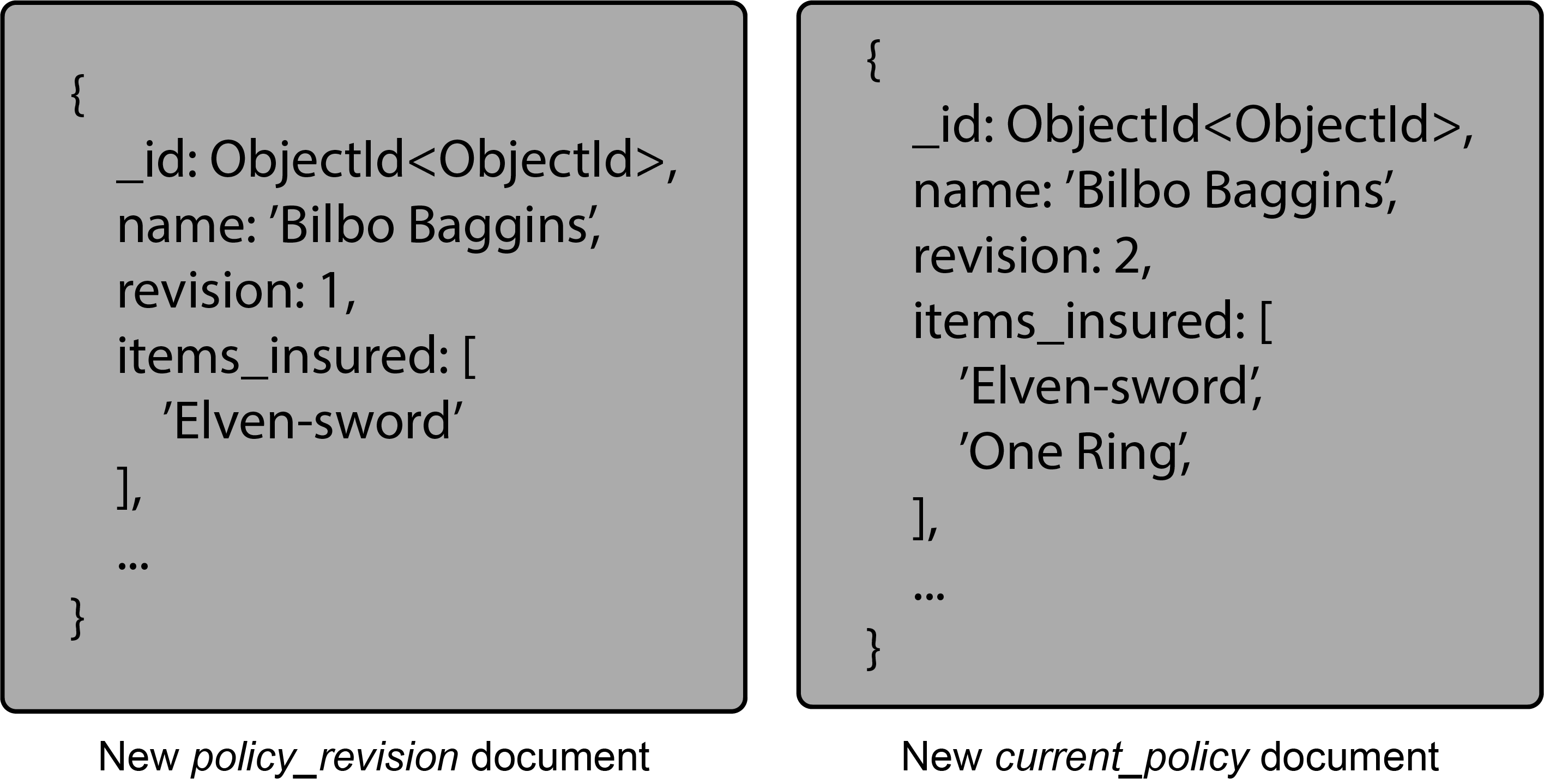
最新版本将存储在current_policies集合中,旧版本将写入policy_revisions集合。current_policy通过在集合中保留最新版本,查询可以保持简单。该policy_revisions集合也可能只保留几个版本,具体取决于数据需求和要求。

在这个例子中, Middle-earth Insurance将standard_policy为其客户提供一个。The Shire的所有居民都将分享这份特定的政策文件。Bilbo 在他的正常保险范围之外还有一些他想要投保的特定事项。他的精灵之剑,最终,一环被添加到他的政策中。这些将驻留在current_policies集合中,并且在进行更改时,policy_revisions集合将保留更改的历史记录。
文档版本控制模式相对容易实现。它可以在现有系统上实现,而无需对应用程序或现有文档进行太多更改。此外,访问文档最新版本的查询仍然有效。
这种模式的一个缺点是需要访问不同的历史信息集合。另一个事实是,对数据库的总体写入量会更高。这就是为什么使用此模式的要求之一是它发生在不太频繁更改的数据上。
结论
当您需要跟踪对文档的更改时,文档版本控制模式是一个不错的选择。它相对容易实现,并且可以应用于现有的文档集。另一个好处是对最新版本数据的查询仍然表现良好。但是,它不会取代专用的版本控制系统。
扩展引用模式 Extended Reference
在整个使用模式构建系列中,我希望您已经发现,模式应该是什么样子的驱动力是该数据的数据访问模式是什么。如果我们有许多类似的字段,属性模式可能是一个不错的选择。容纳对一小部分数据的访问是否会极大地改变我们的应用程序?也许异常值模式是需要考虑的。一些模式,例如Subset Pattern,引用额外的集合并依靠 JOIN 操作将每条数据重新组合在一起。当需要大量 JOIN 操作来汇集经常访问的数据时,实例会怎样呢?这是我们可以使用扩展参考模式的地方。
扩展引用模式
有时单独收集数据是有意义的。如果一个实体可以被认为是一个单独的“事物”,那么拥有一个单独的集合通常是有意义的。例如,在电子商务应用程序中,存在订单、客户和库存的概念。它们是独立的逻辑实体。

然而,从性能的角度来看,这会成为问题,因为我们需要将信息片段放在一起以实现特定的顺序。一个客户可以有 N 个订单,形成 1-N 关系。从订单的角度来看,如果我们反过来看,他们与客户的关系是 N-1。为每个订单嵌入有关客户的所有信息只是为了减少 JOIN 操作会导致大量重复信息。此外,订单可能不需要所有客户信息。
扩展参考模式提供了一种处理这些情况的好方法。我们不会复制客户的所有信息,而是只复制我们经常访问的字段。我们没有嵌入所有信息或包含对 JOIN 信息的引用,而是仅嵌入那些具有最高优先级和最常访问的字段,例如姓名和地址。

使用这种模式时要考虑的一点是数据是重复的。因此,如果存储在主文档中的数据是不经常更改的字段,则效果最好。像 user_id 和人名这样的东西是不错的选择。这些很少改变。
此外,仅引入并复制所需的数据。想想订单发票。如果我们在发票上注明客户的姓名,我们是否需要他们当时的辅助电话号码和非送货地址?可能不会,因此我们可以将该数据从invoice集合中删除并引用一个customer集合。
当信息更新时,我们也需要考虑如何处理。哪些扩展引用发生了变化?这些应该什么时候更新?如果信息是帐单地址,我们是否需要出于历史目的维护该地址,还是可以更新?有时重复数据会更好,因为您可以保留历史值,这可能更有意义。我们运送产品时客户居住的地址在订单文档中更有意义,然后通过客户集合获取当前地址。
示例用例
订单管理应用程序是这种模式的经典用例。在考虑 N-1 关系、向客户下订单时,我们希望减少信息的加入以提高绩效。通过包含对最常连接的数据的简单引用,我们节省了处理步骤。
如果我们继续以订单管理系统为例,在发票上 Acme Co. 可能被列为铁砧供应商。从发票的角度来看,拥有 Acme Co. 的联系信息可能并不是很重要。例如,该信息最好存放在单独的supplier集合中。在invoice集合中,我们会保留有关供应商的所需信息,作为对供应商信息的扩展参考。
结论
当您的应用程序经历许多重复的 JOIN 操作时,扩展引用模式是一个很好的解决方案。通过在查找端识别字段并将那些经常访问的字段带入主文档,可以提高性能。这是通过更快的读取和减少 JOIN 的总数来实现的。但是请注意,数据重复是这种模式设计模式的副作用。
异常值模式Outlier
到目前为止,在使用模式构建系列中,我们已经了解了Polymorphic、Attribute和Bucket模式。虽然这些模式中的文档模式略有不同,但从应用程序和查询的角度来看,文档结构是相当一致的。但是,如果不是这种情况,会发生什么?当存在超出“正常”模式的数据时会发生什么?如果有异常值怎么办?
想象一下,您正在创建一个销售书籍的电子商务网站。您可能有兴趣运行的查询之一是“谁购买了特定的书”。这对于推荐系统向您的客户展示您感兴趣的类似书籍可能很有用。您决定user_id为每本书存储一个客户的数组。很简单,对吧?
好吧,这可能确实适用于 99.99% 的案例,但是当 JK 罗琳发布新的《哈利波特》书籍并且销量飙升数百万时会发生什么?很容易达到16MB BSON 文档大小的限制。针对这种异常情况重新设计我们的整个应用程序可能会导致典型书籍的性能降低,但我们确实需要考虑到这一点。
异常值模式
使用离群值模式,我们正在努力防止一些查询或文档将我们的解决方案推向一种对于我们的大多数用例而言并非最佳的解决方案。并非每本书售出都会售出数百万册。
存储信息的典型book文档user_id可能类似于:
{
"_id": ObjectID("507f1f77bcf86cd799439011")
"title": "A Genealogical Record of a Line of Alger",
"author": "Ken W. Alger",
…,
"customers_purchased": ["user00", "user01", "user02"]
}
这对于大多数不太可能进入“畅销书”列表的书籍非常有效。考虑异常值虽然会导致customers_purchased数组扩展超出我们设置的 1000 项限制,但我们将添加一个新字段以将图书“标记”为异常值。
{
"_id": ObjectID("507f191e810c19729de860ea"),
"title": "Harry Potter, the Next Chapter",
"author": "J.K. Rowling",
…,
"customers_purchased": ["user00", "user01", "user02", …, "user999"],
"has_extras": "true"
}
然后,我们会将溢出信息移动到与本书链接的单独文档中id。在应用程序内部,我们将能够确定文档是否具有has_extras值为 的字段true。如果是这种情况,应用程序将检索额外信息。这可以被处理,以便它对大多数应用程序代码来说是相当透明的。
许多设计决策将基于应用程序工作负载,因此此解决方案旨在展示异常值模式的示例。这里要掌握的重要概念是,异常值在其数据中具有足够大的差异,如果将它们视为“正常”,则为它们更改应用程序设计会降低更典型查询和文档的性能。
示例用例
异常值模式是一种高级模式,但它可以带来很大的性能改进。它经常用于受欢迎程度是一个因素的情况,例如社交网络关系、图书销售、电影评论等。互联网已经把我们的世界变成了一个小得多的地方,当某件事变得流行时,它改变了我们需要的方式对项目周围的数据进行建模。
一个示例是拥有视频会议产品的客户。大多数视频会议中的授权与会者列表可以保存在与会议相同的文档中。然而,有一些活动,比如公司的全体员工,预计会有成千上万的参与者。对于那些异常会议,客户实施了“溢出”文档来记录那些长长的与会者名单。
结论
异常值模式解决的问题是阻止一些文档或查询来确定应用程序的解决方案。尤其是当该解决方案对于大多数用例而言不是最佳的时。我们可以利用 MongoDB 灵活的数据模型向文档中添加一个字段,将其“标记”为异常值。然后,在应用程序内部,我们处理异常值的方式略有不同。通过为典型文档或查询定制架构,应用程序性能将针对这些正常用例进行优化,异常值仍将得到解决。
这种模式需要考虑的一件事是,它通常是为特定的查询和情况量身定制的。因此,即席查询可能会导致性能不佳。此外,由于大部分工作是在应用程序代码本身内完成的,因此随着时间的推移可能需要额外的代码维护。
预分配模式 Preallocation
MongoDB 的一大优点是文档数据模型。它不仅在模式设计中而且在开发周期中都提供了很大的灵活性。不知道以后需要哪些字段,使用 MongoDB 文档可以轻松处理。然而,有时结构是已知的并且能够填充或增长结构使得设计更加简单。这是我们可以使用预分配模式的地方。
内存分配通常在块中完成以避免性能问题。在 MongoDB 的早期(MongoDB 3.2 版之前),当它使用MMAPv1存储引擎时,一个常见的优化是提前分配不断增长的文档未来大小所需的内存。MMAPv1 中不断增长的文档需要由服务器以相当昂贵的成本重新定位。凭借其无锁和重写更新算法,WiredTiger不需要同样的处理。
随着 MongoDB 4.0 中 MMAPv1 的弃用,预分配模式似乎失去了一些光彩和必要性。然而,WiredTiger 的预分配模式仍有一些用例。与我们在使用模式构建系列中讨论的其他模式一样,需要考虑一些应用程序注意事项。
预分配模式
这种模式只是要求创建一个初始的空结构以供以后填充。这可能听起来微不足道,但是,您需要在简化的预期结果与解决方案可能消耗的额外资源之间取得平衡。更大的文档将产生更大的工作集,从而导致更多的 RAM 来包含该工作集。
如果应用程序的代码使用未完全填充的结构更容易编写和维护,那么它可能很容易超过 RAM 的成本。假设需要将一个剧院房间表示为一个二维数组,其中每个座位都有一个“行”和“编号”,例如座位“C7”。有些行可能有更少的座位,但是在二维数组中找到座位“B3”比在只有现有座位的单元格的一维数组中找到座位的复杂公式更快、更清晰。能够识别无障碍座位也更容易,因为可以为这些座位创建单独的阵列。
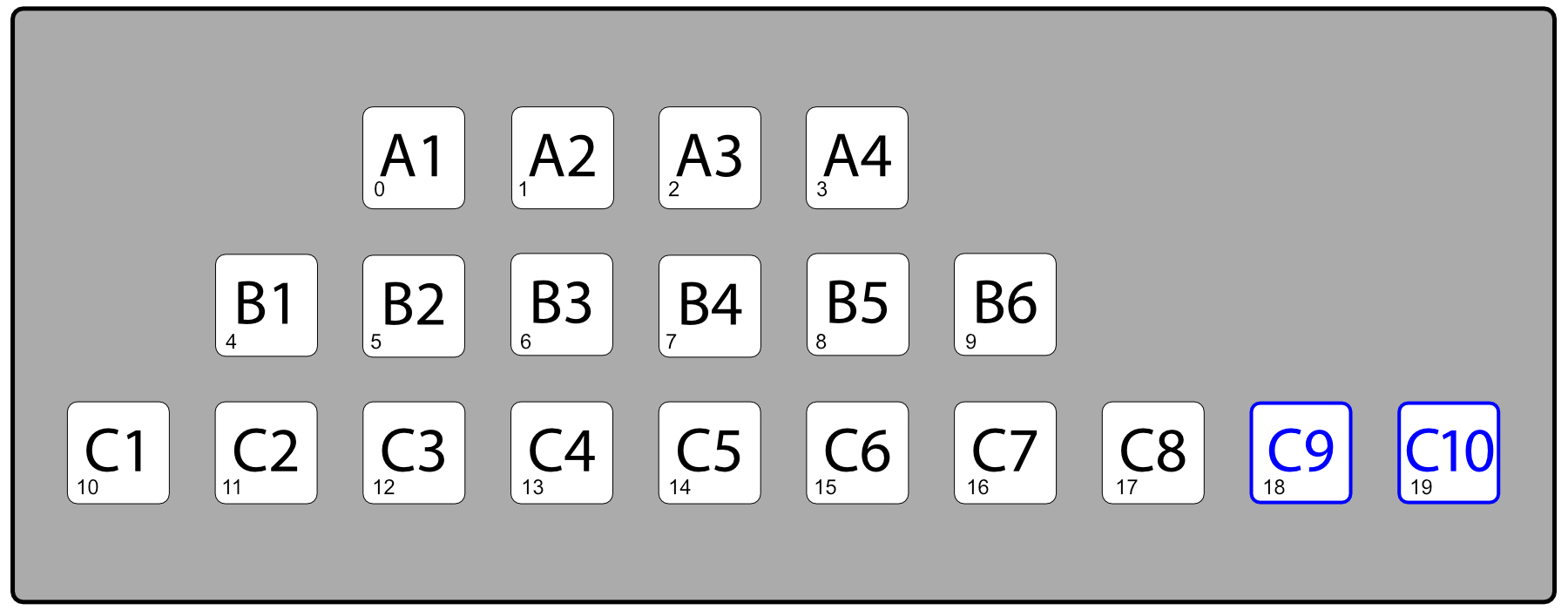
场地的一维表示,可访问的座位以蓝色显示。

场地的二维表示,可用绿色的有效座位。带有蓝色轮廓的无障碍座位。
示例用例
如前所述,表示二维结构(如场地)是一个很好的用例。另一个示例可以是预留系统,其中资源每天被阻止或预留。每天使用一个单元格可能会比保留范围列表更快地进行计算和检查。

2019 年 4 月,有一系列美国工作日。
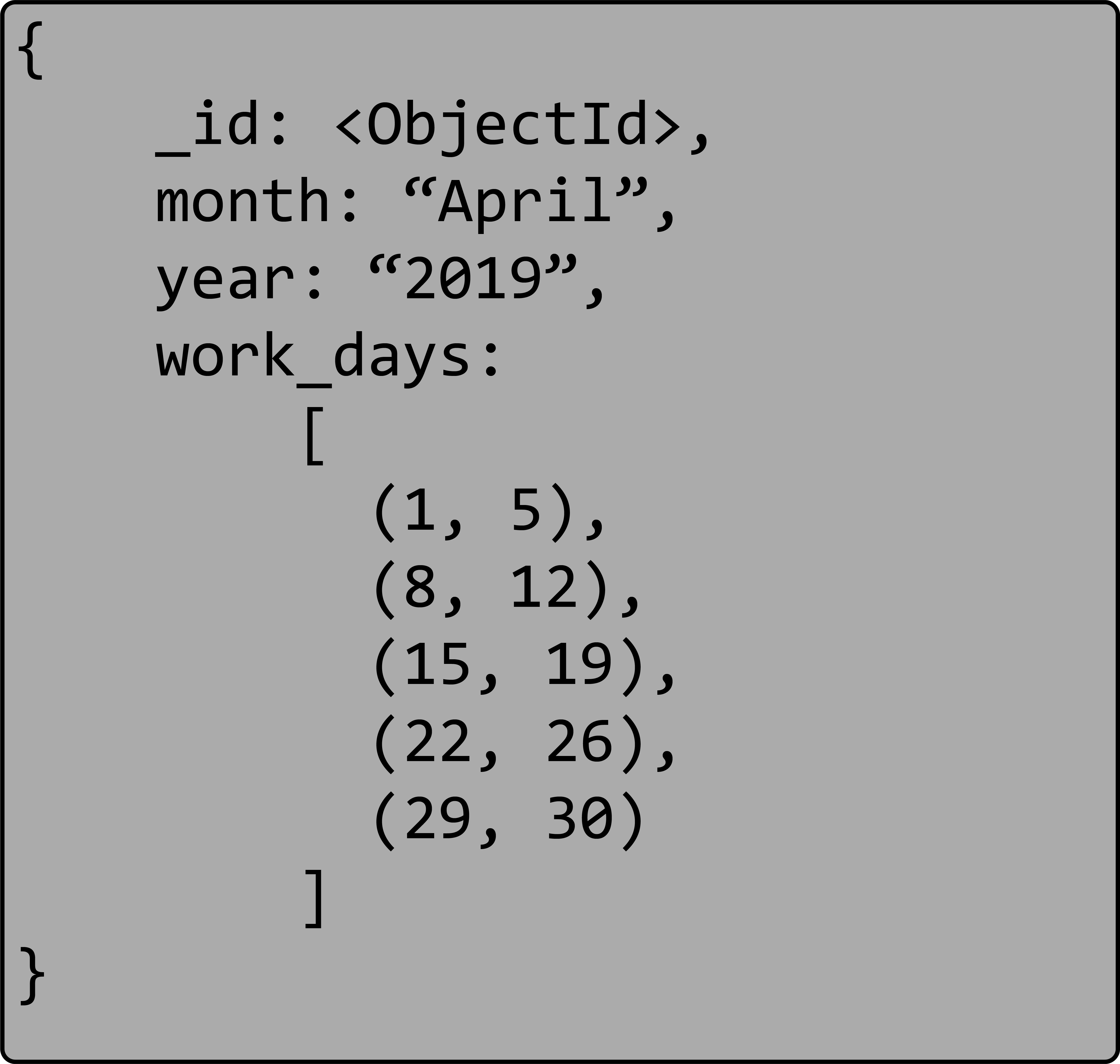
2019 年 4 月,包含一系列美国工作日作为范围列表。
结论
在将 MMAPv1 存储引擎与 MongoDB 一起使用时,这种模式可能是最常用的模式之一。然而,由于这个存储引擎的弃用,它已经失去了它的通用用例,但它在某些情况下仍然有用。和其他模式一样,您需要在“简单性”和“性能”之间进行权衡。
多态模式 polymorphic
当我们的文档相似性多于差异性时,就会使用此模式。当我们想要将文档保存在单个集合中时,它也非常适合。
多态模式
当集合中的所有文档具有相似但不相同的结构时,我们称之为多态模式。如前所述,当我们想要从单个集合访问(查询)信息时,多态模式很有用。根据我们想要运行的查询将文档分组在一起(而不是跨表或集合分离对象)有助于提高性能。
想象一下,我们的应用程序跟踪所有不同运动的职业运动员。
我们仍然希望能够访问我们应用程序中的所有运动员,但是每个运动员的属性非常不同。这就是多态模式大放异彩的地方。在下面的示例中,我们将来自两个不同运动的运动员的数据存储在同一个集合中。即使文档在同一个集合中,存储的关于每个运动员的数据也不必相同。

职业运动员的记录有一些相似之处,但也有一些差异。使用多态模式,我们很容易适应这些差异。如果我们不使用多态模式,我们可能会有保龄球运动员的集合和网球运动员的集合。当我们想要查询所有运动员时,我们需要进行耗时且可能复杂的连接。相反,由于我们使用的是多态模式,所以我们所有的数据都存储在一个运动员集合中,并且可以通过一个简单的查询来完成对所有运动员的查询。
这种设计模式也可以流入嵌入的子文档。在上面的例子中,玛蒂娜·纳芙拉蒂洛娃不只是作为一个球员参加比赛,所以我们可能希望将她的记录构造如下:

从应用程序开发的角度来看,当使用多态模式时,我们将查看文档或子文档中的特定字段,以便能够跟踪差异。例如,我们知道网球运动员可能会参与不同的赛事,而不同的运动员可能不会。这通常需要根据给定文档中的信息在应用程序代码中使用不同的代码路径。或者,可能会编写不同的类或子类来处理网球、保龄球、足球和橄榄球运动员之间的差异。
示例用例
多态模式的一个示例用例是单一视图应用程序. 想象一下为一家公司工作,随着时间的推移,该公司利用他们的技术和数据模式收购了其他公司。例如,每家公司都有许多数据库,每个数据库都以不同的方式模拟“与客户的保险”。然后,您购买了这些公司,并希望将所有这些系统集成为一个。将这些不同的系统合并到一个统一的 SQL 模式中既费钱又费时。
大都会人寿能够利用 MongoDB 和多态模式在几个月内构建他们的单视图应用程序。他们的 Single View 应用程序将来自多个来源的数据聚合到一个中央存储库中,使客户服务、保险代理、计费和其他部门能够获得 360 度的客户图片。这使他们能够以更低的成本为公司提供更好的客户服务。此外,使用 MongoDB 的灵活数据模型和多态模式,开发团队能够快速创新,将他们的产品上线。
单视图应用程序是多态模式的一个用例。它也适用于自行车与钓鱼竿具有不同属性的产品目录等内容。我们的运动员示例可以很容易地扩展为更成熟的内容管理系统,并在那里使用多态模式。
结论
当文档的相似性多于差异性时,使用多态模式。这种模式设计的典型用例是:
- 单一视图应用程序
- 内容管理
- 移动应用
- 产品目录
多态模式提供了一种易于实现的设计,允许跨单个集合进行查询,并且是我们将在接下来的文章中探索的许多设计模式的起点。
模式版本控制模式 Schema Versioning
有人说,生活中唯一不变的就是变化。这也适用于数据库模式。我们曾经认为不需要的信息,现在我们想要捕获。或者新服务变得可用并且需要包含在数据库记录中。不管更改背后的原因是什么,一段时间后,我们不可避免地需要对应用程序中的底层架构设计进行更改。虽然这通常会带来挑战,并且在遗留表格数据库系统中可能至少会带来一些令人头疼的问题,但在 MongoDB 中,我们可以使用模式版本控制模式来简化更改。
如前所述,更新表格数据库中的数据库模式可能具有挑战性。通常需要停止应用程序,迁移数据库以支持新模式,然后重新启动。这种停机时间可能会导致糟糕的客户体验。此外,如果迁移没有完全成功,会发生什么?恢复到之前的状态通常是一个更大的挑战。
Schema Versioning 模式利用了 MongoDB 对不同形状文档的支持以存在于同一数据库集合中。MongoDB 的这种多态性非常强大。它允许具有不同字段甚至同一字段的不同字段类型的文档和平共存。
模式版本控制模式
这种模式的实现相对容易。我们的应用程序从最终需要更改的原始模式开始。发生这种情况时,我们可以使用字段创建新模式并将其保存到数据库schema_version中。该字段将允许我们的应用程序知道如何处理此特定文档。或者,我们可以让我们的应用程序根据某些给定字段的存在与否来推断版本,但前一种方法是首选。我们可以假设没有这个字段的文档是版本 1。然后每个新的模式版本都会增加schema_version字段值,并且可以在应用程序中进行相应的处理。
随着新信息的保存,我们使用最新的模式版本。我们可以根据应用程序和用例来确定是否需要将所有文档更新为新设计、何时更新记录被访问或根本不更新。在应用程序内部,我们将为每个模式版本创建处理函数。
示例用例
如前所述,几乎每个数据库都需要在其生命周期的某个时间点进行更改,因此这种模式在许多情况下都很有用。让我们看一下客户资料用例。在有多种联系方式之前,我们就开始保留客户信息。他们只能在家里或工作中联系到:
{
"_id": "<ObjectId>",
"name": "Anakin Skywalker",
"home": "503-555-0000",
"work": "503-555-0010"
}
随着岁月的流逝,越来越多的客户记录被保存,我们注意到手机号码也需要保存。添加该字段是直截了当的。
{
"_id": "<ObjectId>",
"name": "Darth Vader",
"home": "503-555-0100",
"work": "503-555-0110",
"mobile": "503-555-0120"
}
随着时间的流逝,现在我们发现拥有家庭电话的人越来越少,而其他联系方式也变得越来越重要。Twitter、Skype 和 Google Hangouts 等项目正变得越来越流行,甚至可能在我们刚开始保留联系信息时都不可用。我们还想尽可能地尝试对我们的应用程序进行未来验证,并且在阅读了使用模式构建系列之后,我们了解了属性模式并将其实现为一contact_method组值。为此,我们创建了一个新的模式版本。
{
"_id": "<ObjectId>",
"schema_version": "2",
"name": "Anakin Skywalker (Retired)",
"contact_method": [
{ "work": "503-555-0210" },
{ "mobile": "503-555-0220" },
{ "twitter": "@anakinskywalker" },
{ "skype": "AlwaysWithYou" }
]
}
MongoDB 文档模型的灵活性允许所有这些都发生,而无需数据库停机。从应用程序的角度来看,它可以设计为读取模式的两个版本。假设涉及的应用程序服务器不止一个,那么如何处理架构差异的这种应用程序更改也不应该需要停机时间。
结论
Schema Versioning 模式非常适用于无法选择应用程序停机时间、更新文档可能需要数小时、数天或数周时间才能完成、不需要将文档更新到新版本或任意组合的情况。这些。它允许schema_version轻松添加新字段并使应用程序适应这些变化。此外,它为我们作为开发人员提供了更好地决定何时以及如何进行数据迁移的机会。所有这些都会减少未来的技术债务,这是这种模式的另一大优势。
与本系列中提到的其他模式一样,Schema Versioning 模式也需要考虑一些事项。如果您在文档中不在同一级别的字段上有索引,则在迁移文档时可能需要 2 个索引。
这种模式的主要好处之一是数据模型本身的简单性。所需要的只是添加该schema_version字段。然后允许应用程序处理和处理不同的文档版本。
此外,正如在用例示例中所见,我们能够将模式设计模式组合在一起以获得额外的性能。在这种情况下,同时使用模式版本控制和属性模式。允许在不停机的情况下进行模式升级使得模式版本控制模式在 MongoDB 中特别强大,并且很可能有足够的理由为您的下一个应用程序使用 MongoDB 的文档模型而不是旧的表格数据库。
子集模式 Subset
几年前,第一台 PC 拥有高达 256KB 的 RAM 和双 5.25" 软盘驱动器。没有硬盘驱动器,因为它们当时非常昂贵。这些限制导致由于工作时内存不足而不得不物理交换软盘有大量(当时)数据。如果当时只有一种方法可以只将我经常使用的数据带入内存,就像整体数据的一个子集一样。
现代应用程序无法避免耗尽资源。MongoDB 将经常访问的数据(称为工作集)保存在 RAM 中。当数据和索引的工作集增长到超出分配的物理 RAM 时,性能会随着磁盘访问开始发生并且数据从 RAM 中滚出而降低。
我们如何解决这个问题?首先,我们可以向服务器添加更多 RAM。不过,这只规模很大。我们可以考虑对我们的集合进行分片,但这会带来额外的成本和复杂性,我们的应用程序可能还没有准备好。另一种选择是减小我们工作集的大小。这是我们可以利用子集模式的地方。
子集模式
此模式解决了与超出 RAM 的工作集相关的问题,从而导致信息从内存中删除。这通常是由具有大量应用程序实际未使用的数据的大型文档引起的。我到底是什么意思?
想象一个有一个产品评论列表的电子商务网站。在访问该产品的数据时,我们很可能只需要最近十条左右的评论。使用所有评论提取整个产品数据很容易导致工作集扩展。

我们可以将集合分成两个集合,而不是将所有评论与产品一起存储。一个集合包含最常用的数据,例如当前评论,而另一个集合包含不常用的数据,例如旧评论、产品历史等。我们可以复制部分 1-N 或 NN 关系,该关系由关系中最常用的一面。

在产品集合中,我们只会保留最近的 10 条评论。这允许通过仅引入整体数据的一部分或子集来减少工作集。附加信息(本例中的评论)存储在单独的评论集合中,如果用户想要查看其他评论,可以访问该集合。在考虑在哪里拆分数据时,文档中最常用的部分应该进入“主”集合,而不太常用的数据应该进入另一个集合。对于我们的评论,该拆分可能是产品页面上可见的评论数量。
示例用例
当我们在文档中有大量很少需要的数据时,子集模式非常有用。产品评论、文章评论、电影中的演员都是这种模式的用例示例。每当文档大小对工作集的大小施加压力并导致工作集超出计算机的 RAM 容量时,子集模式是一个可以考虑的选项。
结论
通过使用具有更频繁访问数据的较小文档,我们减小了工作集的整体大小。这允许对应用程序需要的最常用信息进行更短的磁盘访问时间。使用子集模式时我们必须做出的一个权衡是我们必须管理子集,而且如果我们需要提取较旧的评论或所有信息,则需要额外访问数据库才能这样做。
树模式 Tree
到目前为止,我们介绍的许多模式设计模式都强调节省 JOIN 操作的时间是一个好处。一起访问的数据应该存储在一起,并且一些数据重复是可以的。像扩展参考这样的模式设计模式就是一个很好的例子。但是,如果要连接的数据是分层的怎么办?例如,您想确定从员工到 CEO 的报告链?MongoDB 提供了$graphLookup操作符来以图表的形式导航数据,这可能是一种解决方案。但是,如果您需要对这种分层数据结构进行大量查询,您可能希望应用相同的规则将一起访问的数据存储在一起。这是我们可以使用树模式的地方。
树模式
有许多方法可以表示旧表格数据库中的树。最常见的是图中的节点列出其父节点和节点列出其子节点。这两种表示都可能需要多次访问来构建节点链。
具有父节点的公司结构
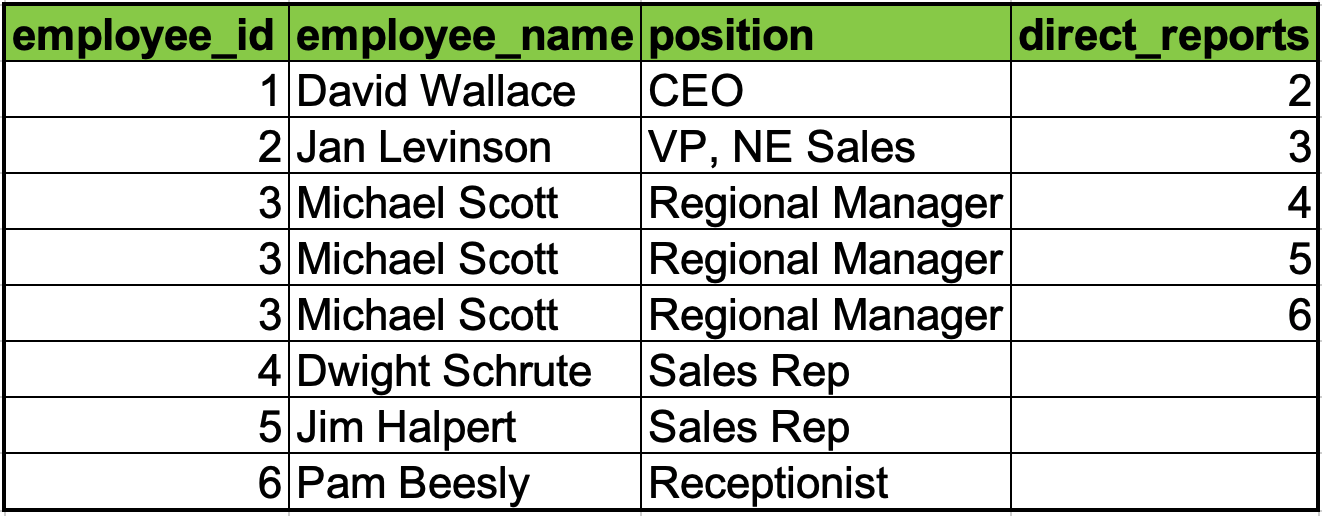
具有子节点的公司结构
或者,我们可以存储从节点到层次结构顶部的完整路径。在这种情况下,我们基本上会为每个节点存储“父母”。在表格数据库中,它可能通过对父母列表进行编码来完成。MongoDB 中的方法是将其简单地表示为一个数组。

从这里可以看出,在这个表示中有一些数据重复。如果信息是相对静态的,比如家谱,你的父母和祖先不会改变,使这个数组易于管理。但是,在我们的公司结构示例中,当事情发生变化并进行重组时,您将需要根据需要更新层次结构。与不一直计算树所获得的好处相比,这仍然是一个很小的成本。
示例用例
产品目录是使用树模式的另一个很好的例子。产品通常属于类别,而类别又是其他类别的一部分。例如,固态驱动器可能在Hard Drives下,在Storage下,在Computer Parts下。有时,类别的组织可能会发生变化,但不会太频繁。
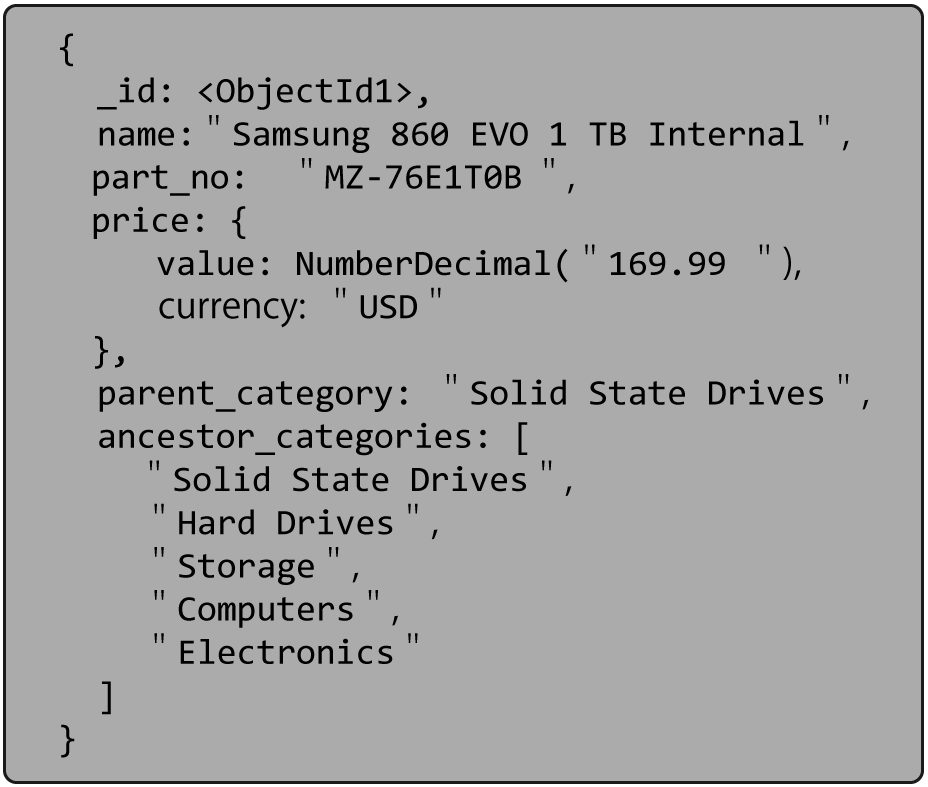
请注意文档上方ancestor_categories跟踪整个层次结构的字段。我们也有领域parent_category。在这两个字段中复制直接父级是我们在与许多使用树模式的客户合作后开发的最佳实践。包含“父”字段通常很方便,特别是如果您需要保持在文档上使用 $graphLookup 的能力。
将祖先保留在数组中提供了在这些值上创建多键索引的能力。它允许轻松找到给定类别的所有后代。至于直系子女,可以通过查看将我们给定类别作为其直系“父母”的文档来访问它们。我们刚刚告诉过你,这个字段会很方便。
结论
对于许多模式,在使用它们时通常需要在简单性和性能之间进行权衡。在树模式的情况下,您可以通过避免多个连接来获得更好的性能,但是,您需要管理对图形的更新。
备份和还原
使用官方工具
假设我们有一台正在运行的远程 MongoDB 计算机,并且希望在本地计算机上创建该数据库的快照,则可以在主节点上使用 mongodump 命令来完成此操作。我们只需要指明远程服务器的主机和端口号(默认为端口 27017),并提供一些参数,例如数据库名称、用户名和密码。最后,我们指定要在其中创建快照的转储目录。
mongodump -h sample.mongodbhost.com:27017 -d DATABASE_NAME -u USER_NAME -p SAMPLE_PASSWORD -o ~/Desktop
备份大型数据库的最佳实践之一是将它们分开。您可以使用 --query 参数将查询传递到 mongodump,以便在发生故障时能够使用集合中的某种时间戳/排序字段来恢复备份过程。为了使用保存的快照恢复数据库,我们只需使用 mongorestore 命令。它通过直接连接到正在运行的 mongod 来恢复数据。您可以使用 --quiet 选项在安静模式下运行还原来限制数据库的输出。我们再次提供 MongoDB 主机和端口,以及用户名、数据库名称和密码。最后,我们提供输出目录。
mongorestore --host sample.mongohost.com --port 27017 --username USER_NAME --password SAMPLE_PASSWORD --db DATABASE_NAME .
以上是基本的操作,同时还有其他的备份还原选项以适应不同的场景需求,参考本文后面的链接。mongodump可以使用--archive参数来将备份数据输出到标准输出中,只有我们就可以通过下面一行的命令完成数据库的备份和还原操作了。
ssh [email protected] mongodump --host source.server.com \
--archive --gzip | ssh [email protected] mongorestore --archive --gzip
脚本工具
一个有用的脚本 delta-sync.sh,该脚本使用oplog来优化同步体验,在备份过程中的操作数据也会被备份并还原到对应的数据库。
#!/bin/bash
# DB info
old_db="source_database_name"
# Connection info
uri="source_db_connection_string"
to_uri="target_db_connection_string"
# Storage info
now=$(date +"%Y-%m-%dT%TZ")
root_dir="$(pwd)/cron"
lock_file="${root_dir}/sync.lock"
sync_log="${root_dir}/sync.log"
out_dir="${root_dir}/dump"
sync_dir="${out_dir}/${now}"
# Create files and directories
mkdir -p $sync_dir
touch $sync_log
# Log info -- pwd refers to the user home directory
from=$1
last_sync_time=$(tail -n 1 $sync_log)
if [[ $from == "" ]]; then
if [[ $last_sync_time == "" ]]; then
echo "FATAL: From time is not specified. Updating the log registry with current timestamp and exiting!"
echo $(date +"%Y-%m-%dT%TZ") >>$sync_log
exit 1
else
from=$last_sync_time
fi
fi
to=$2
if [[ $to == "" ]]; then to=$(date +"%Y-%m-%dT%TZ"); fi
# Setup
if [[ -f $lock_file ]]; then
echo "FATAL: A sync is already in progress for timestamp ${last_sync_time}. Exiting!"
exit 1
fi
# Create Mutex
touch $lock_file
echo $to >>$sync_log
echo "INFO: Updated log registry to use new timestamp on next run."
# Ops
mkdir -p $sync_dir
echo "INFO: Created sync directory: ${sync_dir}"
echo "Fetching oplog in range [${from} - ${to}]"
query="{\"wall\": {\"\$gte\": {\"\$date\": \"$from\"}, \"\$lte\": {\"\$date\": \"$to\"} }, \"ns\": {\"\$regex\": \"$old_db\"}}"
echo $query >"${root_dir}/query.json"
if $(mongodump --uri=$uri --collection \"oplog.rs\" --queryFile "${root_dir}/query.json" --gzip -v --out=$sync_dir); then
echo "INFO: Dump success!"
echo "INFO: Replaying oplogs..."
if $(mongorestore --uri=$to_uri --oplogReplay --noIndexRestore --gzip -vv $sync_dir); then
echo "INFO: Restore success!"
else
rm -rf $sync_dir
sed -i '$ d' $sync_log
fi
else
rm -rf $sync_dir
sed -i '$ d' $sync_log
echo "ERROR: Dump failed!"
fi
# Clear Mutex
rm $lock_file
使用方式
./delta-sync.sh from_epoch_in_milliseconds
或者您可以设置一个 cron 作业每分钟运行一次。* * * * * ~/delta-sync.sh
然后以下命令监视输出
tail -f /var/log/cron | grep CRON
使用 Percona Backup for MongoDB
参考 https://docs.percona.com/percona-backup-mongodb/