本文使用AI自动翻译,原文仓库地址
用直观和简单的术语解释复杂的系统。
无论您是在准备系统设计面试,还是只是想了解系统在表面之下是如何工作的,我们都希望本资料库能帮助您实现这一目标。
通信协议
架构风格定义了应用程序编程接口(API)不同组件之间的交互方式。因此,它们通过提供设计和构建 API 的标准方法,确保了效率、可靠性以及与其他系统集成的便捷性。以下是最常用的样式:
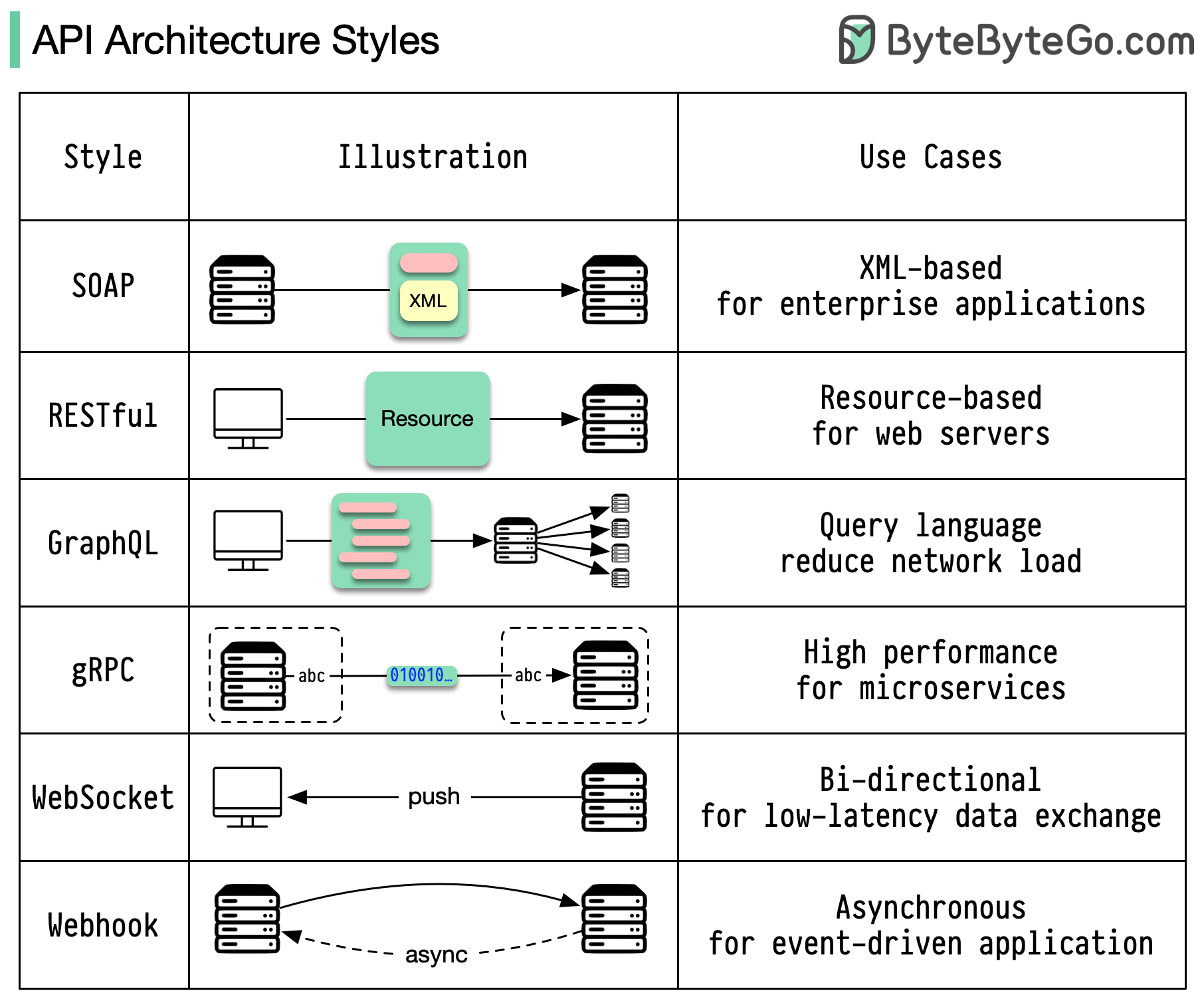
- SOAP:
成熟、全面、基于 XML
最适合企业应用
- RESTful:
流行、易于实施的 HTTP 方法
网络服务的理想选择
- GraphQL:
查询语言,请求特定数据
减少网络开销,加快响应速度
- gRPC:
现代化、高性能的协议缓冲器
适合微服务架构
- WebSocket:
实时、双向、持久连接
非常适合低延迟数据交换
- Webhook
事件驱动、HTTP 回调、异步
事件发生时通知系统
REST API 与 GraphQL
在应用程序接口设计方面,REST 和 GraphQL 各有优缺点。
下图显示了 REST 和 GraphQL 的快速比较。
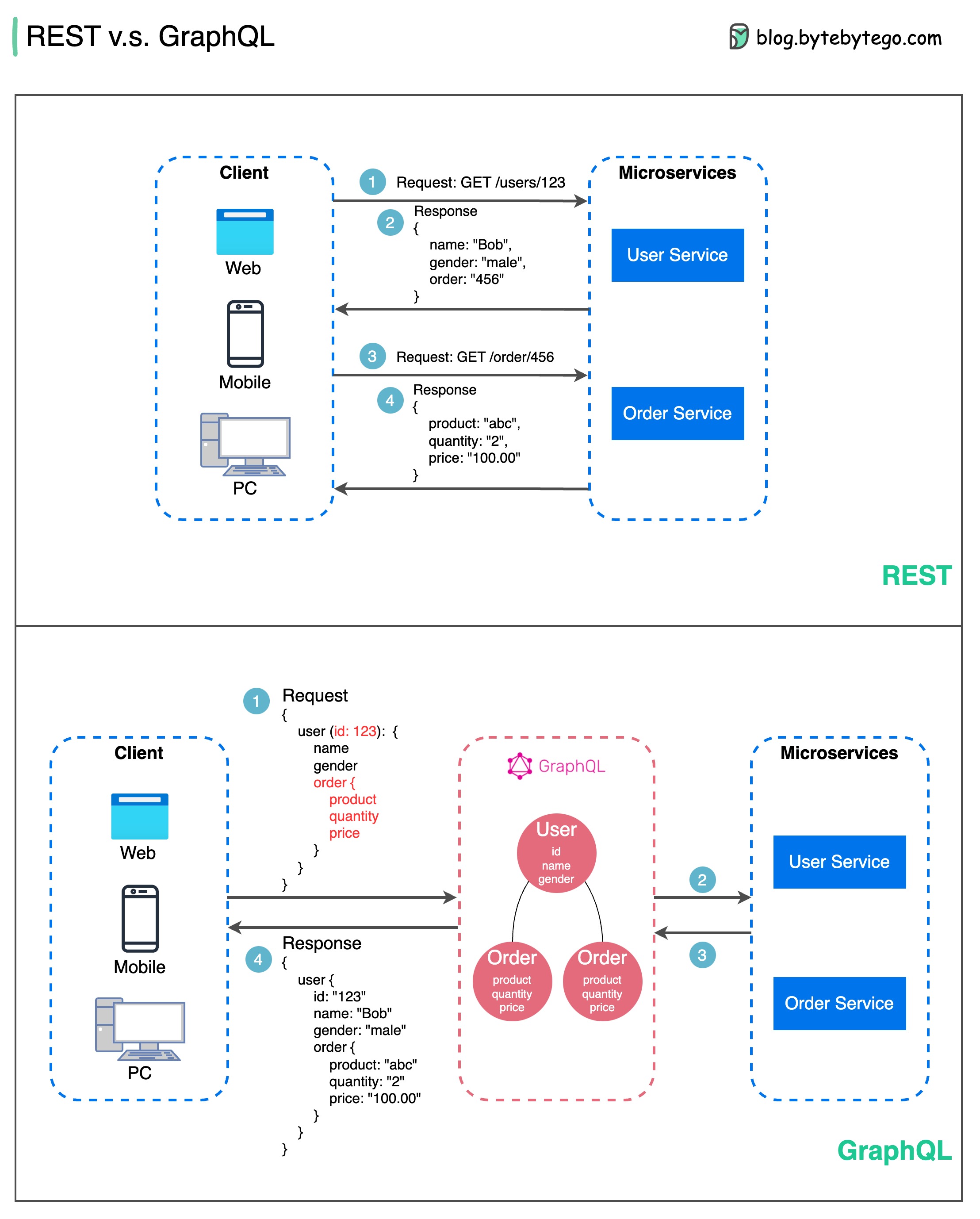
REST
- 使用 GET、POST、PUT、DELETE 等标准 HTTP 方法进行 CRUD 操作。
- 当你需要在不同的服务/应用程序之间建立简单、统一的接口时,它就能很好地发挥作用。
- 缓存策略可以直接实施。
- 缺点是可能需要多次往返,从不同的端点收集相关数据。
GraphQL
- 为客户提供单个端点,以便准确查询所需数据。
- 客户端在嵌套查询中指定所需的确切字段,服务器只返回包含这些字段的优化有效载荷。
- 支持用于修改数据的突变和用于实时通知的订阅。
- 非常适合聚合多个来源的数据,并能很好地满足快速发展的前端需求。
- 不过,它将复杂性转移到了客户端,如果没有适当的保护措施,可能会允许滥用查询
- 缓存策略可能比 REST 更加复杂。
REST 和 GraphQL 之间的最佳选择取决于应用程序和开发团队的具体要求。GraphQL 非常适合复杂或频繁变化的前端需求,而 REST 则适合需要简单一致的合同的应用。
API 方法都不是万能的。仔细评估需求和权衡利弊对于选择正确的风格非常重要。REST 和 GraphQL 都是公开数据和支持现代应用程序的有效选择。
gRPC 如何工作?
RPC(远程过程调用)之所以被称为 “远程”,是因为在微服务架构下,当服务部署到不同的服务器时,它可以实现远程服务之间的通信。从用户的角度来看,它就像一个本地函数调用。
下图说明了 gRPC 的整体数据流。
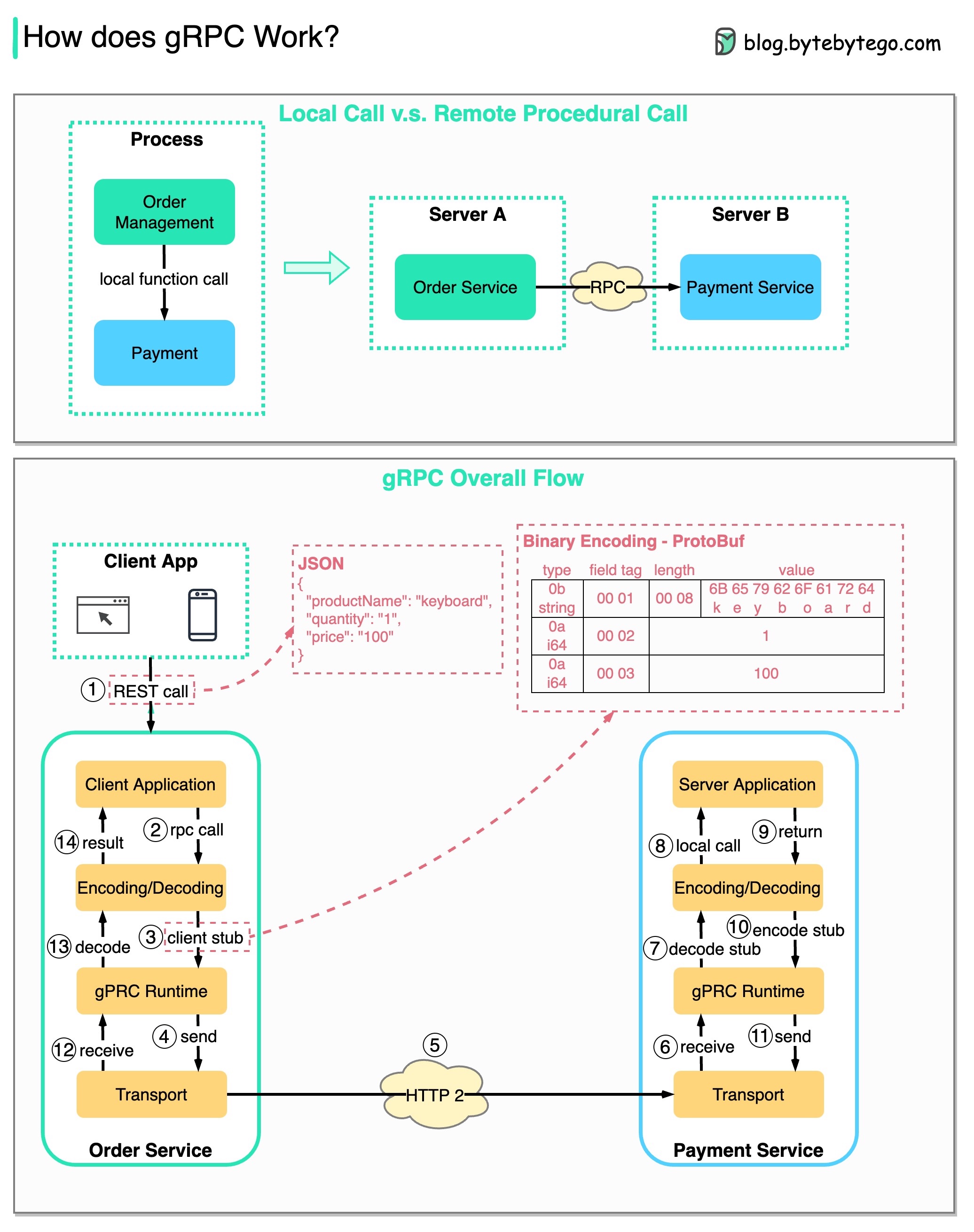
步骤 1:从客户端发出 REST 调用。请求体通常为 JSON 格式。
步骤 2 - 4:订单服务(gRPC 客户端)接收 REST 调用,对其进行转换,然后向支付服务发出 RPC 调用。
第五步:gRPC 通过 HTTP2 在网络上发送数据包。由于采用了二进制编码和网络优化,gRPC 据说比 JSON 快 5 倍。
步骤 6 - 8:支付服务(gRPC 服务器)接收来自网络的数据包,解码后调用服务器应用程序。
步骤 9 - 11:结果从服务器应用程序返回,经过编码后发送到传输层。
步骤 12 - 14:订单服务接收数据包、解码并将结果发送给客户端应用程序。
什么是Webhook?
下图显示了轮询和 Webhook 的比较。
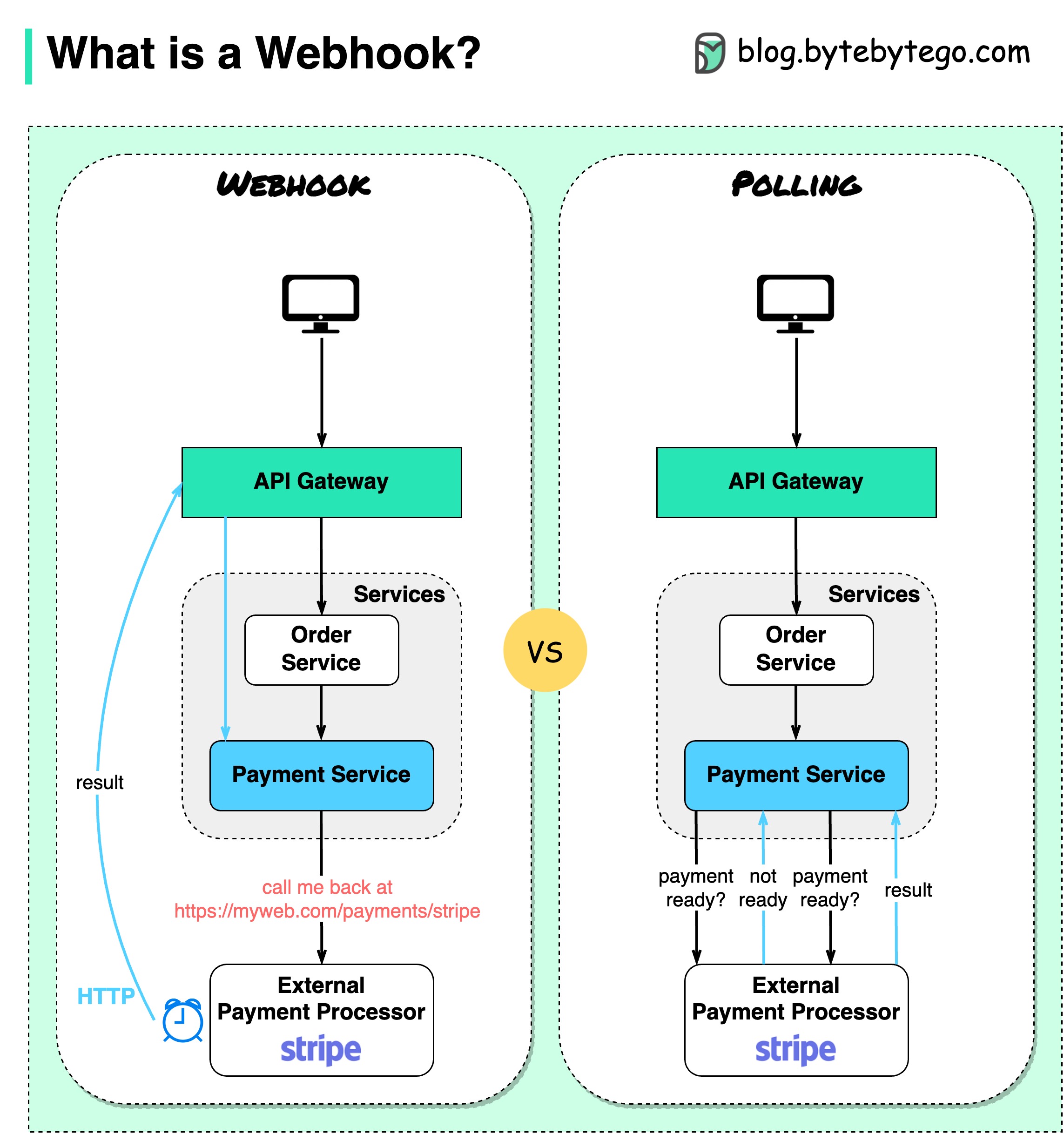
假设我们运行一个电子商务网站。客户通过 API 网关向订单服务发送订单,订单服务转到支付服务进行支付交易。然后,支付服务与外部支付服务提供商(PSP)对话以完成交易。
有两种方法可以处理与外部 PSP 的通信。
**1.轮询(Polling)
向 PSP 发送支付请求后,支付服务会不断询问 PSP 的支付状态。几轮之后,PSP 最终会返回付款状态。
简而言之,轮询有两个缺点:
- 不断轮询状态需要支付服务的资源。
- 外部服务直接与支付服务通信,会造成安全漏洞。
2.Webhook
我们可以向外部服务注册网络钩子。这意味着:当您有关于请求的最新信息时,请在某个 URL 上给我回电。PSP 完成处理后,将调用 HTTP 请求更新付款状态。
这样,编程模式就发生了变化,支付服务就不再需要浪费资源来轮询支付状态了。
如果 PSP 一直不回电话怎么办?我们可以设置一个管家任务,每小时检查一次付款状态。
Webhook 通常被称为反向 API 或推送 API,因为服务器会向客户端发送 HTTP 请求。使用网络钩子时,我们需要注意以下三点:
- 我们需要设计一个适当的应用程序接口,供外部服务调用。
- 出于安全考虑,我们需要在 API 网关中设置适当的规则。
- 我们需要在外部服务中注册正确的 URL。
如何提高应用程序接口的性能?
下图显示了提高应用程序接口性能的 5 种常见技巧。
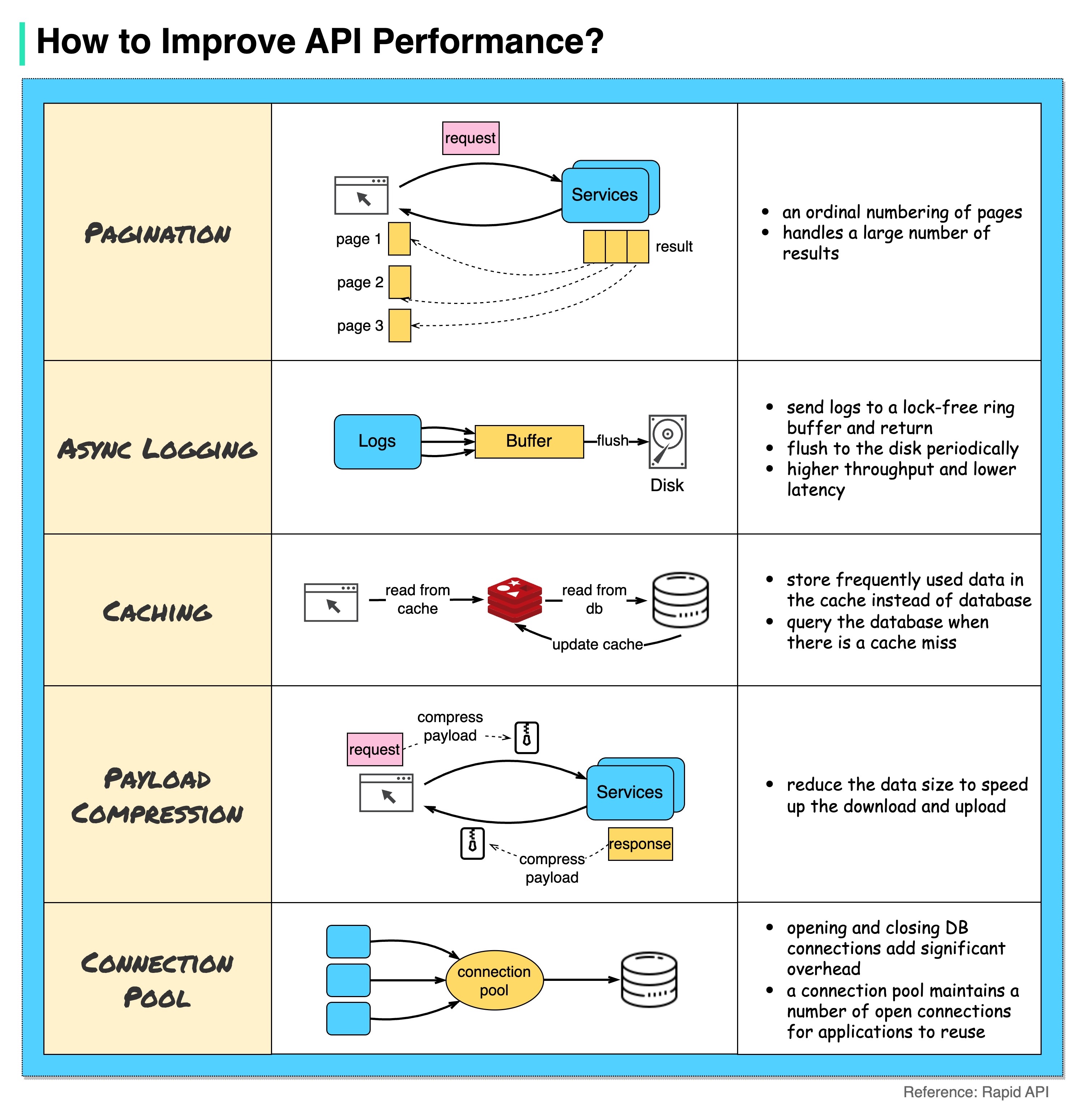
分页
当结果较大时,这是一种常见的优化方法。结果会以流式方式传回客户端,以提高服务响应速度。
异步日志记录
同步日志记录每次调用都要处理磁盘,会降低系统运行速度。异步日志记录会先将日志发送到无锁缓冲区,然后立即返回。日志会定期刷新到磁盘。这大大减少了 I/O 开销。
缓存
我们可以将经常访问的数据缓存到缓存中。客户端可以先查询缓存,而不是直接访问数据库。如果出现缓存缺失,客户端可以从数据库中查询。Redis 等缓存将数据存储在内存中,因此数据访问速度比数据库快得多。
有效载荷压缩
可以使用 gzip 等对请求和响应进行压缩,从而大大缩小传输数据的大小。这样可以加快上传和下载速度。
连接池
访问资源时,我们经常需要从数据库加载数据。打开和关闭数据库连接会增加大量开销。因此,我们应该通过一个开放连接池来连接数据库。连接池负责管理连接的生命周期。
HTTP 1.0 -> HTTP 1.1 -> HTTP 2.0 -> HTTP 3.0 (QUIC)
每一代 HTTP 解决了什么问题?
下图说明了主要特征。

-
1996 年,HTTP 1.0 最终定稿并形成完整文档。对同一服务器的每个请求都需要单独的 TCP 连接。
-
HTTP 1.1 于 1997 年发布。TCP 连接可以保持开放以便重复使用(持久连接),但这并不能解决 HOL(行首)阻塞问题。
HOL 阻塞–当浏览器允许的并行请求数用完时,后续请求需要等待前一个请求完成。
-
HTTP 2.0 于 2015 年发布。它通过请求多路复用解决了 HOL 问题,消除了应用层的 HOL 阻塞,但传输(TCP)层仍存在 HOL。
如图所示,HTTP 2.0 引入了 HTTP “流 “的概念:这是一种抽象概念,允许在同一 TCP 连接上复用不同的 HTTP 交换。每个流无需按顺序发送。
-
HTTP 3.0 第一稿于 2020 年发布。它是 HTTP 2.0 的拟议后续版本。它使用 QUIC 代替 TCP 作为底层传输协议,从而消除了传输层中的 HOL 阻塞。
QUIC 基于 UDP。它将数据流作为一等公民引入传输层。QUIC 流共享同一个 QUIC 连接,因此无需额外的握手和慢速启动来创建新的 QUIC 流,但 QUIC 流是独立传输的,因此在大多数情况下,影响一个流的数据包丢失不会影响其他流。
SOAP vs REST vs GraphQL vs RPC
下图说明了 API 时间轴和 API 样式的比较。
随着时间的推移,不同的应用程序接口架构风格相继问世。它们都有自己的数据交换标准化模式。
您可以在图中查看每种样式的用例。

代码优先与应用程序接口优先
下图显示了代码优先开发和 API 优先开发之间的区别。为什么要考虑 API 优先设计?
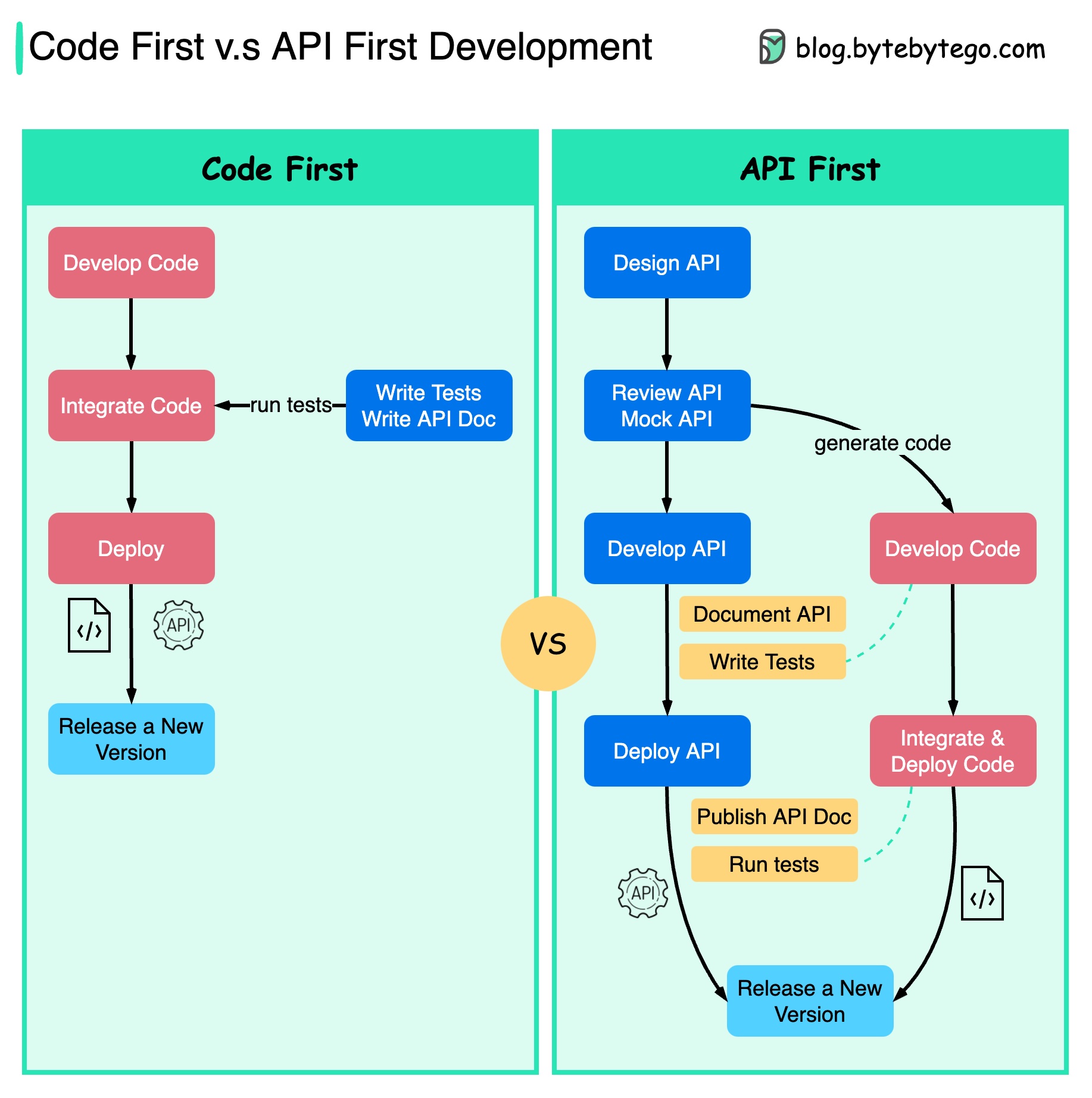
- 微服务增加了系统的复杂性,我们需要单独的服务来服务于系统的不同功能。虽然这种架构有利于解耦和职责分离,但我们需要处理服务之间的各种通信。
在编写代码和仔细定义服务边界之前,最好先考虑清楚系统的复杂性。
- 不同的职能团队需要使用同一种语言,而专门的职能团队只负责自己的组件和服务。建议组织通过应用程序接口设计使用同一种语言。
我们可以模拟请求和响应,以便在编写代码前验证应用程序接口的设计。
- 提高软件质量和开发人员的工作效率 由于我们在项目开始时就消除了大部分不确定因素,因此整个开发过程会更加顺利,软件质量也会大大提高。
开发人员对这一过程也很满意,因为他们可以专注于功能开发,而不是商讨突然的变化。
减少了项目生命周期末期出现意外的可能性。
因为我们先设计了应用程序接口,所以可以在开发代码的同时设计测试。在某种程度上,使用 API 优先开发时,我们还可以进行 TDD(测试驱动设计)。
HTTP 状态代码
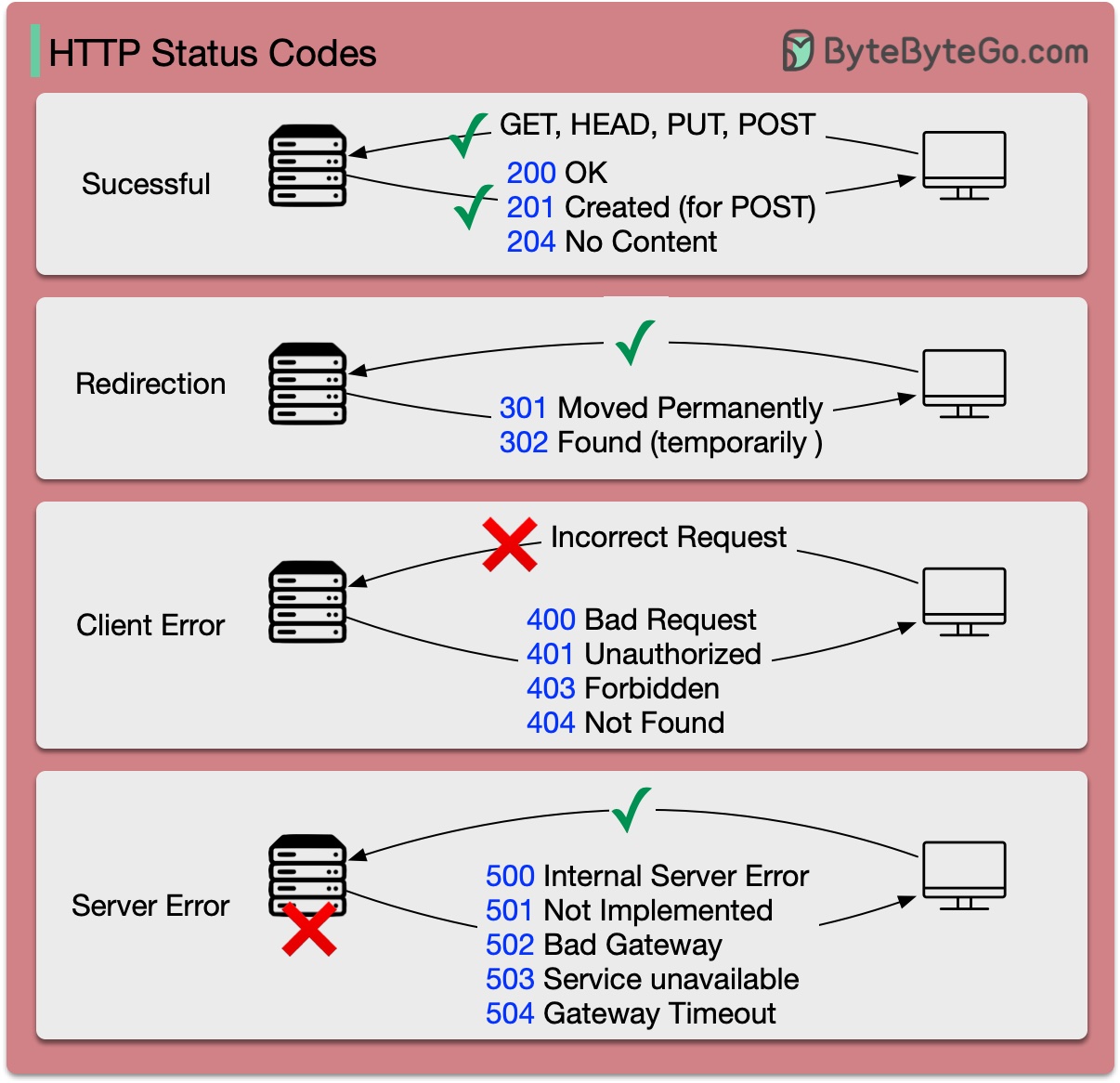
HTTP 的响应代码分为五类:
信息 (100-199) 成功 (200-299) 重定向 (300-399) 客户端错误 (400-499) 服务器错误 (500-599)
API 网关有什么作用?
下图显示了详细情况。
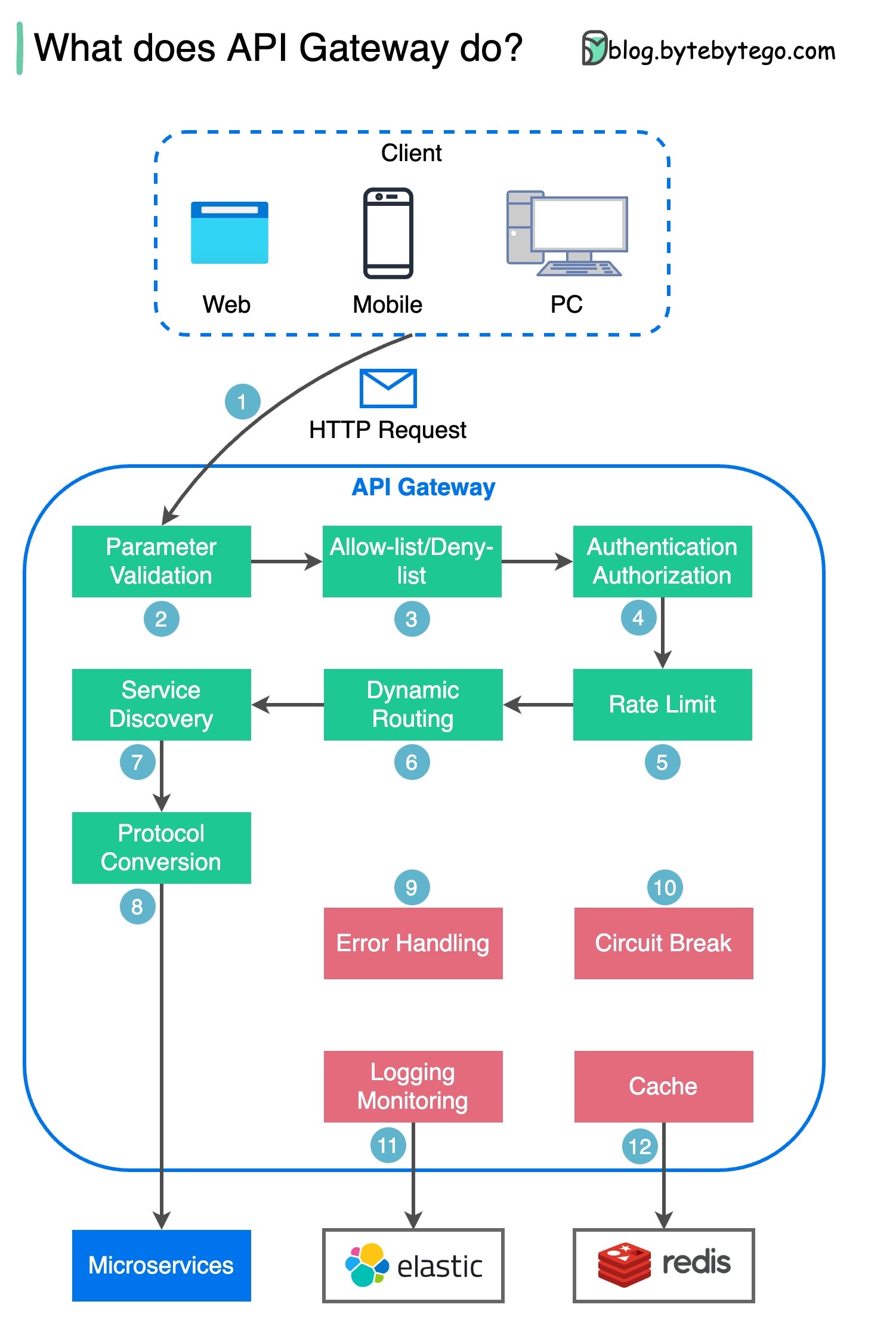
第 1 步 - 客户端向 API 网关发送 HTTP 请求。
第 2 步 - API 网关解析并验证 HTTP 请求中的属性。
第 3 步 - API 网关执行允许列表/拒绝列表检查。
第 4 步 - API 网关与身份提供商对话,进行身份验证和授权。
步骤 5 - 对请求应用速率限制规则。如果超过限制,请求将被拒绝。
第 6 步和第 7 步 - 既然请求已通过基本检查,API 网关就会通过路径匹配找到要路由的相关服务。
第 8 步 - API 网关将请求转换为适当的协议,并将其发送到后端微服务。
步骤 9-12:API 网关可以正确处理错误,并在错误需要较长时间恢复(断路)时处理故障。它还可以利用 ELK(Elastic-Logstash-Kibana)栈进行日志记录和监控。我们有时会在 API 网关中缓存数据。
如何设计有效、安全的应用程序接口?
下图以购物车为例展示了典型的应用程序接口设计。

请注意,应用程序接口设计不仅仅是 URL 路径设计。大多数时候,我们需要选择合适的资源名称、标识符和路径模式。设计适当的 HTTP 头域或在 API 网关中设计有效的速率限制规则也同样重要。
TCP/IP 封装
数据如何通过网络发送?为什么 OSI 模型需要这么多层?

下图显示了数据在网络上传输时的封装和解封过程。
步骤 1:当设备 A 通过 HTTP 协议在网络上向设备 B 发送数据时,首先会在应用层添加一个 HTTP 标头。
步骤 2:然后在数据中添加 TCP 或 UDP 报头。数据在传输层被封装成 TCP 段。报头包含源端口、目的端口和序列号。
步骤 3:然后在网络层用 IP 标头对网段进行封装。IP 标头包含源/目的 IP 地址。
步骤 4:在数据链路层为 IP 数据报添加 MAC 标头,其中包含源/目的 MAC 地址。
步骤 5:封装后的帧被发送到物理层,并以二进制位的形式通过网络发送。
步骤 6-10:设备 B 从网络接收到比特后,会执行去封装过程,这是对封装过程的逆向处理。数据头被逐层删除,最终,设备 B 可以读取数据。
在网络模型中,我们需要分层,因为每一层都专注于自己的职责。每一层都可以依靠标头来处理指令,而不需要知道上一层数据的含义。
为什么 Nginx 被称为 “反向 “代理?
下图显示了 𝐟𝐨𝐫𝐰𝐚𝐫𝐝 𝐩𝐫𝐨𝐱𝐲 和 𝐫𝐞𝐯𝐞𝐫𝐬𝐞 𝐩𝐫𝐨𝐱𝐲 之间的区别。
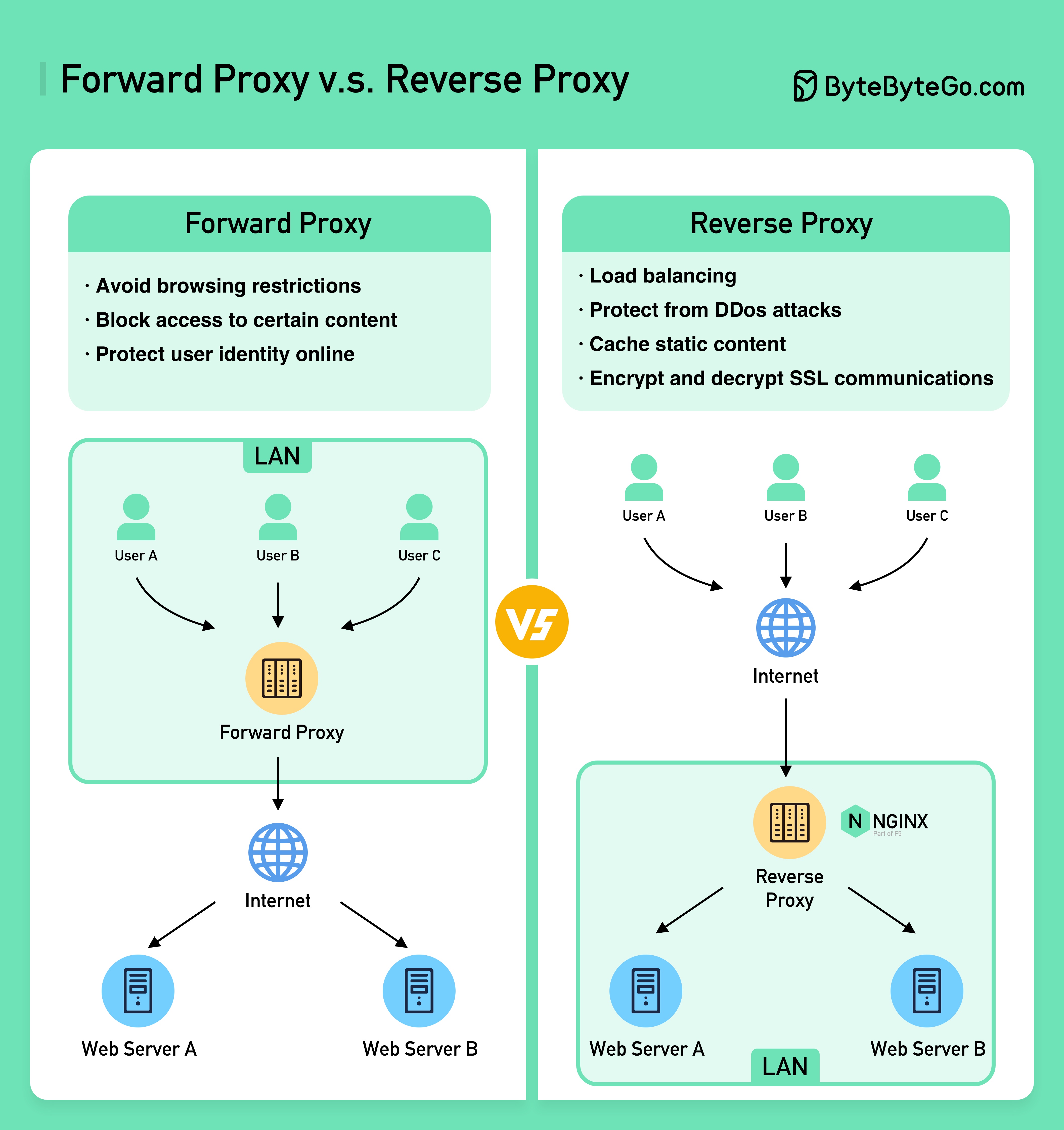
前向代理是位于用户设备和互联网之间的服务器。
前向代理通常用于
- 保护客户
- 规避浏览限制
- 阻止访问某些内容
反向代理是一种服务器,它接受客户端的请求,将请求转发给网络服务器,然后将结果返回给客户端,就好像代理服务器处理了请求一样。
反向代理可用于:
- 保护服务器
- 负载平衡
- 缓存静态内容
- 加密和解密 SSL 通信
常见的负载平衡算法有哪些?
下图显示了 6 种常见算法。
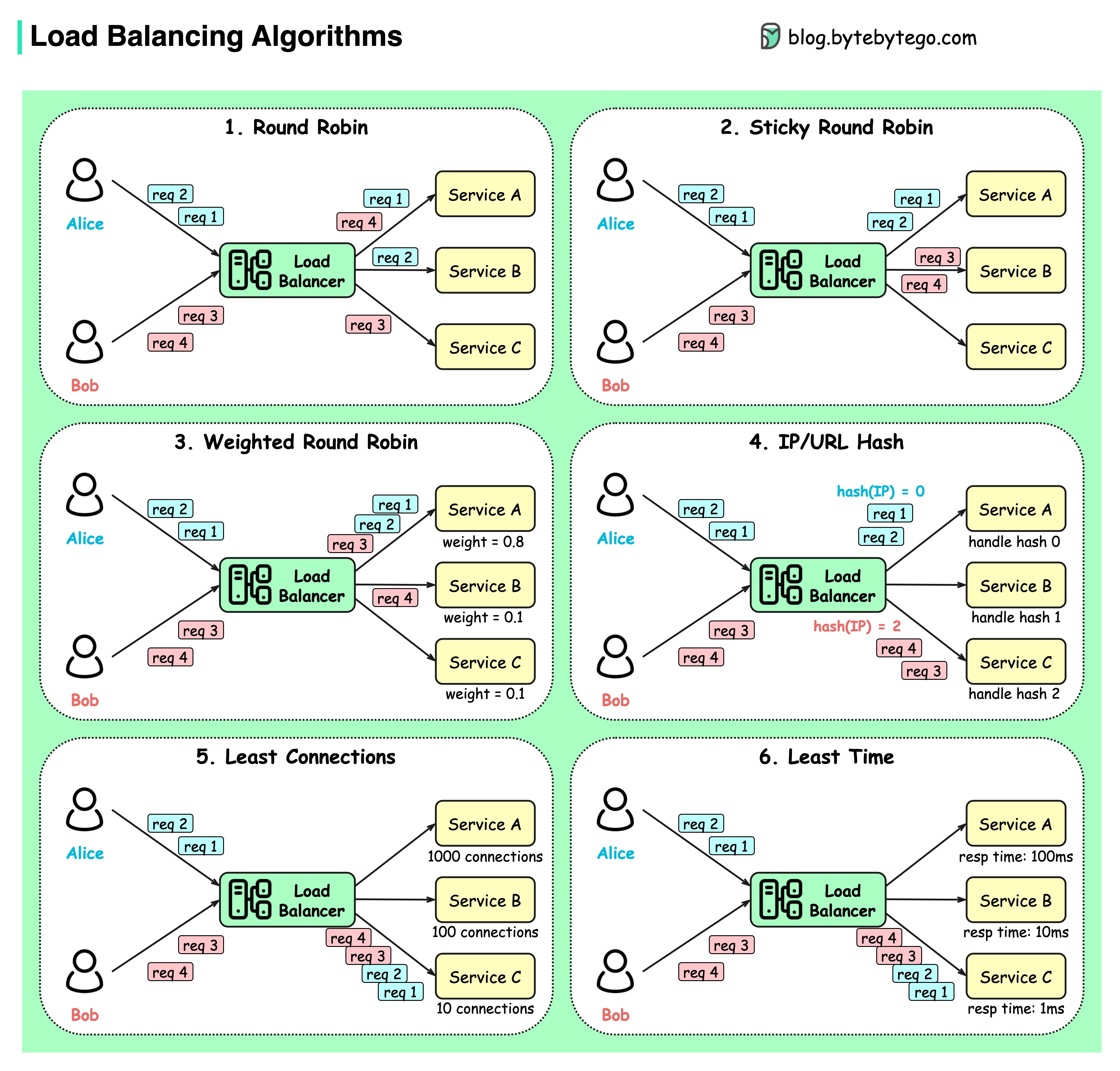
- 静态算法
- 循环赛
客户请求会按顺序发送到不同的服务实例。服务通常要求无状态。
- 粘性循环赛
这是对轮循算法的改进。如果 Alice 的第一个请求转到服务 A,那么接下来的请求也会转到服务 A。
- 加权循环
管理员可以为每项服务指定权重。权重越高的服务处理的请求就越多。
- 散列
该算法对输入请求的 IP 或 URL 应用哈希函数。根据哈希函数的结果,将请求路由到相关实例。
- 动态算法
- 连接最少
新请求会发送到并发连接最少的服务实例。
- 响应时间最短
新请求会发送到响应时间最快的服务实例。
URL、URI、URN - 您知道它们的区别吗?
下图显示了 URL、URI 和 URN 的比较。
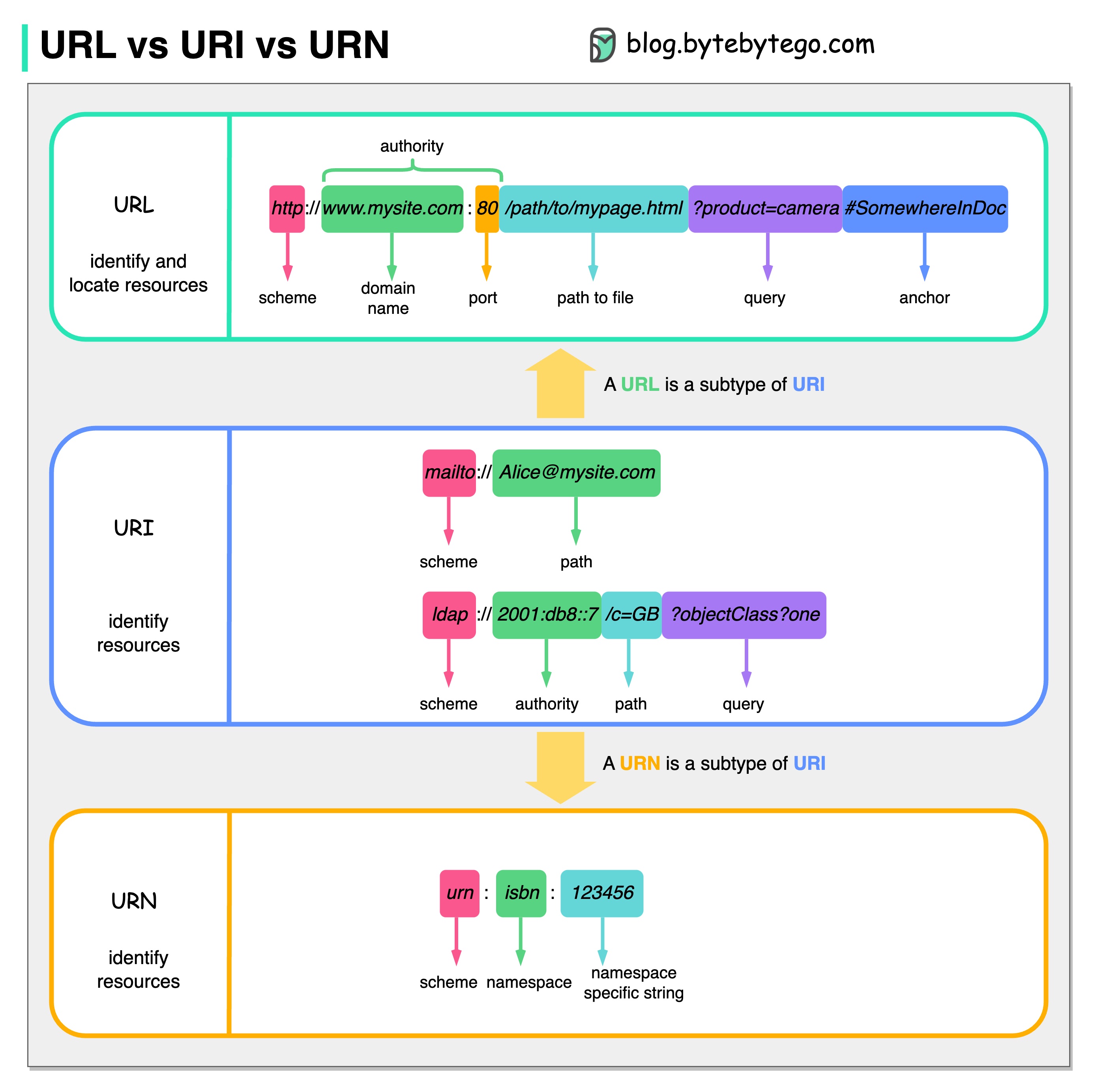
- 通用资源识别号
URI 是 Uniform Resource Identifier(统一资源标识符)的缩写。它标识网络上的逻辑或物理资源。URL 和 URN 是 URI 的子类型。URL 用于定位资源,而 URN 用于命名资源。
URI 由以下部分组成:scheme:[//authority]path[?query][#fragment][?
- 网址
URL 代表统一资源定位器,是 HTTP 的关键概念。它是网络上唯一资源的地址。它可与 FTP 和 JDBC 等其他协议一起使用。
- 通用名
URN 代表统一资源名称。它使用 urn 方案。URN 不能用于定位资源。图中给出的一个简单示例由命名空间和命名空间特定字符串组成。
如果您想了解这方面的更多详情,我建议您阅读 W3C 的说明。
CI/CD
简单解释 CI/CD 管道

第 1 节 - 采用 CI/CD 的 SDLC
软件开发生命周期(SDLC)包括几个关键阶段:开发、测试、部署和维护。CI/CD 对这些阶段进行自动化和集成,以实现更快、更可靠的发布。
当代码推送到 git 仓库时,会触发自动构建和测试流程。端到端(e2e)测试用例将被运行以验证代码。如果测试通过,代码就能自动部署到暂存/生产阶段。如果发现问题,代码将被送回开发部门进行错误修复。这种自动化可为开发人员提供快速反馈,并降低生产中出现错误的风险。
第 2 部分 - 传播和信息与会议(CI)与会议文件(CD)的区别
持续集成(CI)实现了构建、测试和合并流程的自动化。每当提交代码时,它都会运行测试,以便及早发现集成问题。这鼓励了代码的频繁提交和快速反馈。
持续交付(CD)实现了基础架构变更和部署等发布流程的自动化。它通过自动化工作流程确保软件可以随时可靠地发布。CD 还可以自动执行生产部署前所需的手动测试和审批步骤。
第 3 节 - CI/CD 管道
一个典型的 CI/CD 管道有几个相连的阶段:
- 开发人员将代码更改提交到源代码控制
- CI 服务器检测更改并触发构建
- 编译代码并进行测试(单元测试和集成测试)
- 向开发人员报告测试结果
- 成功后,工件将部署到暂存环境中
- 在发布之前,可在暂存阶段进行进一步测试
- CD 系统将批准的变更部署到生产中
Netflix 技术栈(CI/CD 管道)

规划:Netflix 工程部使用 JIRA 进行规划,使用 Confluence 编写文档。
编码:Java 是后台服务的主要编程语言,其他语言用于不同的使用情况。
构建Gradle 主要用于构建,而 Gradle 插件则用于支持各种使用情况。
打包:将软件包和依赖项打包到亚马逊机器映像(AMI)中,以便发布。
测试:测试:测试强调生产文化对构建混乱工具的关注。
部署:Netflix 使用自建的 Spinnaker 来部署金丝雀。
监测:监控指标集中在 Atlas 系统中,Kayenta 系统用于检测异常情况。
事件报告:根据优先级派遣事件,并使用 PagerDuty 进行事件处理。
架构模式
MVC、MVP、MVVM、MVVM-C 和 VIPER
无论是 iOS 还是 Android 平台,这些架构模式都是应用程序开发中最常用的模式之一。开发人员引入这些模式是为了克服早期模式的局限性。那么,它们有什么不同呢?
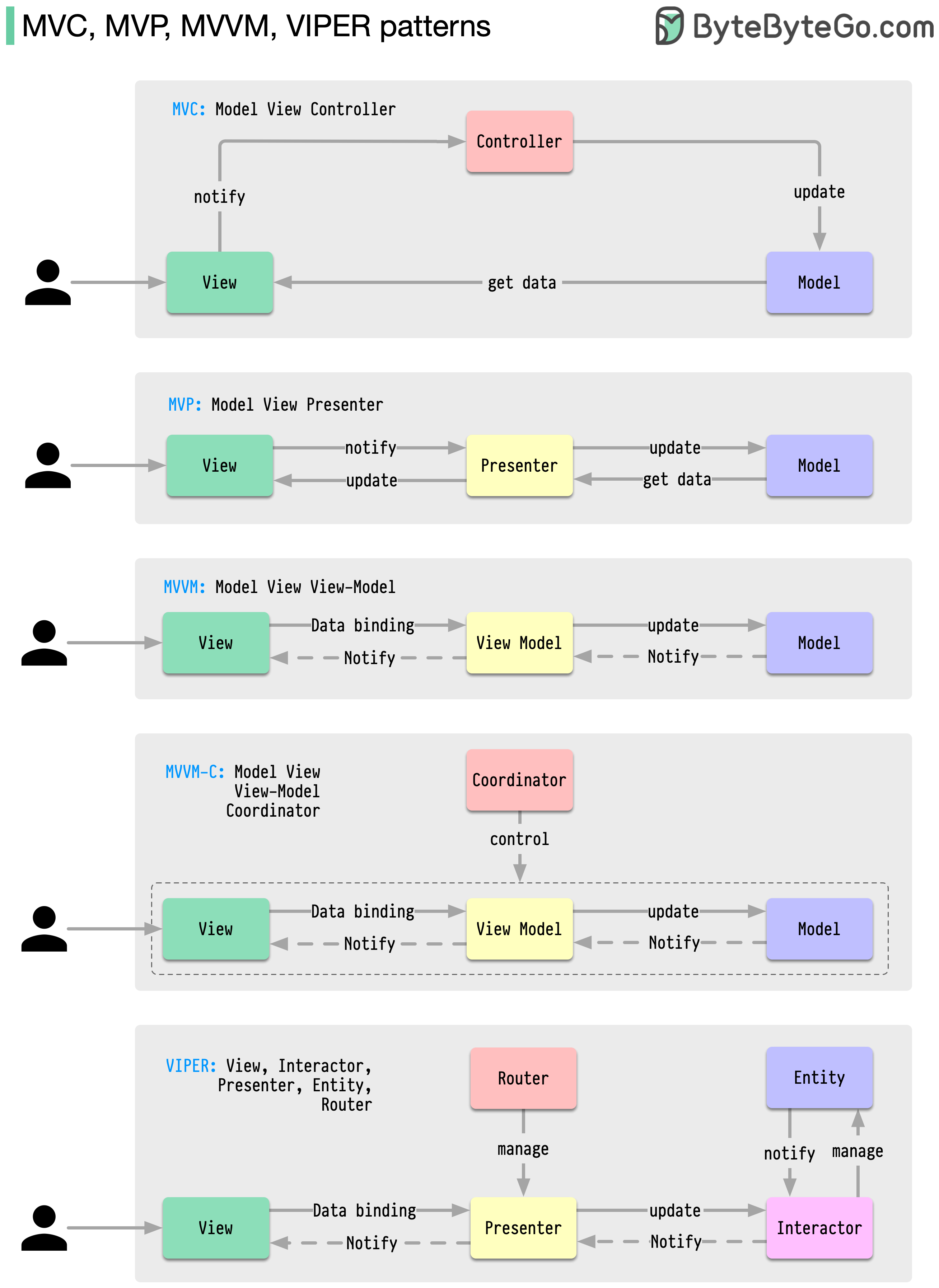
- MVC 是最古老的模式,可追溯到近 50 年前
- 每个模式都有一个 “视图”(V),负责显示内容和接收用户输入
- 大多数模式都包含一个 “模型”(M),用于管理业务数据
- “控制器”、“演示器 “和 “视图-模型 “是视图和模型(VIPER 模式中的 “实体”)之间的翻译器。
每个开发人员都应了解的 18 种关键设计模式
模式是针对常见设计问题的可重复使用的解决方案,可使开发过程更顺畅、更高效。它们是构建更好的软件结构的蓝图。以下是一些最流行的模式:

- 抽象工厂:家族创建器 - 创建相关项目组。
- 建造者乐高大师 - 逐步构建物体,将创建和外观分开。
- 原型:克隆制作器 - 制作完全准备好的示例的副本。
- 单例:独一无二:只有一个实例的特殊类。
- 适配器:通用插头 - 可连接不同接口的设备。
- 桥梁:功能连接器 - 将对象的工作方式与功能联系起来。
- 合成:树形生成器 - 由简单和复杂部件组成树形结构。
- 装饰器:自定义器 - 在不改变对象核心的情况下为其添加功能。
- 门面:一站式服务–以简化的单一界面代表整个系统。
- Flyweight:节省空间–有效分享可重复使用的小物品。
- 代理:代理:替身–代表另一个对象,控制访问或操作。
- 责任链:请求中继 - 通过对象链传递请求,直至处理完毕。
- 命令:任务包装器 - 将请求转化为对象,随时可执行操作。
- 迭代器集合浏览器 - 逐个访问集合中的元素。
- 调解器:通信枢纽 - 简化不同类之间的交互。
- 记忆:时间胶囊 - 捕捉并恢复对象的状态。
- 观察者新闻播报员 - 通知类其他对象的变化。
- 游客技艺高超的访客 - 在不改变类别的情况下为类别添加新的操作。
数据库
云服务中不同数据库的小抄
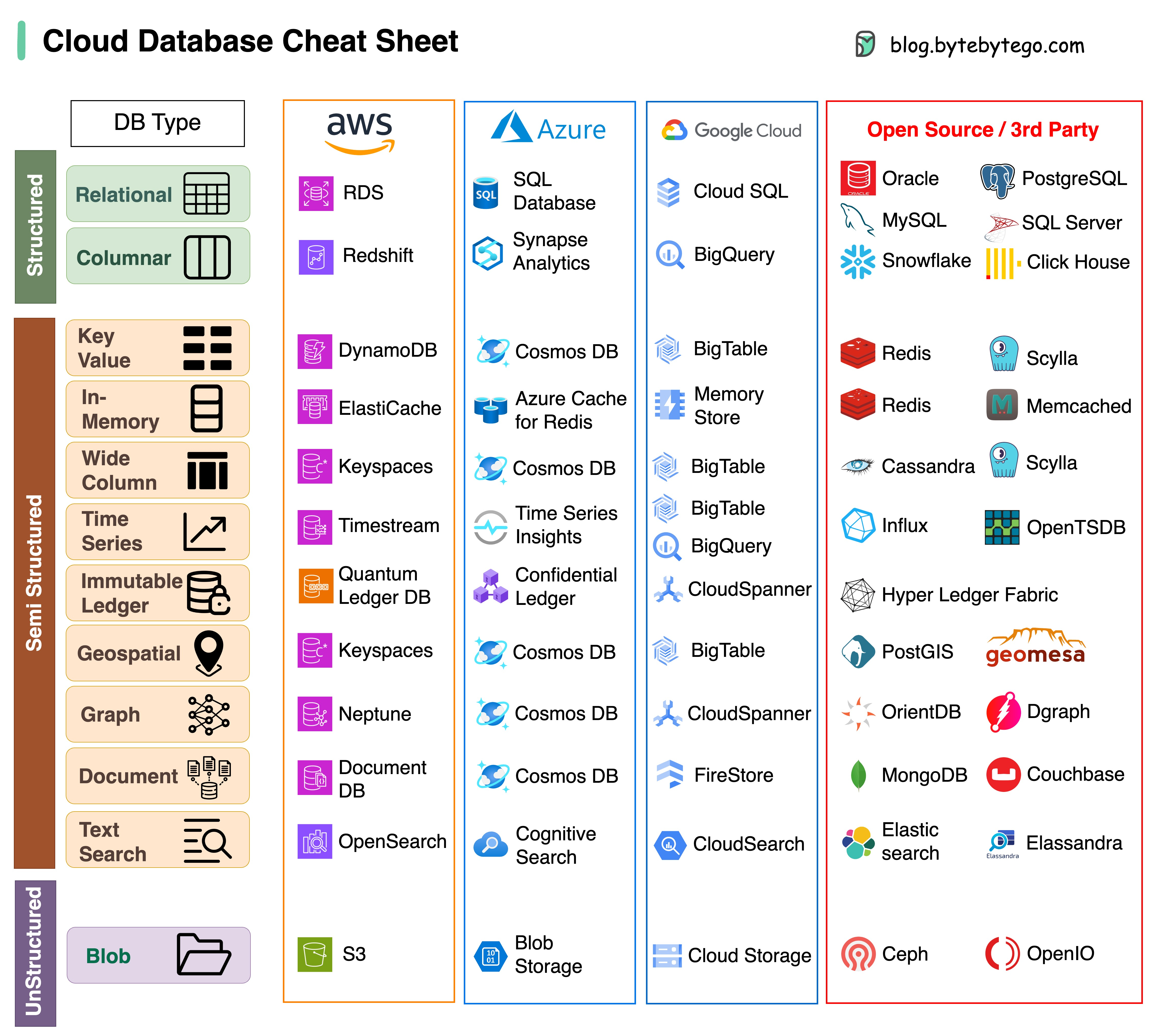
为项目选择合适的数据库是一项复杂的任务。数据库选项众多,每种都适合不同的使用情况,很快就会导致决策疲劳。
我们希望这份小抄能提供高层次的指导,帮助您找到符合项目需求的正确服务,并避免潜在的陷阱。
注:谷歌数据库用例文档有限。尽管我们尽最大努力查看了现有资料,并得出了最佳方案,但某些条目可能需要更加准确。
为数据库提供动力的 8 种数据结构
答案因使用情况而异。数据可以在内存或磁盘中建立索引。同样,数据格式也各不相同,如数字、字符串、地理坐标等。系统可能重写,也可能重读。所有这些因素都会影响数据库索引格式的选择。
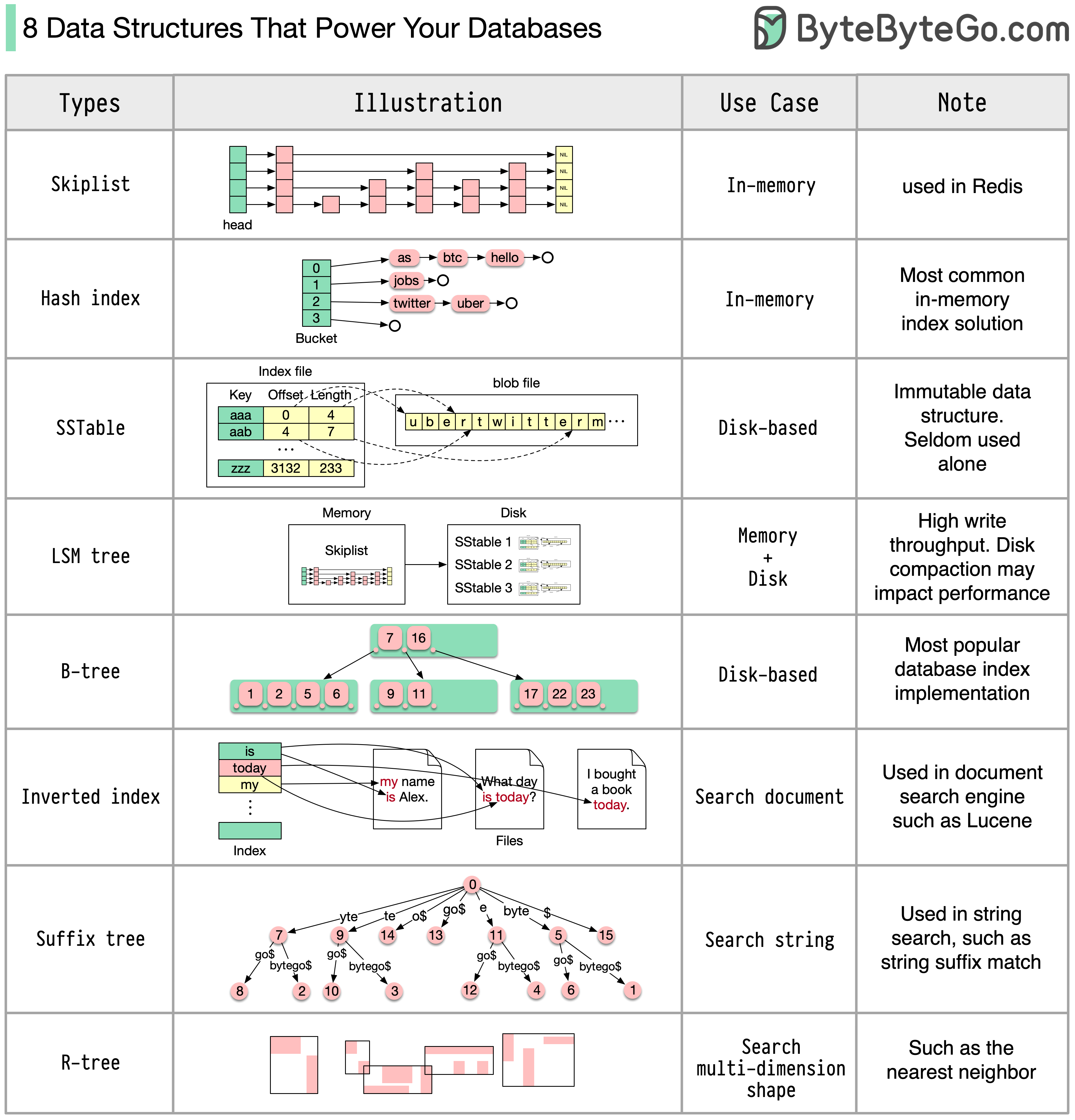
以下是一些最常用的索引数据结构:
- Skiplist:一种常见的内存索引类型。在 Redis 中使用
- 哈希索引:“地图 “数据结构(或 “集合”)的一种非常常见的实现方式
- SSTable:磁盘上不可变的 “地图 “实现
- LSM 树Skiplist + SSTable。高写入吞吐量
- B 树:基于磁盘的解决方案。一致的读写性能
- 反转索引:用于文档索引。在 Lucene 中使用
- 后缀树:用于字符串模式搜索
- R 树:多维搜索,如寻找最近的邻居
如何在数据库中执行 SQL 语句?
下图显示了这一过程。请注意,不同数据库的架构各不相同,下图展示了一些常见的设计。
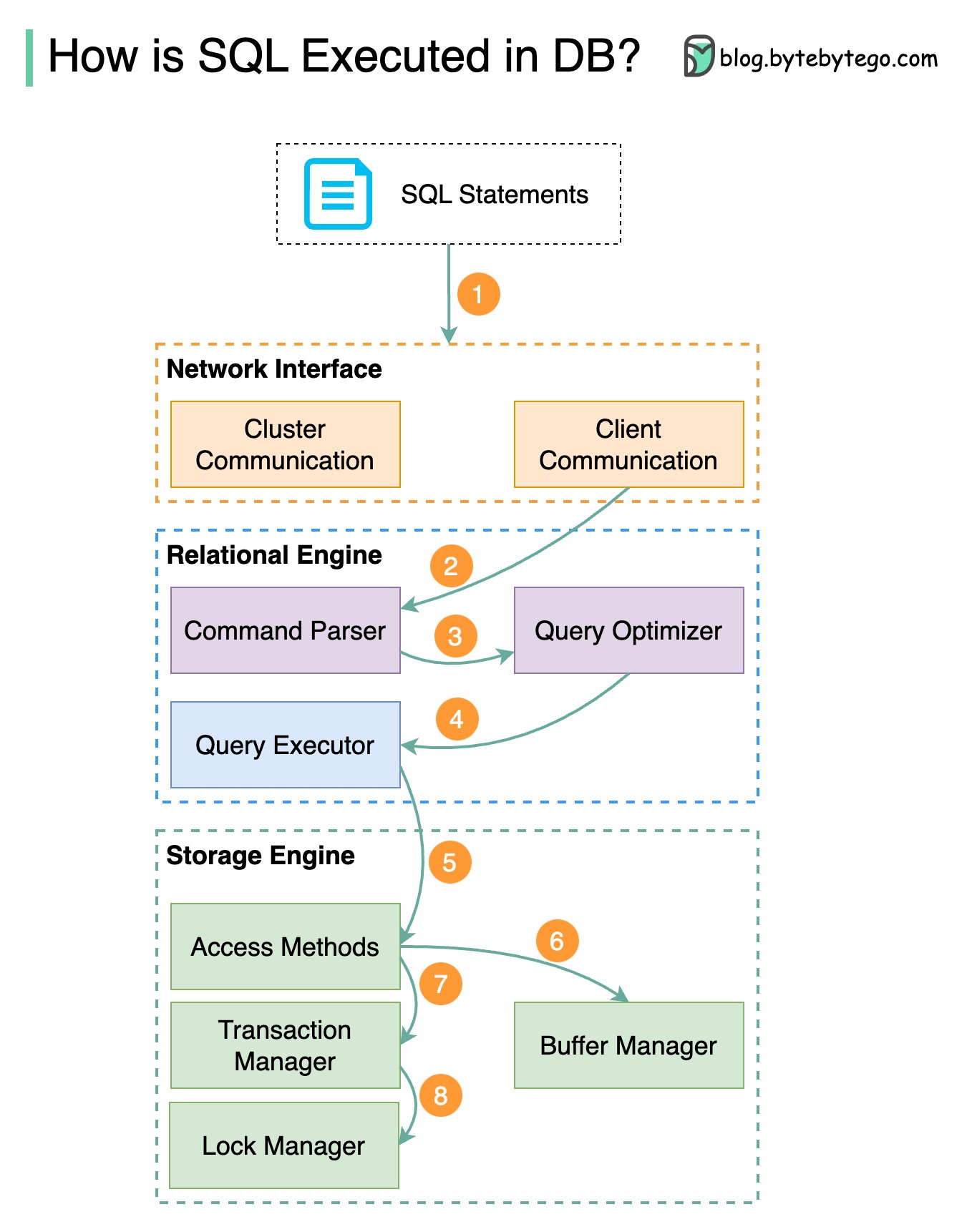
步骤 1 - 通过传输层协议(如 TCP)向数据库发送 SQL 语句。
第 2 步 - SQL 语句被发送到命令解析器,在那里进行语法和语义分析,然后生成查询树。
第 3 步 - 将查询树发送给优化器。优化器会创建一个执行计划。
步骤 4 - 将执行计划发送给执行器。执行器从执行计划中获取数据。
步骤 5 - 访问方法提供执行所需的数据获取逻辑,从存储引擎获取数据。
步骤 6 - 访问方法决定 SQL 语句是否只读。如果查询是只读的(SELECT 语句),则将其传递给缓冲区管理器进行进一步处理。缓冲区管理器会在缓存或数据文件中查找数据。
第 7 步 - 如果语句是 UPDATE 或 INSERT,则将其传递给事务管理器作进一步处理。
步骤 8 - 在事务处理期间,数据处于锁定模式。这是由锁管理器保证的。这也确保了事务的 ACID 属性。
CAP 定理
CAP 定理是计算机科学中最著名的术语之一,但我敢打赌,不同的开发人员对它有不同的理解。让我们来看看它到底是什么,以及为什么会让人感到困惑。
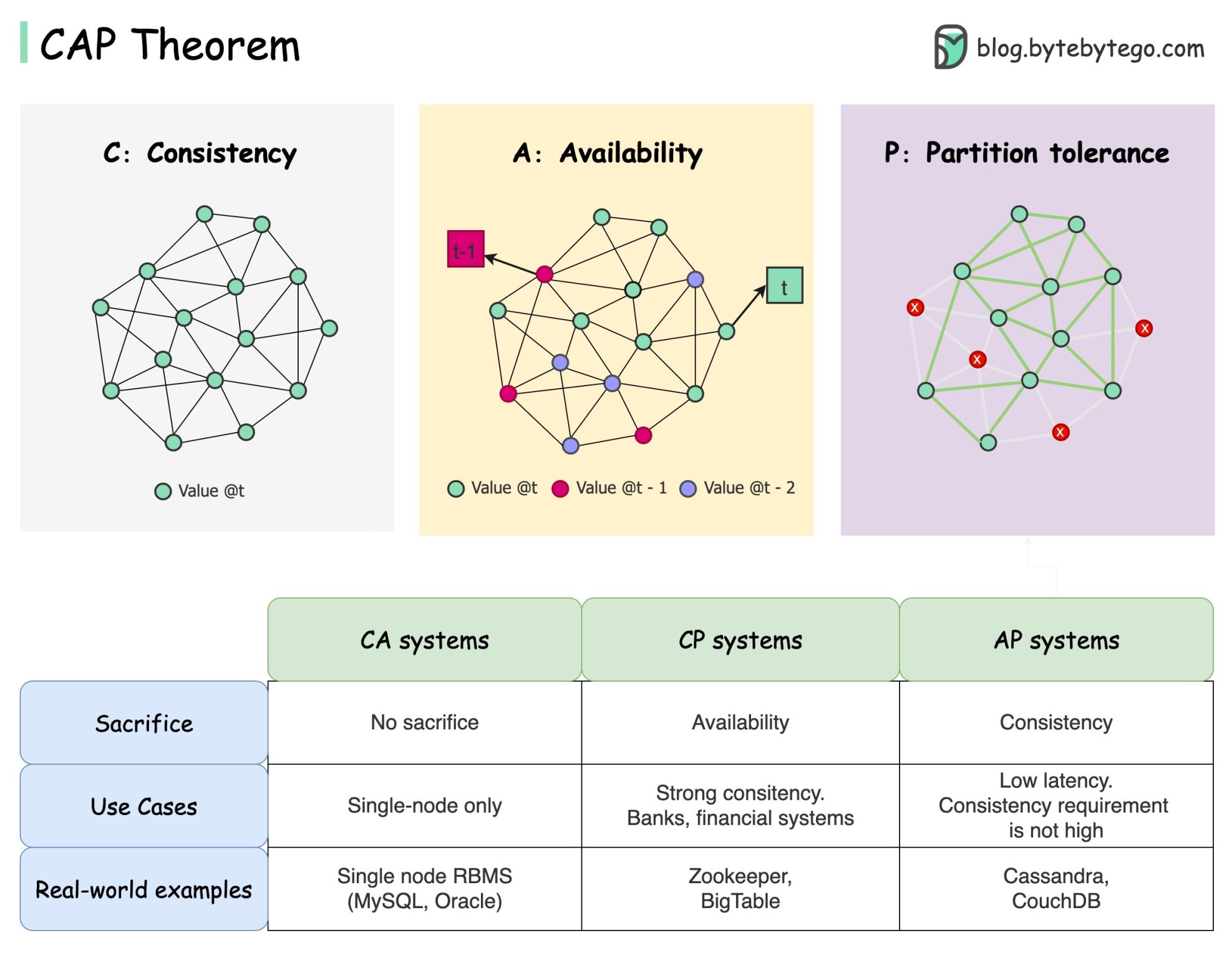
CAP 定理指出,分布式系统无法同时提供这三种保证中的两种以上。
一致性:一致性意味着所有客户端无论连接到哪个节点,都能在同一时间看到相同的数据。
可用性:可用性意味着,即使部分节点宕机,任何请求数据的客户端都能得到响应。
分区容忍度:分区表示两个节点之间的通信中断。分区容错是指尽管出现网络分区,系统仍能继续运行。
2 of 3 “的提法可能有用,但这种简化可能会产生误导。
- 选择数据库并非易事。仅仅根据 CAP 定理来证明我们的选择是不够的。例如,公司不会仅仅因为 Cassandra 是 AP 系统就为聊天应用选择它。Cassandra 有一系列优良特性,是存储聊天信息的理想选择。我们需要深入挖掘。
- “CAP 只禁止了设计空间的一小部分:在存在分区的情况下具有完美的可用性和一致性,而这种情况很少见”。引自论文:十二年后的 CAP:规则 “是如何改变的。
- 该定理涉及 100% 的可用性和一致性。更现实的讨论是在没有网络分区的情况下,如何权衡延迟和一致性。详见 PACELC 定理。
CAP 定理真的有用吗?
我认为它仍然有用,因为它为我们提供了一系列权衡讨论的思路,但它只是故事的一部分。在选择合适的数据库时,我们需要深入挖掘。
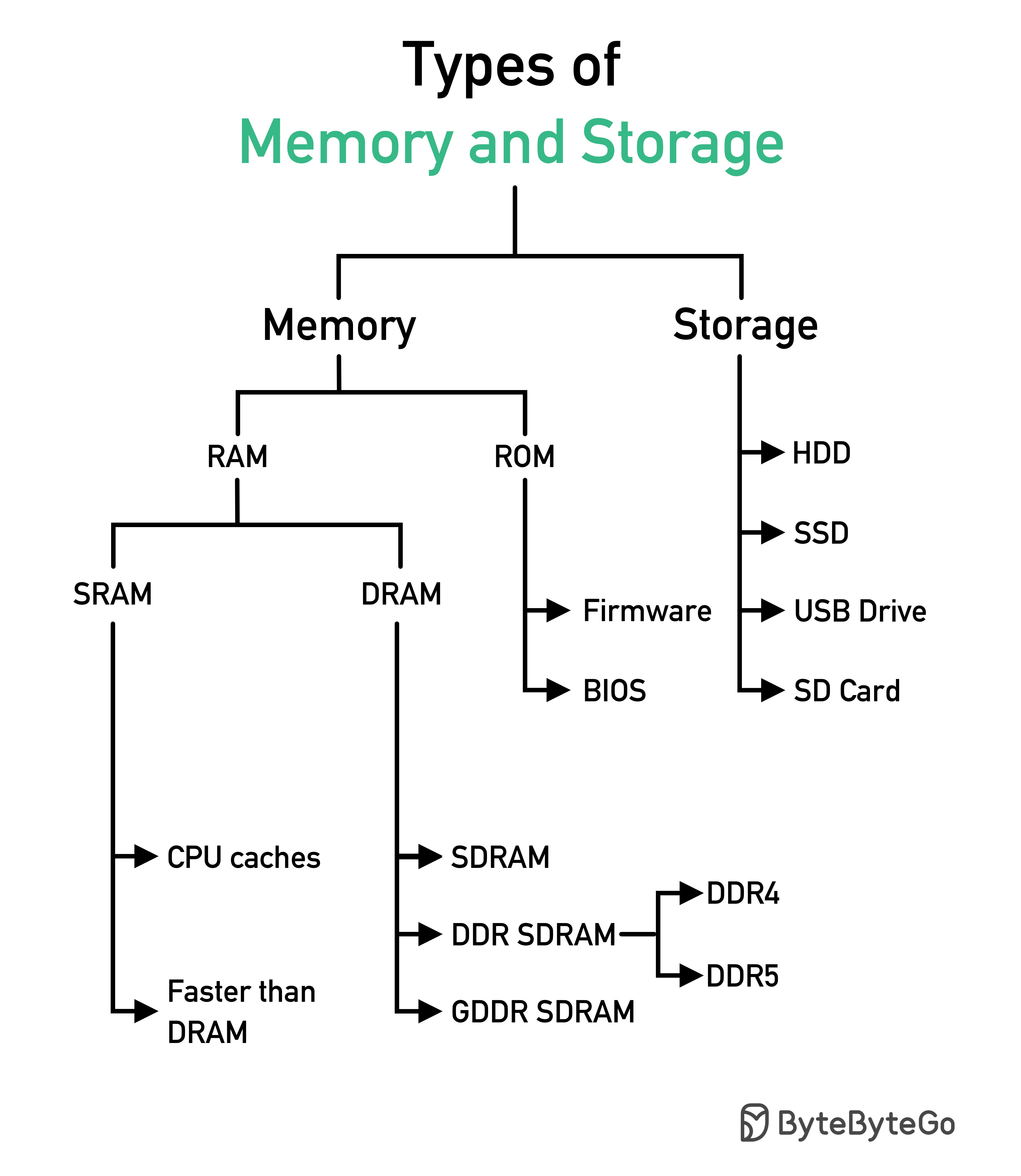
内存和存储器类型
可视化 SQL 查询
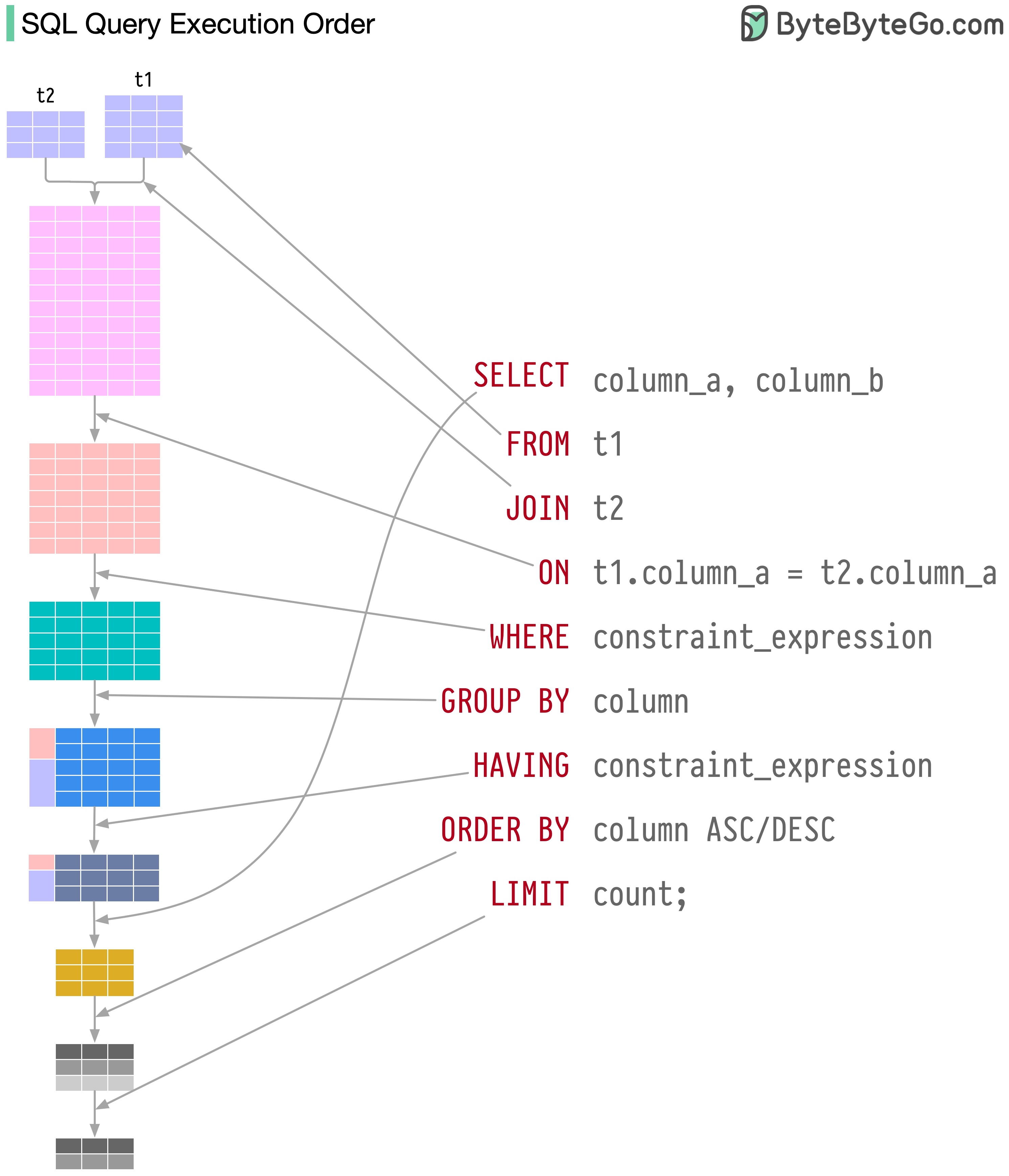
数据库系统执行 SQL 语句有几个步骤,包括
- 解析 SQL 语句并检查其有效性
- 将 SQL 转换为内部表示法,如关系代数
- 优化内部表示法,创建可利用索引信息的执行计划
- 执行计划并返回结果
SQL 的执行非常复杂,需要考虑很多因素,例如
- 索引和缓存的使用
- 表格连接的顺序
- 并发控制
- 事务管理
SQL 语言
1986 年,SQL(结构化查询语言)成为一种标准。在接下来的 40 年里,它成为关系数据库管理系统的主流语言。阅读最新标准(ANSI SQL 2016)可能很费时间。如何学习?
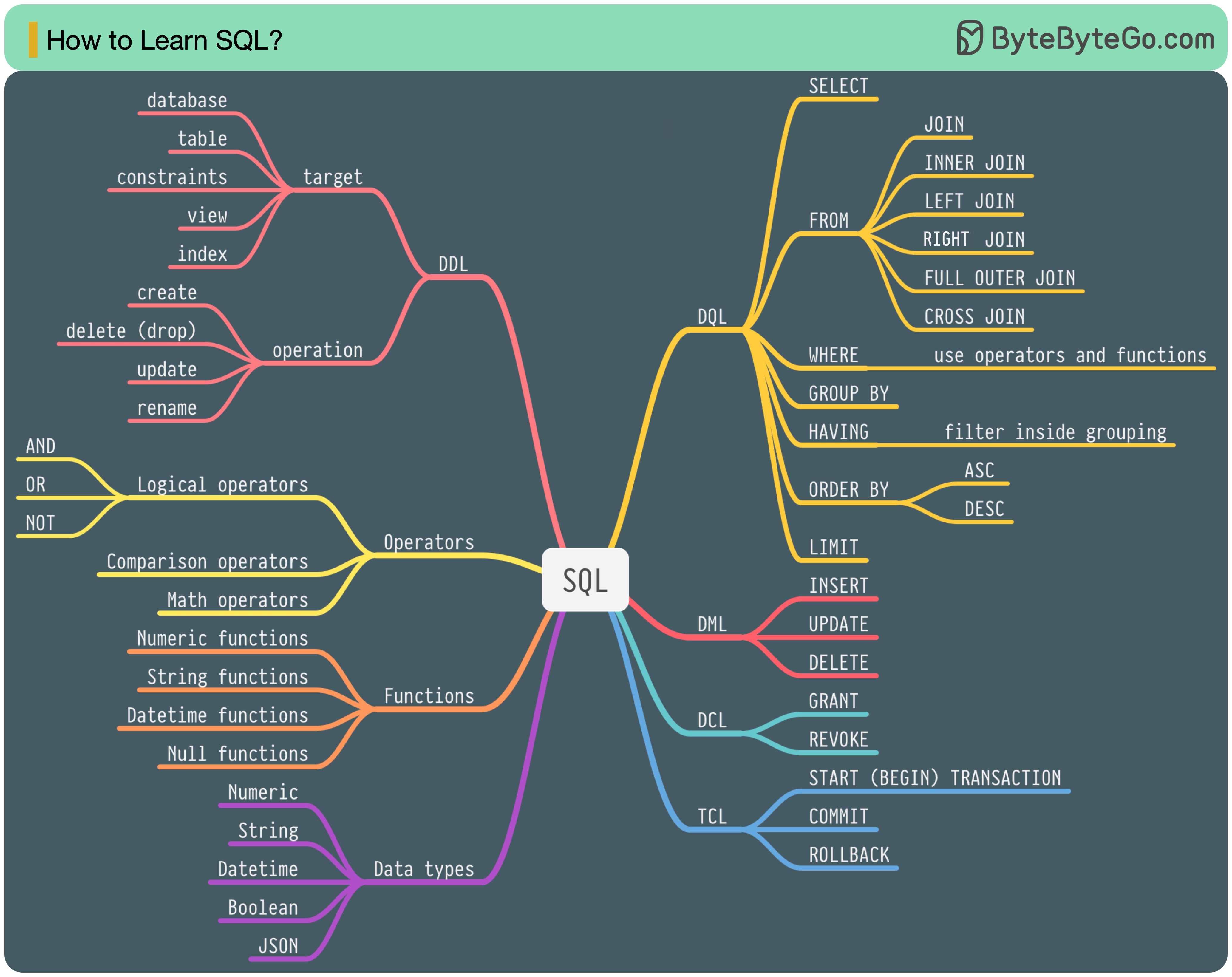
SQL 语言有 5 个组成部分:
- DDL:数据定义语言,如 CREATE、ALTER、DROP
- DQL:数据查询语言,如 SELECT
- DML:数据操作语言,如 INSERT、UPDATE、DELETE
- DCL:数据控制语言,如 GRANT、REVOKE
- TCL:事务控制语言,如 COMMIT、ROLLBACK
对于后端工程师来说,您可能需要了解其中的大部分内容。作为数据分析师,您可能需要充分了解 DQL。选择与您最相关的主题。
缓存
数据缓存无处不在
该图说明了我们在典型架构中缓存数据的位置。
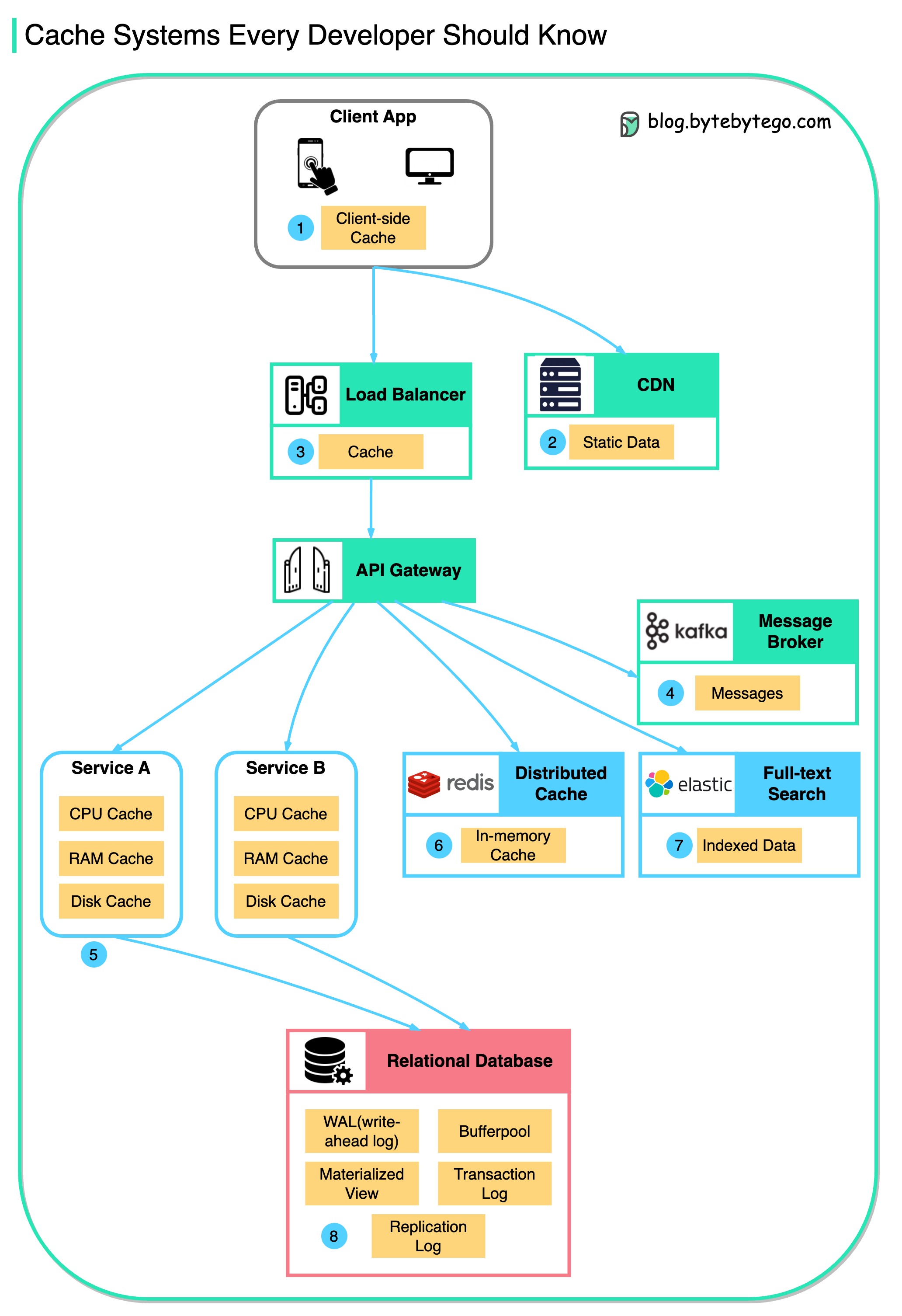
水流有多个层次。
- 客户端应用程序:浏览器可以缓存 HTTP 响应。我们第一次通过 HTTP 请求数据时,HTTP 头会返回一个过期策略;我们再次请求数据时,客户端应用程序会尝试先从浏览器缓存中检索数据。
- CDN:CDN 缓存静态网络资源。客户端可以从附近的 CDN 节点检索数据。
- 负载平衡器:负载平衡器还可以缓存资源。
- 信息传递基础设施:消息代理首先将消息存储在磁盘上,然后消费者按自己的节奏检索消息。根据保留策略,数据会在 Kafka 集群中缓存一段时间。
- 服务:服务中有多层缓存。如果 CPU 缓存中没有缓存数据,服务就会尝试从内存中检索数据。有时,服务会有一个二级缓存,将数据存储在磁盘上。
- 分布式缓存:分布式缓存(如 Redis)可在内存中保存多个服务的键值对。它的读/写性能比数据库好得多。
- 全文搜索:我们有时需要使用全文搜索(如用于文档搜索或日志搜索的 Elastic Search)。数据副本也会被索引到搜索引擎中。
- 数据库:即使在数据库中,我们也有不同级别的缓存:
- WAL(先写日志):数据先写入 WAL,然后再建立 B 树索引
- 缓冲池分配用于缓存查询结果的内存区域
- 物化视图:预先计算查询结果并将其存储在数据库表中,以提高查询性能
- 事务日志:记录所有事务和数据库更新
- 复制日志:用于记录数据库群集中的复制状态
Redis 为什么这么快?
如下图所示,主要有 3 个原因。
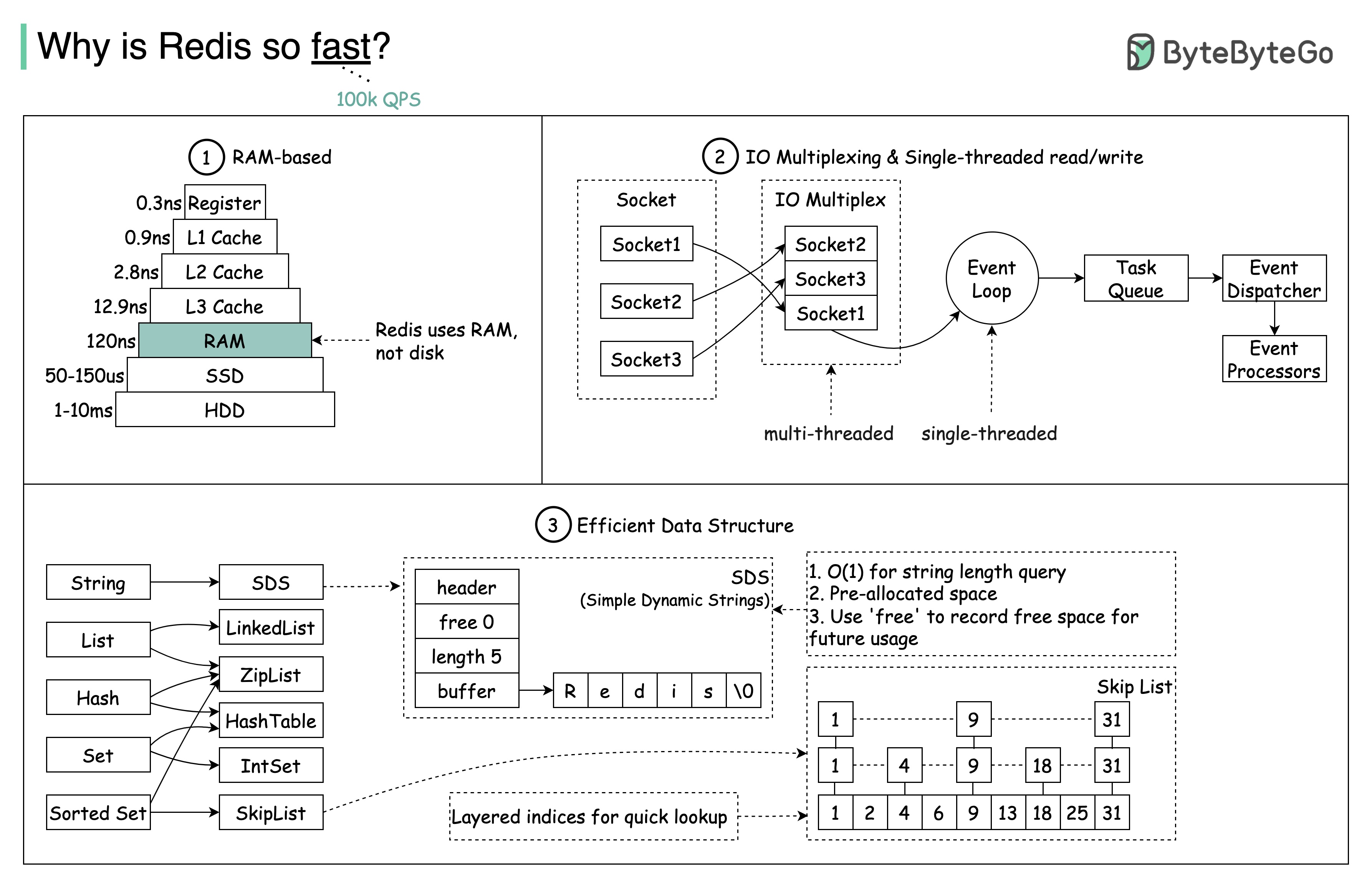
- Redis 是一种基于 RAM 的数据存储。RAM 访问速度至少是随机磁盘访问速度的 1000 倍。
- Redis 利用 IO 多路复用和单线程执行循环提高执行效率。
- Redis 利用了几种高效的底层数据结构。
问题另一种流行的内存存储是 Memcached。你知道 Redis 和 Memcached 的区别吗?
您可能已经注意到,这张图的风格与我以前的文章不同。请告诉我您更喜欢哪一种。
如何使用 Redis?
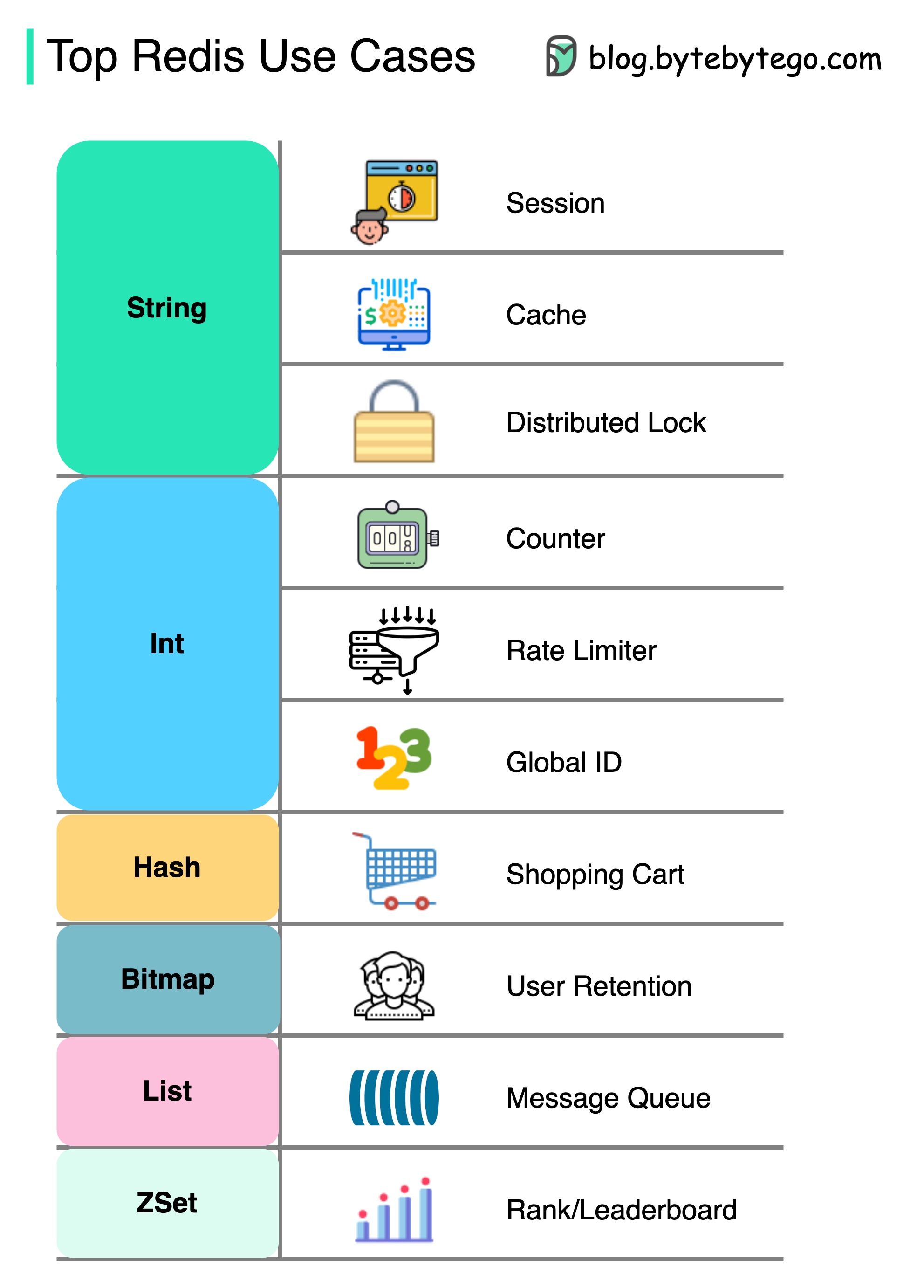
Redis 不仅仅是缓存。
如图所示,Redis 可用于多种场景。
- 会议
我们可以使用 Redis 在不同服务之间共享用户会话数据。
- 缓存
我们可以使用 Redis 来缓存对象或页面,尤其是热点数据。
- 分布式锁
我们可以使用 Redis 字符串在分布式服务之间获取锁。
- 计数器
我们可以计算文章的点赞数或阅读数。
- 速率限制器
我们可以为某些用户 IP 设置速率限制器。
- 全球 ID 生成器
我们可以使用 Redis Int 作为全局 ID。
- 购物车
我们可以使用 Redis Hash 来表示购物车中的键值对。
-
计算用户留存率
我们可以使用位图来表示用户每天的登录情况,并计算用户留存率。
-
信息队列
我们可以使用 List 作为消息队列。
- 排名
我们可以使用 ZSet 对文章进行排序。
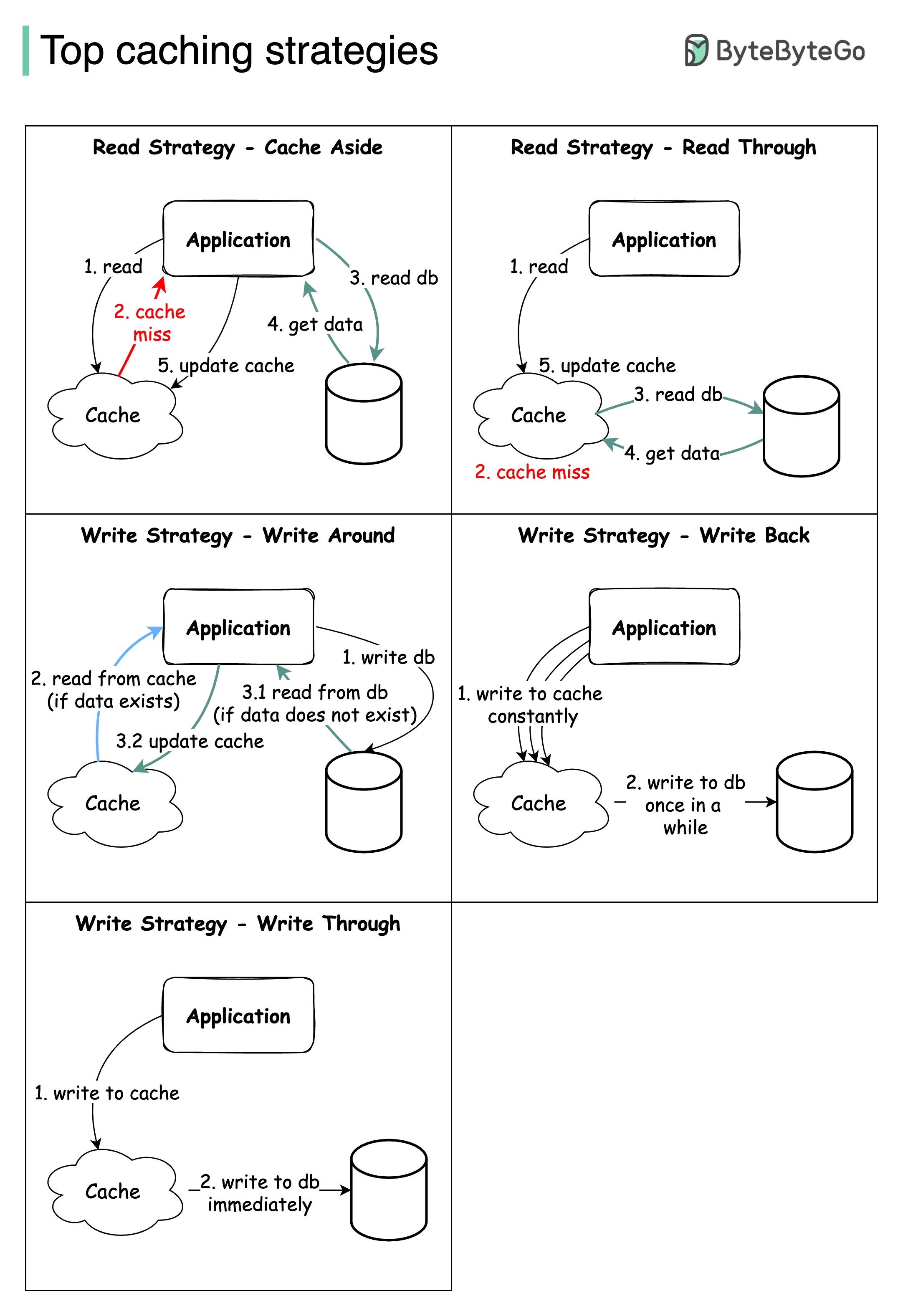
顶级缓存策略
设计大型系统通常需要仔细考虑缓存问题。以下是经常使用的五种缓存策略。
微服务架构
典型的微服务架构是什么样的?
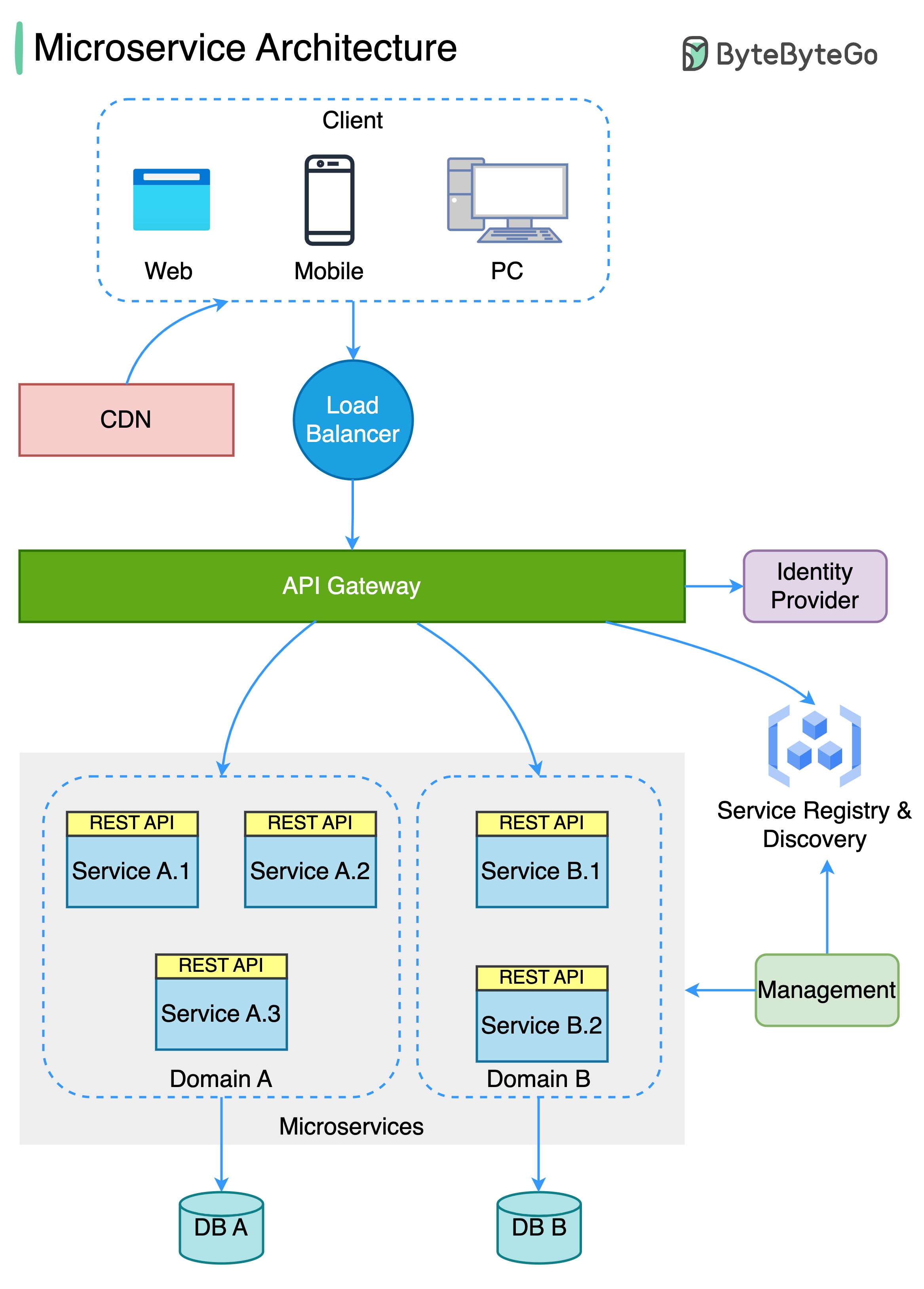
下图显示了典型的微服务架构。
- 负载平衡器:它将传入流量分配给多个后端服务。
- CDN(内容分发网络):CDN 是一组分布在不同地理位置的服务器,用于保存静态内容以加快传输速度。客户首先在 CDN 中查找内容,然后再转到后端服务。
- API 网关:它负责处理传入的请求,并将其路由到相关服务。它与身份提供商和服务发现者进行对话。
- 身份供应商:它负责用户的身份验证和授权。
- 服务注册和发现:微服务注册和发现在此组件中进行,API 网关在此组件中寻找相关服务进行对话。
- 管理:该部分负责监控服务。
- 微服务:微服务在不同的域中设计和部署。每个域都有自己的数据库。API 网关通过 REST API 或其他协议与微服务对话,同一域内的微服务通过 RPC(远程过程调用)相互对话。
微服务的优势
- 它们可以快速设计、部署和横向扩展。
- 每个域都可由一个专门团队独立维护。
- 因此,每个领域的业务需求都可以定制,并得到更好的支持。
微服务最佳实践
一图胜千言:开发微服务的 9 项最佳实践。
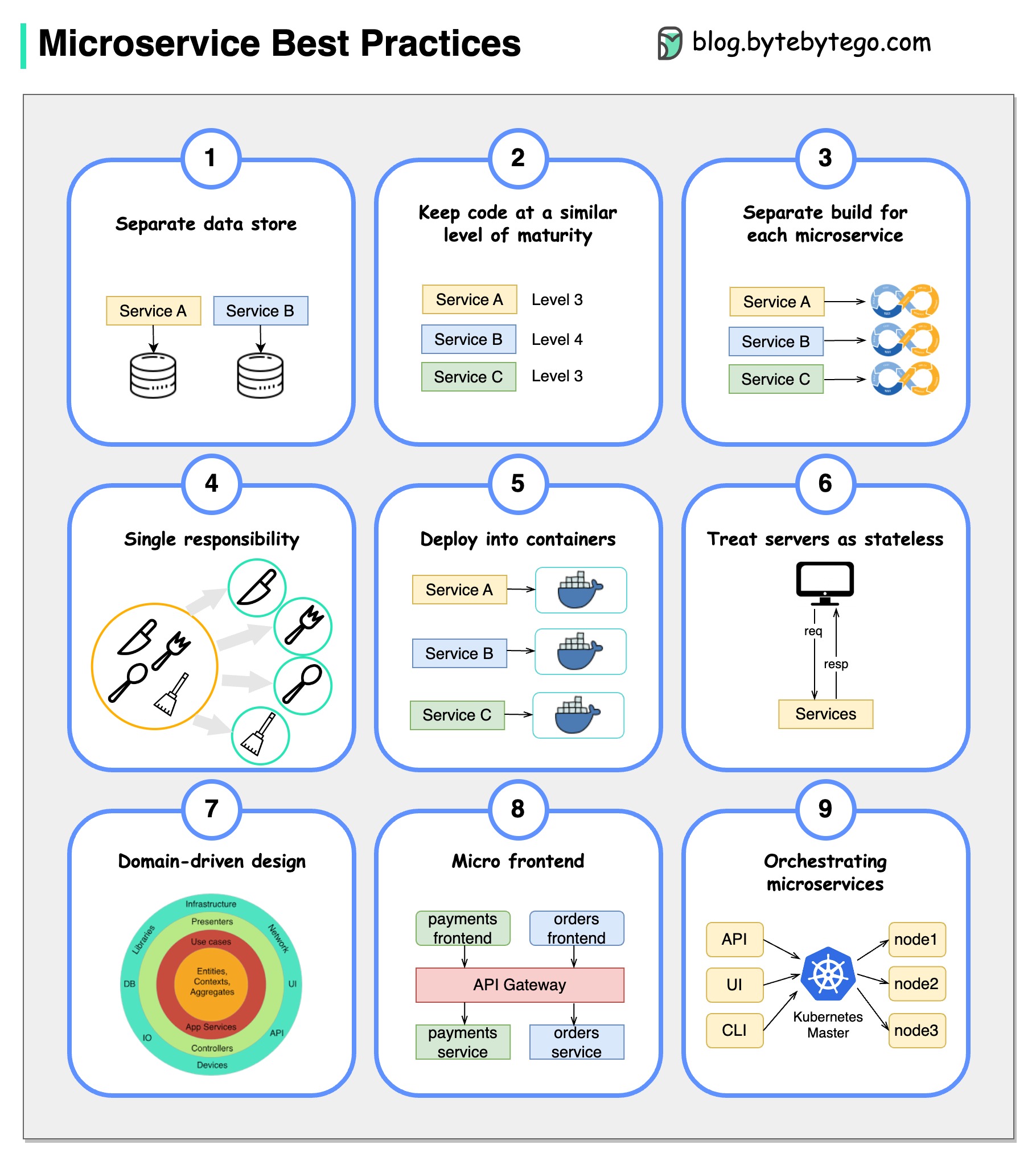
在开发微服务时,我们需要遵循以下最佳实践:
- 为每个微服务使用单独的数据存储
- 使代码保持类似的成熟度
- 为每个微服务单独构建
- 为每个微服务分配单一职责
- 部署到容器中
- 设计无状态服务
- 采用领域驱动设计
- 设计微型前端
- 协调微服务
微服务通常使用什么技术栈?
下图展示了开发阶段和生产阶段的微服务技术栈。
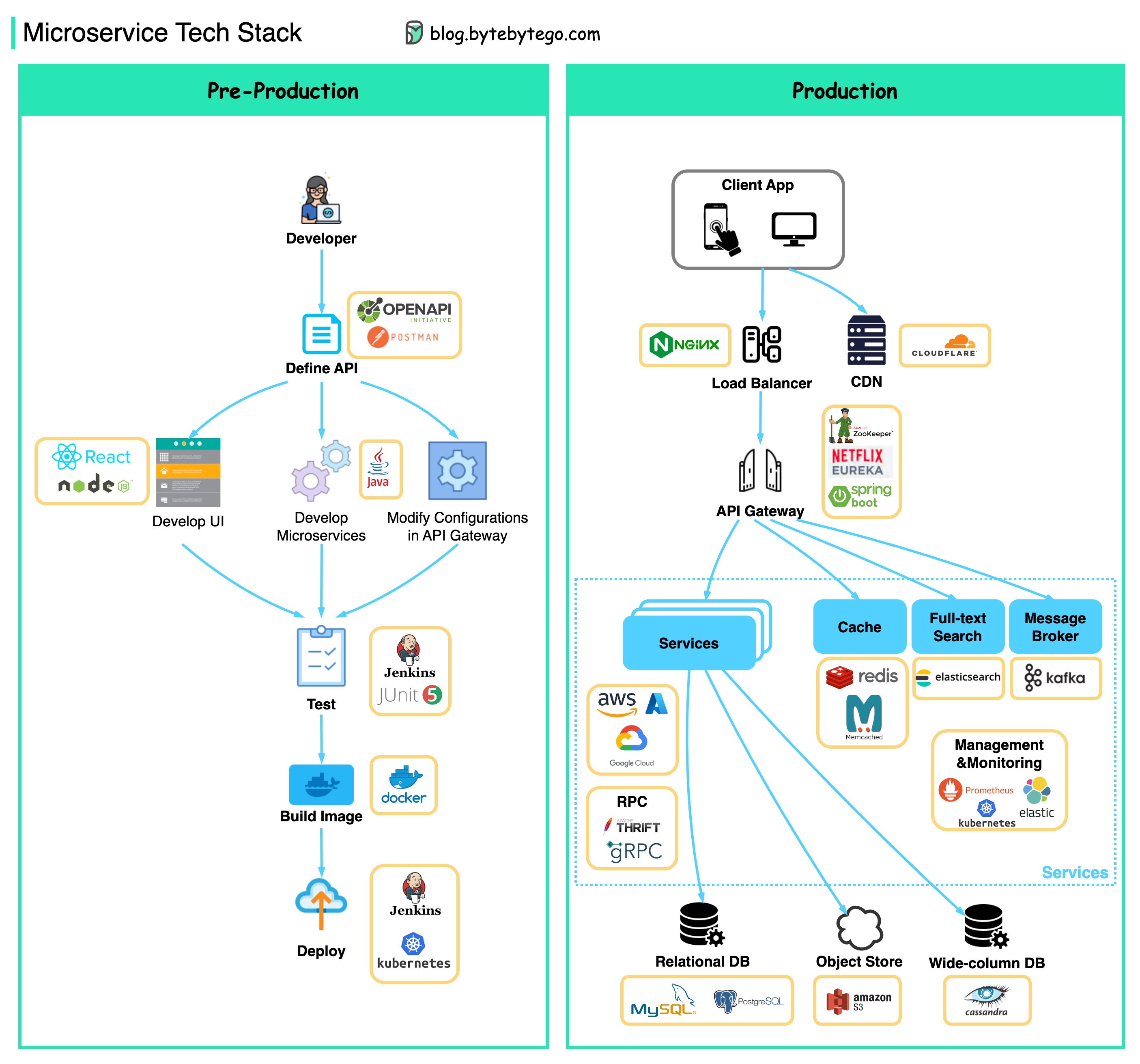
▶️ 𝐏𝐫𝐞-𝐏𝐫𝐨𝐝𝐮𝐜𝐭𝐢𝐨𝐧
- 定义应用程序接口(API)–这将在前台和后台之间建立合约。为此,我们可以使用 Postman 或 OpenAPI。
- 开发–Node.js 或 react 用于前端开发,java/python/go 用于后端开发。此外,我们还需要根据 API 定义更改 API 网关中的配置。
- 持续集成 - JUnit 和 Jenkins 用于自动测试。代码打包成 Docker 镜像,并作为微服务部署。
▶️ 𝐏𝐫𝐨𝐝𝐮𝐜𝐭𝐢𝐨𝐧
- NGinx 是负载平衡器的常见选择。Cloudflare 提供 CDN(内容分发网络)。
- API 网关 - 我们可以使用 Spring Boot 作为网关,并使用 Eureka/Zookeeper 进行服务发现。
- 微服务部署在云上。我们可以选择 AWS、Microsoft Azure 或 Google GCP。缓存和全文搜索–Redis 是缓存键值对的常见选择。Elasticsearch 用于全文搜索。
- 通信–为了让服务之间相互通信,我们可以使用 Kafka 或 RPC 消息传递。
- 持久性 - 我们可以使用 MySQL 或 PostgreSQL 作为关系数据库,使用 Amazon S3 作为对象存储。如有必要,我们还可以使用 Cassandra 进行宽列存储。
- 管理与监控 - 为了管理如此多的微服务,常用的运维工具包括 Prometheus、Elastic Stack 和 Kubernetes。
Kafka 为何如此快速
Kafka 的性能得益于许多设计决策。在本篇文章中,我们将重点讨论其中两项。我们认为这两项决定的分量最重。
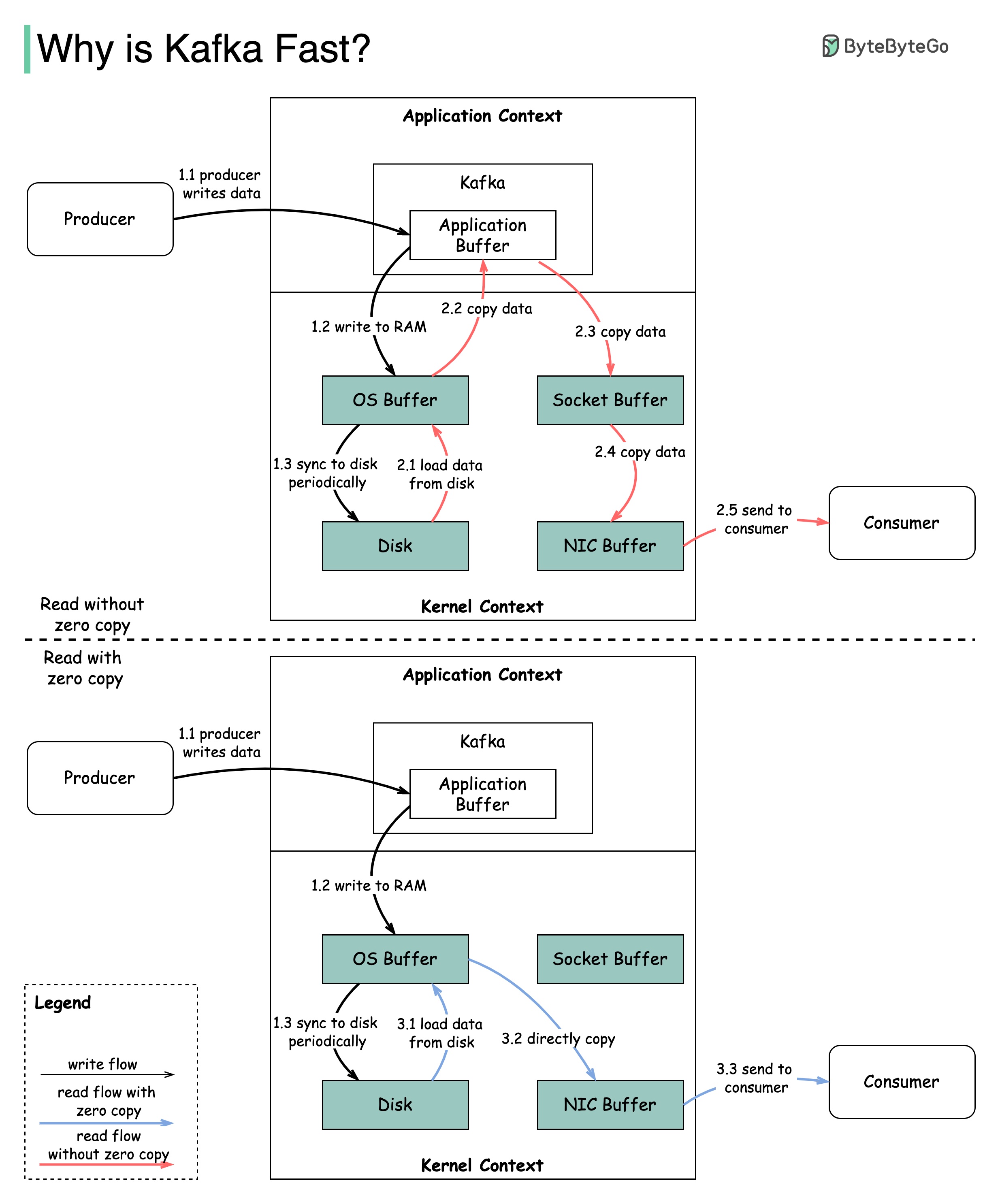
- 首先是 Kafka 对顺序 I/O 的依赖。
- 赋予 Kafka 性能优势的第二个设计选择是其对效率的关注:零拷贝原则。
该图说明了数据如何在生产者和消费者之间传输,以及零拷贝的含义。
- 步骤 1.1 - 1.3:生产者向磁盘写入数据
- 步骤 2:消费者读取不带零拷贝的数据
2.1 数据从磁盘载入操作系统缓存
2.2 数据从操作系统缓存复制到 Kafka 应用程序
2.3 Kafka 应用程序将数据复制到套接字缓冲区
2.4 数据从套接字缓冲区复制到网卡
2.5 网卡向用户发送数据
- 步骤 3:消费者以零拷贝方式读取数据
3.1:3.2 操作系统缓存通过 sendfile() 命令直接将数据复制到网卡 3.3 网卡向用户发送数据
零拷贝是保存应用程序上下文和内核上下文之间多个数据副本的快捷方式。
支付系统
如何学习支付系统?

为什么信用卡被称为 “银行最赚钱的产品”?VISA/Mastercard 如何赚钱?
下图显示了信用卡支付流程的经济学原理。
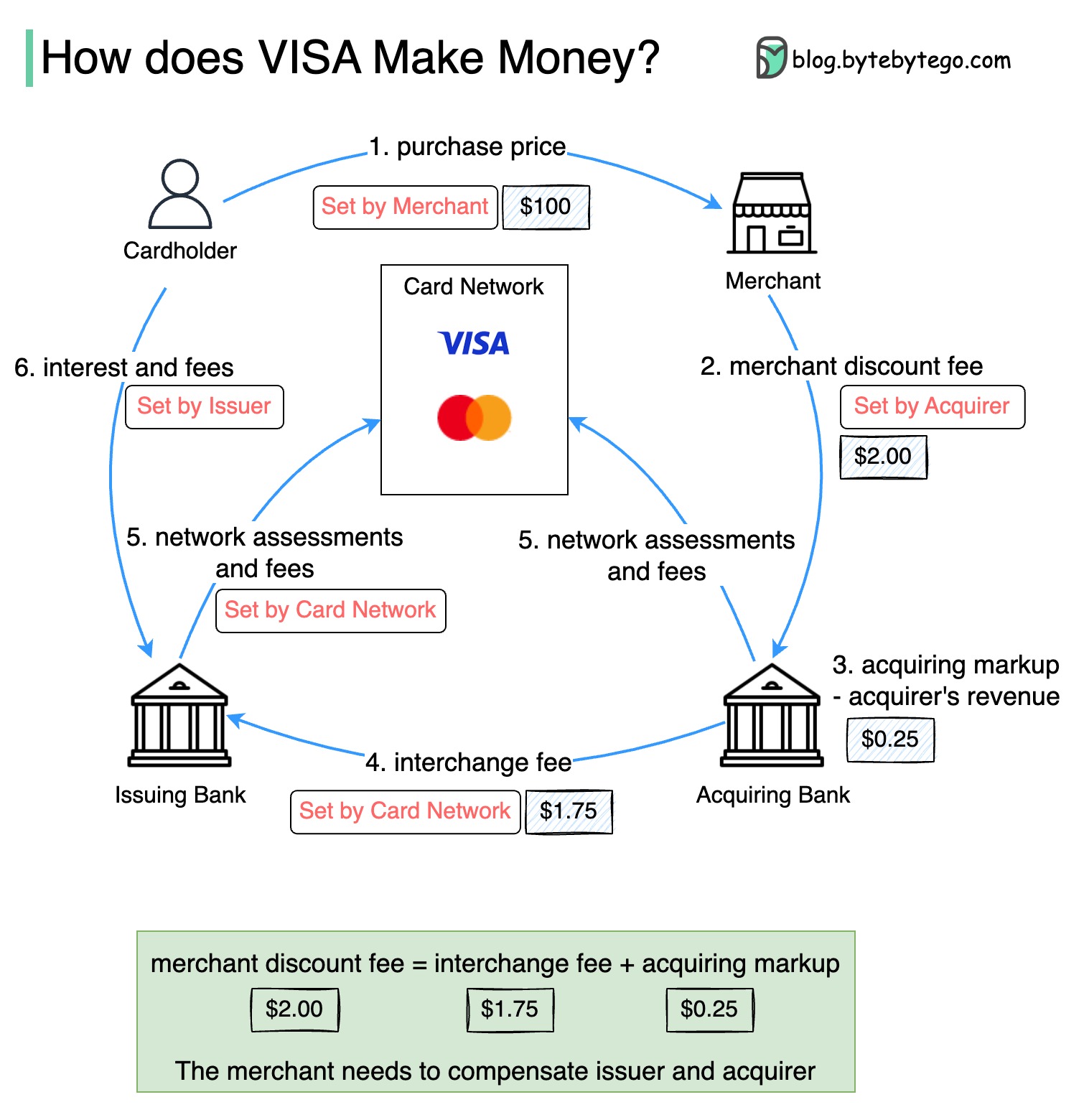
- 持卡人向商家支付 100 美元购买产品。
2.商户因使用信用卡提高了销售额而受益,并需要补偿发卡行和卡网络提供的支付服务。收单银行向商户收取一定费用,称为 “商户折扣费”。
收单银行保留 0.25 美元作为收单加价,1.75 美元作为交换费支付给发卡银行。商户折扣费应包含交换费。
交换费由银行卡网络确定,因为每家发卡银行与每个商家协商费用的效率较低。
- 银行卡网络与每家银行确定网络分摊额和费用,银行每月向银行卡网络支付服务费。例如,VISA 对每次刷卡收取 0.11% 的分摊费,外加 0.0195 美元的使用费。
- 持卡人向发卡银行支付服务费。
为什么要补偿发行银行?
- 即使持卡人未向发卡机构付款,发卡机构也会向商户付款。
- 发卡机构在持卡人向发卡机构付款之前向商户付款。
- 发行机构还有其他运营成本,包括管理客户账户、提供报表、欺诈检测、风险管理、清算和结算等。
当我们在商铺刷卡时,VISA 是如何运作的?
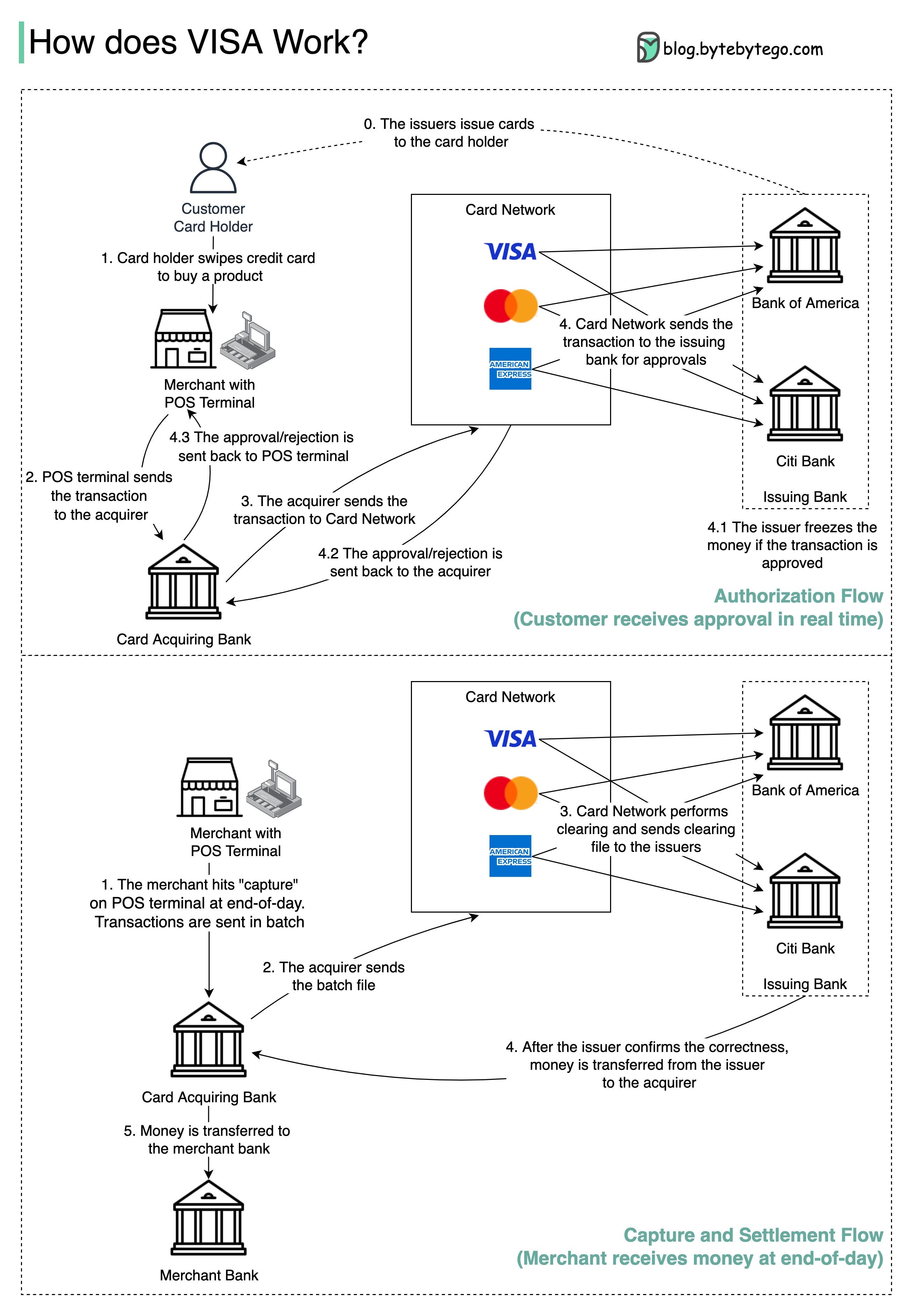
VISA 卡、万事达卡和美国运通卡是清算和结算资金的银行卡网络。收卡银行和发卡银行可以是不同的,而且往往是不同的。如果银行在没有中间人的情况下逐一结算交易,那么每家银行都必须与所有其他银行结算交易。这样做效率很低。
下图显示了 VISA 在信用卡支付流程中的作用。其中涉及两个流程。客户刷卡时发生授权流。捕获和结算流程发生在商家希望在一天结束时拿到钱的时候。
- 授权流程
步骤 0:发卡银行向客户发行信用卡。
步骤 1:持卡人想购买一件商品,在商家店铺的销售点(POS)终端刷卡。
步骤 2:POS 终端将交易发送给提供 POS 终端的收单银行。
步骤 3 和 4:收单银行将交易发送到银行卡网络,也称为银行卡计划。银行卡网络将交易发送给发卡银行审批。
步骤 4.1、4.2 和 4.3:如果交易被批准,发卡银行将冻结资金。批准或拒绝的信息将发回收单银行和 POS 终端。
- 捕获和结算流程
步骤 1 和 2:商户希望在一天结束时收款,因此在 POS 终端上点击 “抓取”。交易被批量发送到收单机构。收单机构将包含交易的批处理文件发送给银行卡网络。
步骤 3:银行卡网络对从不同收单机构收集的交易进行清算,并将清算文件发送给不同的发卡银行。
步骤 4:发卡银行确认清算文件的正确性,并向相关收单银行转账。
步骤 5:收单银行将钱转给商户的银行。
步骤 4:银行卡网络对来自不同收单银行的交易进行清算。清算是对相互抵消的交易进行净额结算,从而减少交易总数的过程。
在此过程中,银行卡网络承担了与每家银行对话的负担,并收取服务费作为回报。
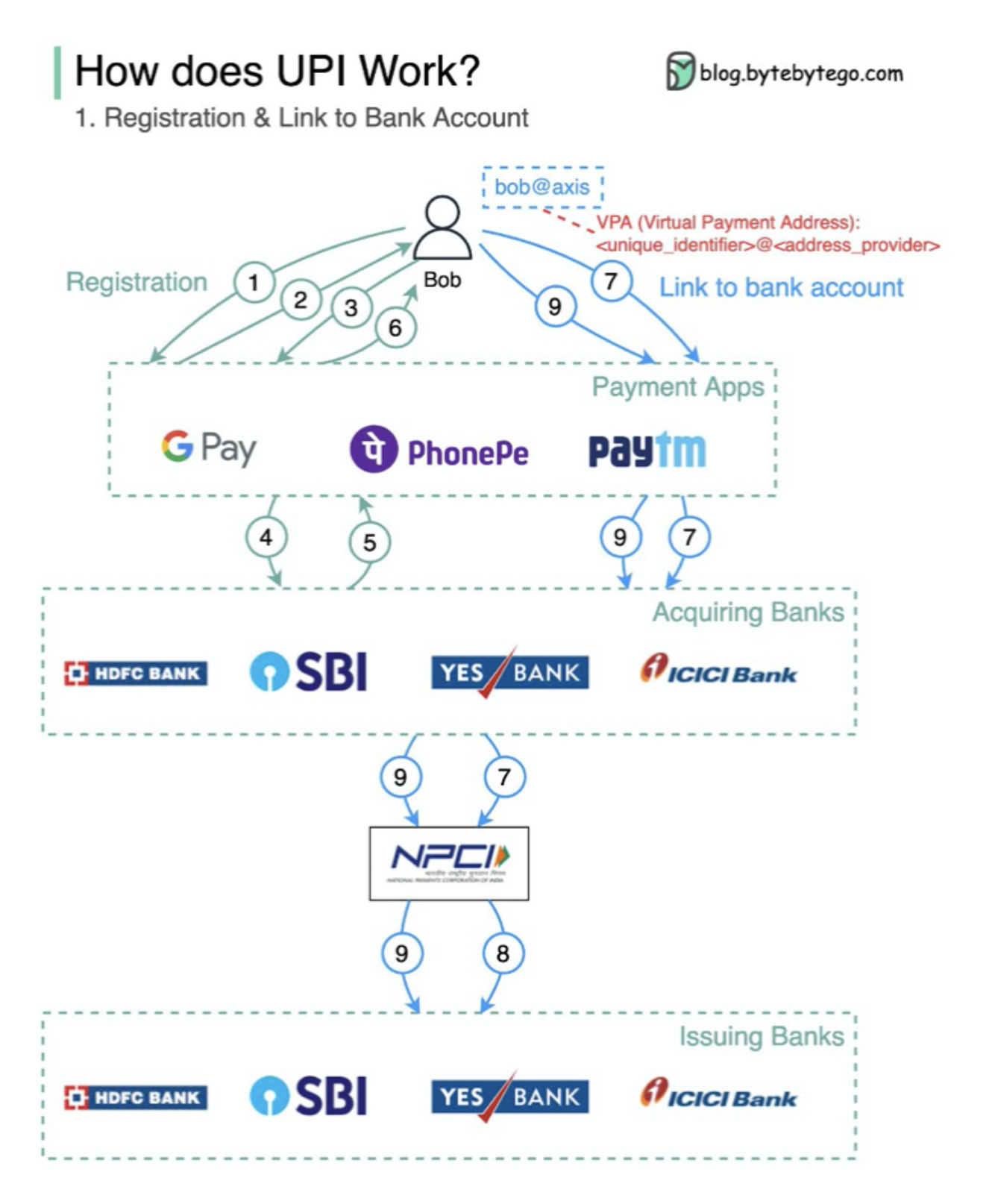
世界各地的支付系统系列(第 1 部分):印度的统一支付接口(UPI)
什么是 UPI?UPI 是印度国家支付公司开发的即时实时支付系统。
目前,它占印度数字零售交易的 60%。
UPI = 支付标记语言 + 互操作支付标准
DevOps
DevOps vs. SRE vs. 平台工程。有什么区别?
DevOps、SRE 和平台工程的概念出现于不同时期,由不同的个人和组织发展而来。
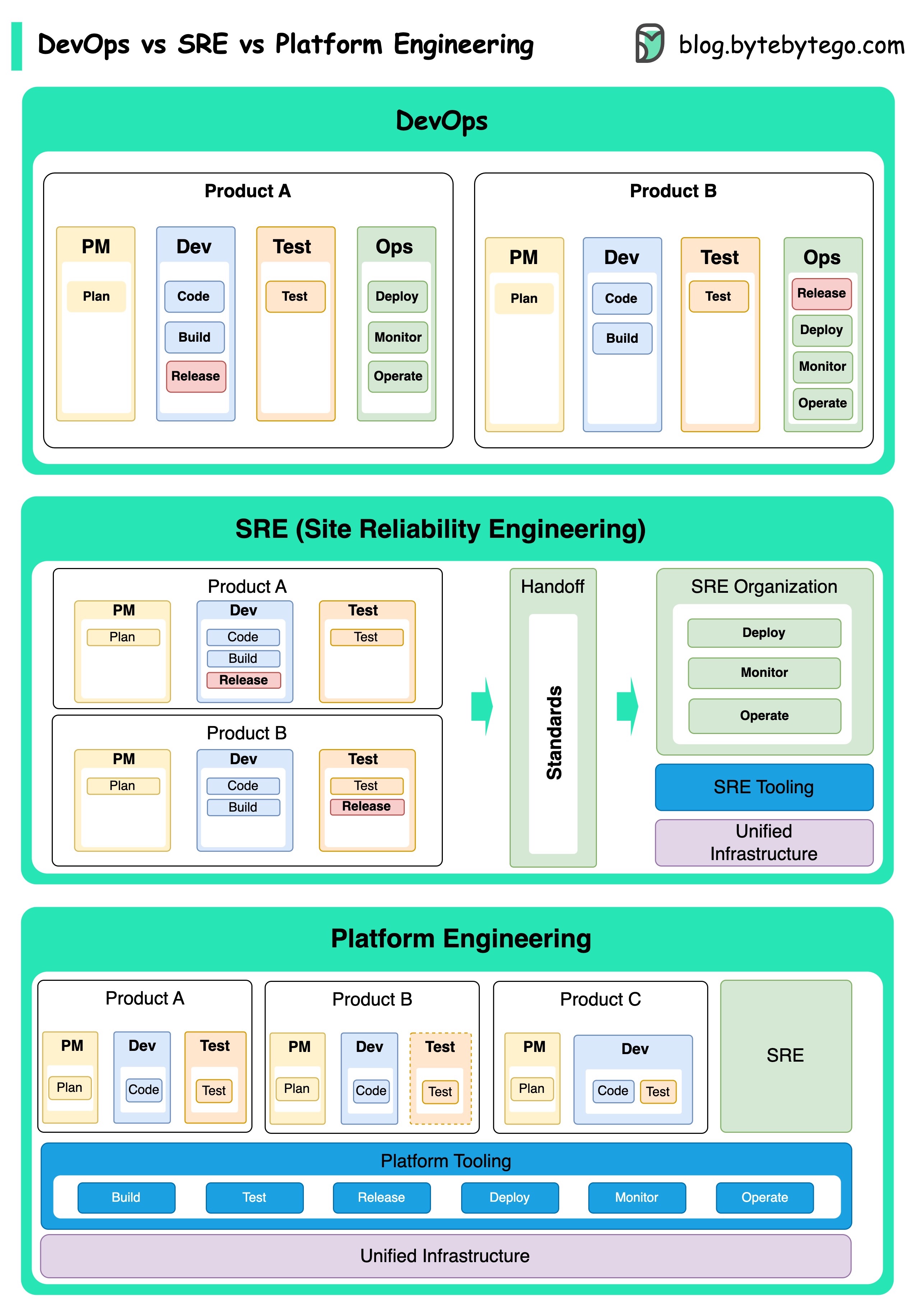
DevOps 这一概念是 Patrick Debois 和 Andrew Shafer 于 2009 年在敏捷大会上提出的。他们试图通过推广协作文化和分担整个软件开发生命周期的责任,来弥合软件开发和运营之间的差距。
SRE,即网站可靠性工程,由谷歌于 2000 年代初首创,旨在解决管理大型复杂系统时遇到的运营挑战。谷歌开发了 SRE 实践和工具,如 Borg 集群管理系统和 Monarch 监控系统,以提高其服务的可靠性和效率。
平台工程是一个较新的概念,建立在 SRE 工程的基础之上。平台工程的确切起源不太清楚,但一般认为它是 DevOps 和 SRE 实践的延伸,重点是为产品开发提供一个支持整个业务视角的综合平台。
值得注意的是,虽然这些概念出现的时间不同。它们都与改善软件开发和运营中的协作、自动化和效率这一更广泛的趋势有关。
什么是 k8s(Kubernetes)?
K8s 是一个容器协调系统。它用于容器部署和管理。它的设计深受谷歌内部系统 Borg 的影响。

k8s 集群由一组运行容器化应用程序的工作机器(称为节点)组成。每个集群至少有一个工作节点。
工作节点托管作为应用程序工作负载组件的 Pod。控制平面管理集群中的工作节点和 Pod。在生产环境中,控制平面通常在多台计算机上运行,集群通常运行多个节点,以提供容错和高可用性。
- 控制平面组件
- 应用程序接口服务器
API 服务器与 k8s 集群中的所有组件对话。Pod 上的所有操作都是通过与 API 服务器对话来执行的。
- 调度员
调度程序会监控 pod 的工作负载,并为新创建的 pod 分配负载。
- 控制经理
控制器管理器运行控制器,包括节点控制器、作业控制器、EndpointSlice 控制器和服务帐户控制器。
- 其他
etcd 是一个键值存储,用作 Kubernetes 所有集群数据的后备存储。
- 节点
- 豆荚
pod 是一组容器,是 k8s 管理的最小单位。pod 中的每个容器都有一个 IP 地址。
-
Kubelet
在集群中每个节点上运行的代理。它能确保容器在 Pod 中运行。
-
Kube 代理
Kube-proxy 是一种网络代理,可在集群中的每个节点上运行。它会路由从服务进入节点的流量。它将工作请求转发给正确的容器。
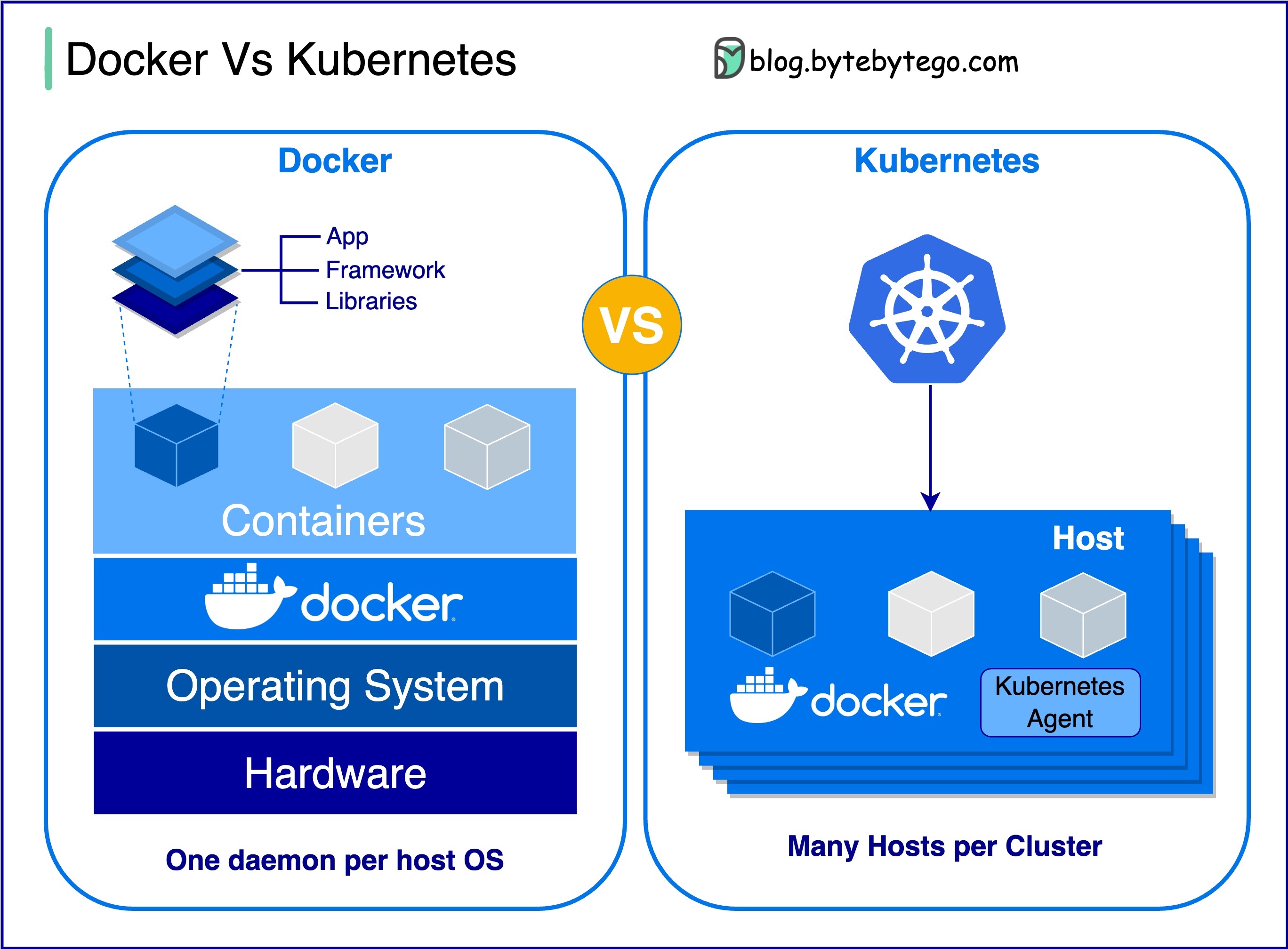
Docker 与 Kubernetes。我们应该使用哪一个?
 什么是 Docker?
什么是 Docker?
Docker 是一个开源平台,可让你在隔离的容器中打包、分发和运行应用程序。它专注于容器化,提供封装应用程序及其依赖关系的轻量级环境。
什么是 Kubernetes?
Kubernetes 通常被称为 K8s,是一个开源容器编排平台。它为跨节点集群的容器化应用程序的自动化部署、扩展和管理提供了一个框架。
两者有何不同?
DockerDocker 在单个操作系统主机上的单个容器级别运行。
您必须手动管理每台主机,而且为多个相关容器设置网络、安全策略和存储可能非常复杂。
KubernetesKubernetes 在集群级别运行。它管理多个主机上的多个容器化应用程序,为负载平衡、扩展和确保应用程序的理想状态等任务提供自动化。
简而言之,Docker 专注于容器化和在单个主机上运行容器,而 Kubernetes 则擅长在主机集群中大规模管理和协调容器。
Docker 如何运行?
下图显示了 Docker 的架构,以及当我们运行 “docker build”、“docker pull “和 “docker run “时它是如何工作的。
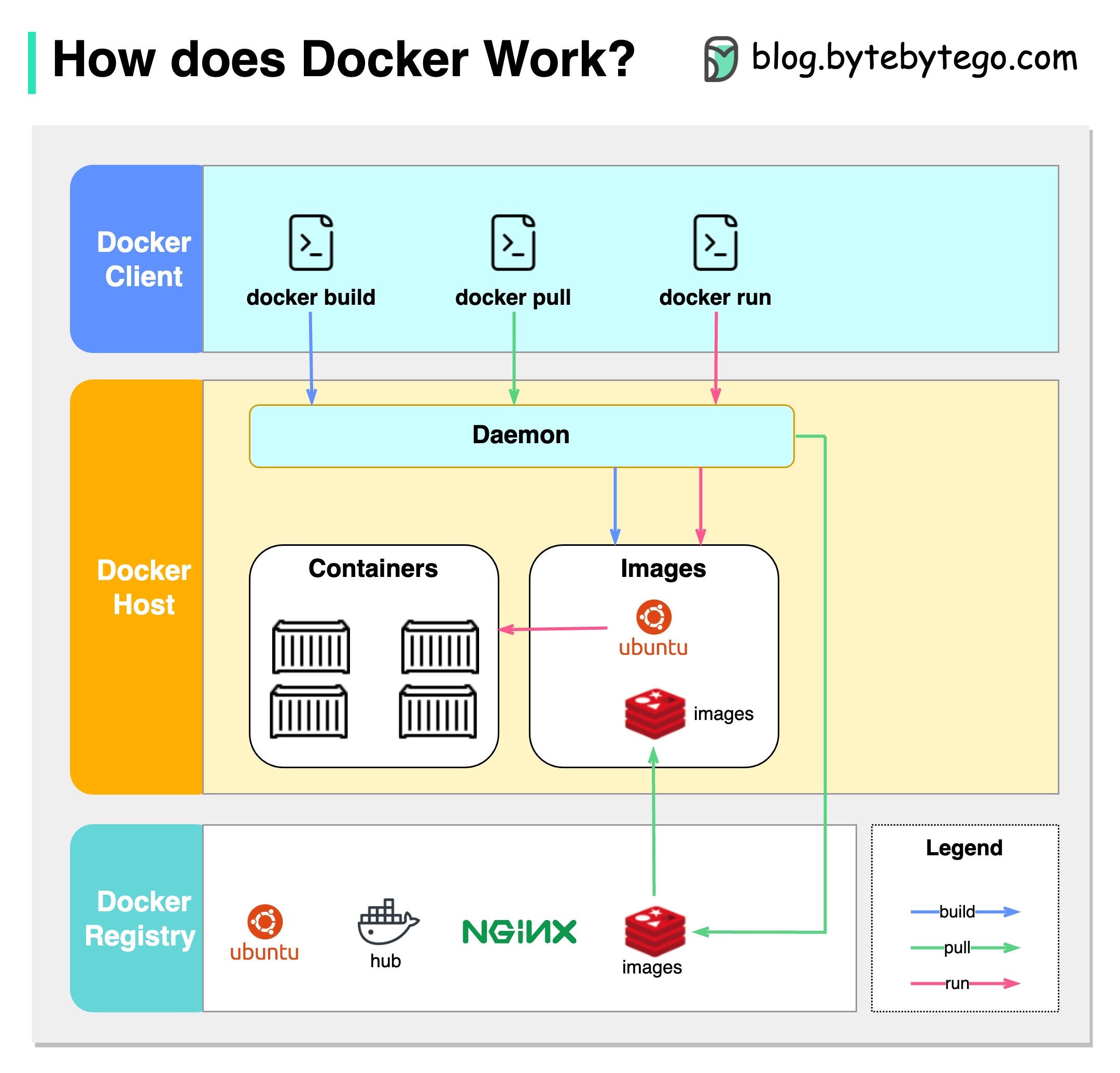
Docker 架构有 3 个组成部分:
- Docker 客户端
docker 客户端与 Docker 守护进程对话。
- Docker 主机
Docker 守护进程会侦听 Docker API 请求,并管理映像、容器、网络和卷等 Docker 对象。
- Docker 注册表
Docker 注册表存储 Docker 映像。Docker Hub 是一个公共注册表,任何人都可以使用。
让我们以 “docker run “命令为例。
- Docker 从注册表中提取映像。
- Docker 会创建一个新容器。
- Docker 会为容器分配一个读写文件系统。
- Docker 会创建一个网络接口,将容器连接到默认网络。
- Docker 启动容器
GIT
Git 命令的工作原理
首先,必须确定代码的存储位置。通常的假设是只有两个位置,一个在 Github 等远程服务器上,另一个在我们的本地机器上。然而,这并不完全准确。Git 在我们的机器上有三个本地存储空间,这意味着我们的代码可以在四个地方找到:
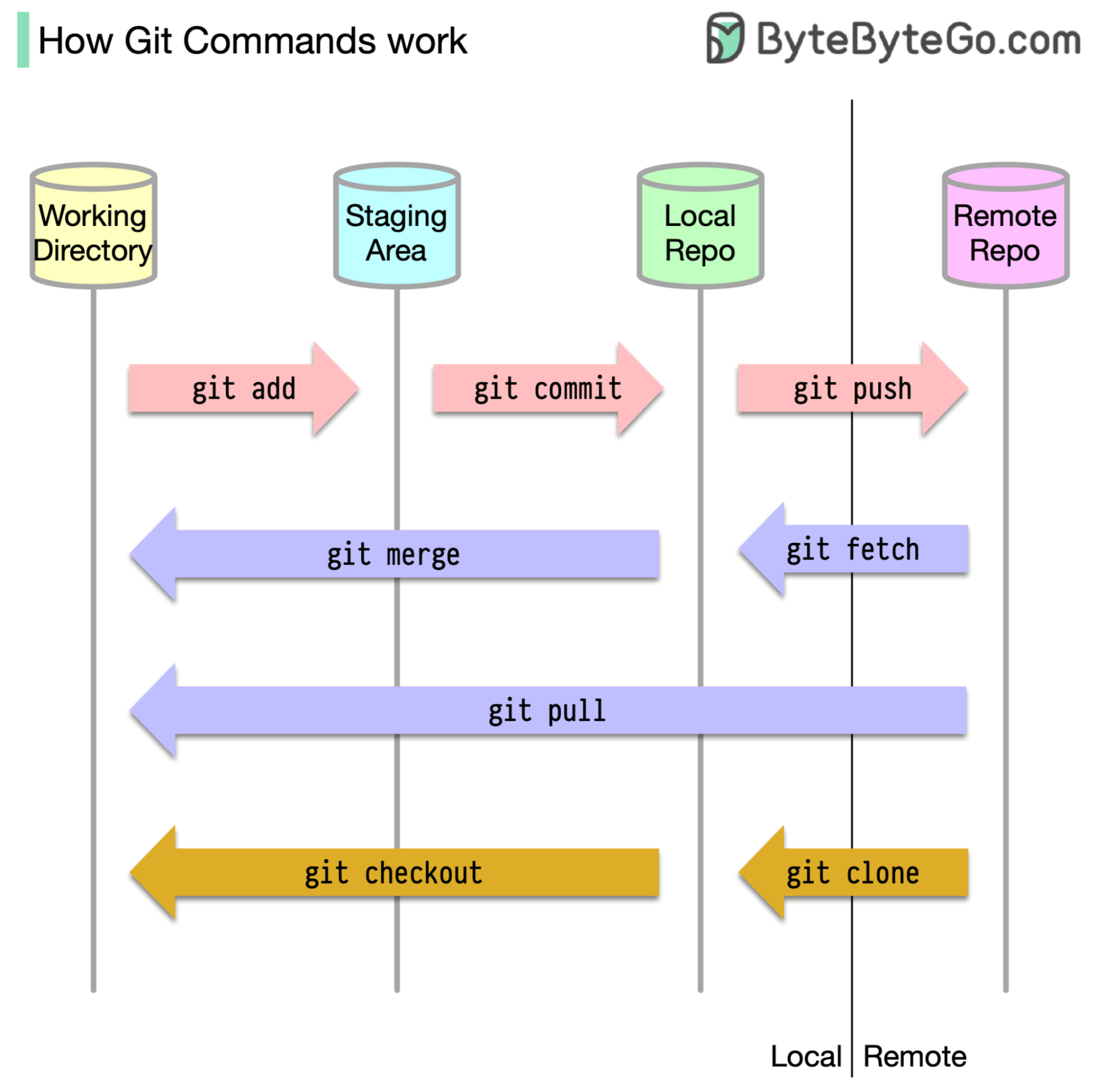
- 工作目录:我们编辑文件的地方
- 暂存区:为下一次提交保存文件的临时位置
- 本地版本库:包含已提交的代码
- 远程存储库:存储代码的远程服务器
大多数 Git 命令主要是在这四个位置之间移动文件。
Git 如何工作?
下图显示了 Git 的工作流程。
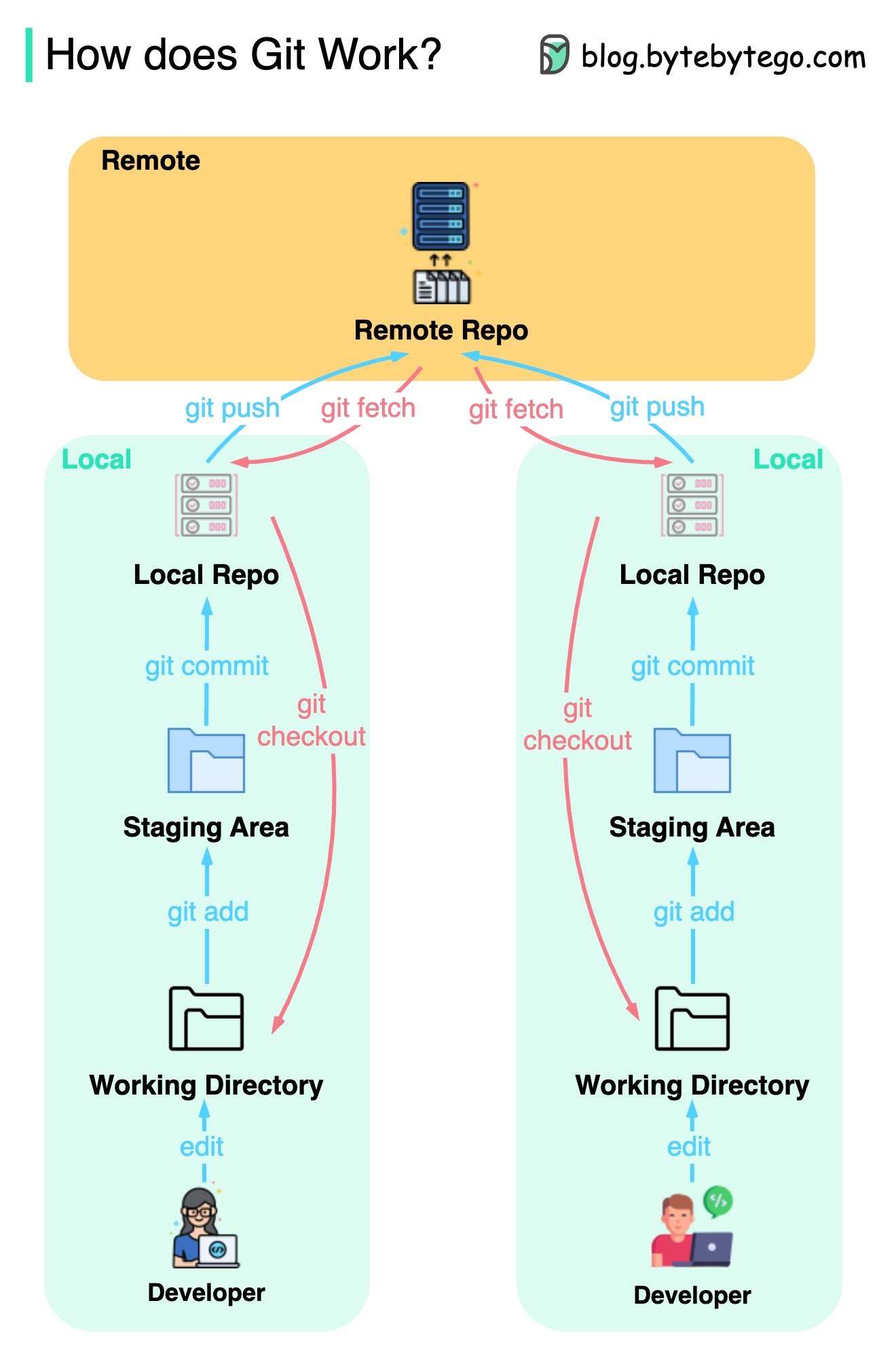
Git 是一种分布式版本控制系统。
每个开发人员都维护一个主版本库的本地副本,并对本地副本进行编辑和提交。
提交速度非常快,因为该操作不与远程版本库交互。
如果远程存储库崩溃,可以从本地存储库恢复文件。
Git merge 与 Git rebase
有哪些区别?
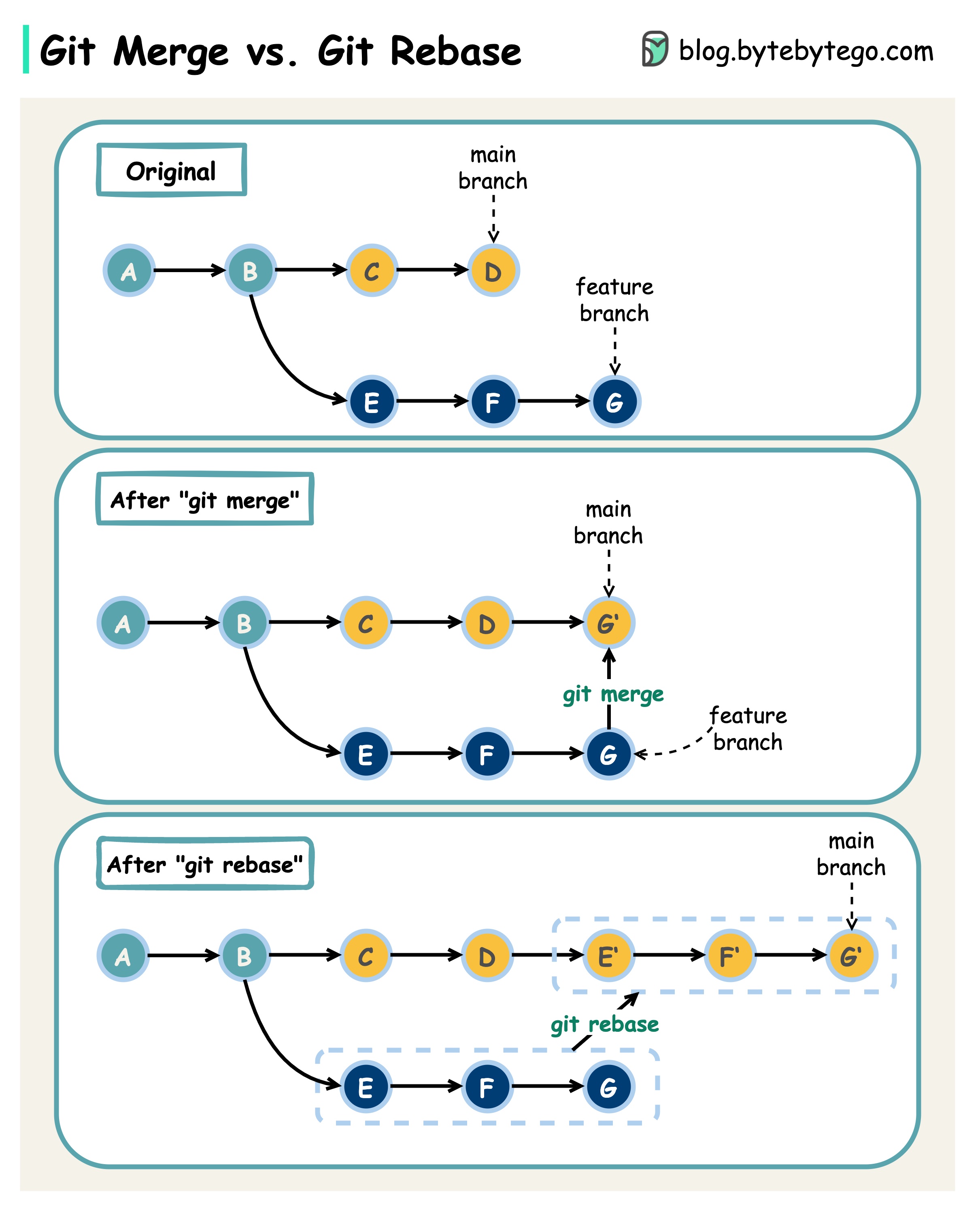
当我们从一个 Git 分支合并改动到另一个分支时,可以使用 “git merge “或 “git rebase”。下图显示了这两个命令的工作原理。
Git 合并
这样就在主分支中创建了一个新的提交 G’。G’ 绑定了主分支和特性分支的历史。
Git 合并是非破坏性的。主分支和特性分支都不会改变。
Git 重定向
Git rebase 会将特性分支的历史移到主分支的头部。它会为特性分支中的每个提交创建新的提交 E’、F’和 G’。
rebase 的好处是它有一个线性的提交历史。
如果不遵守 “git rebase 黄金法则”,重定向可能会很危险。
Git 重置的黄金法则
切勿在公共分支机构使用!
云服务
不同云服务的小抄(2023 年版)

什么是云原生?
下图显示了自 20 世纪 80 年代以来架构和流程的演变。
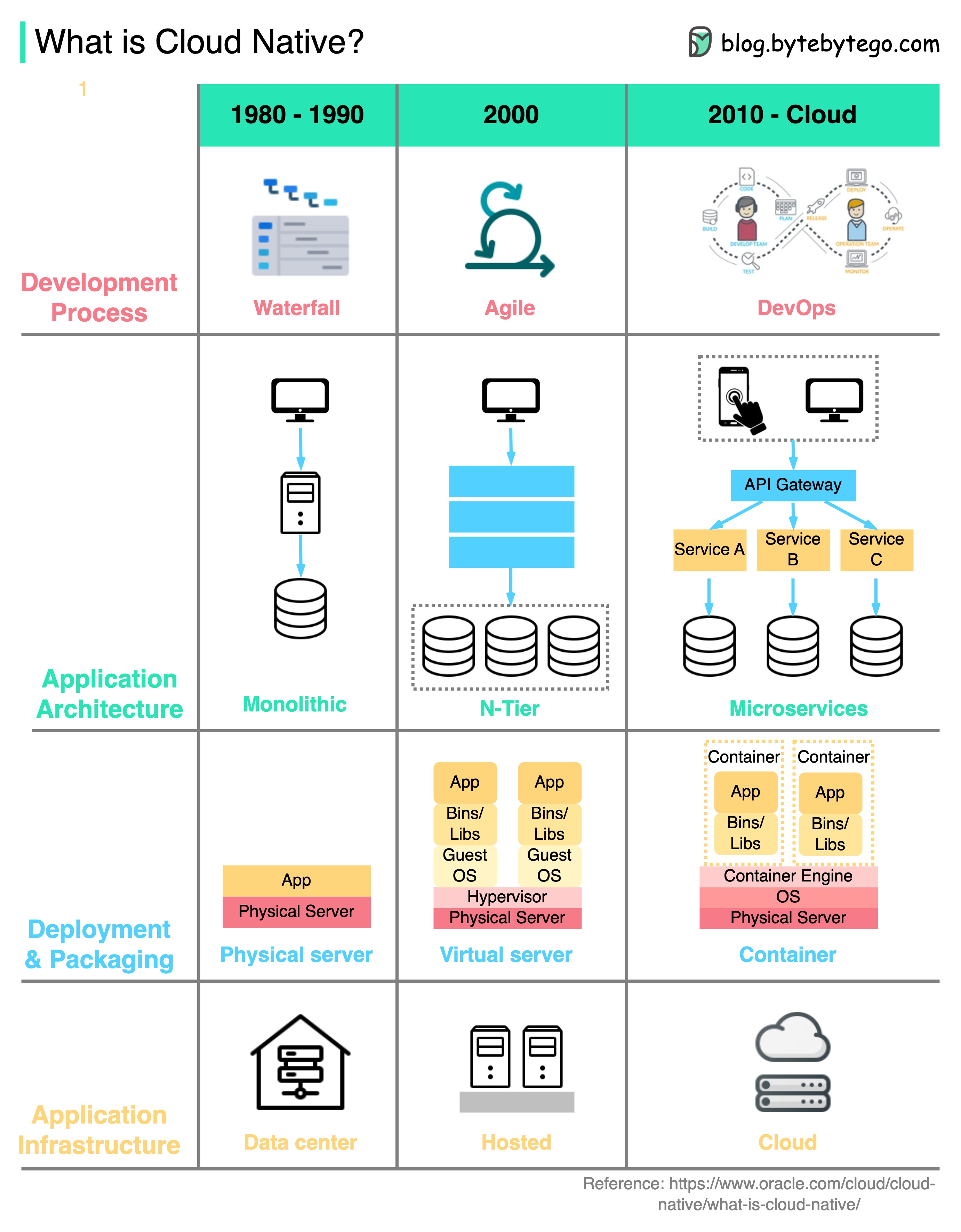
企业可以使用云原生技术在公共云、私有云和混合云上构建和运行可扩展的应用程序。
这意味着应用程序在设计上充分利用了云功能,因此它们能够承受负载并易于扩展。
云原生包括 4 个方面:
- 发展进程
从瀑布式到敏捷式,再到 DevOps。
-
应用架构
架构已从单体变为微服务。每个服务都设计得很小,以适应云容器中有限的资源。
-
部署和包装
以前,应用程序都部署在物理服务器上。2000 年左右,对延迟不敏感的应用程序通常部署在虚拟服务器上。而云原生应用程序则被打包成 docker 镜像,部署在容器中。
-
应用基础设施
应用程序被大规模部署在云基础设施上,而不是自托管服务器上。
开发人员生产力工具
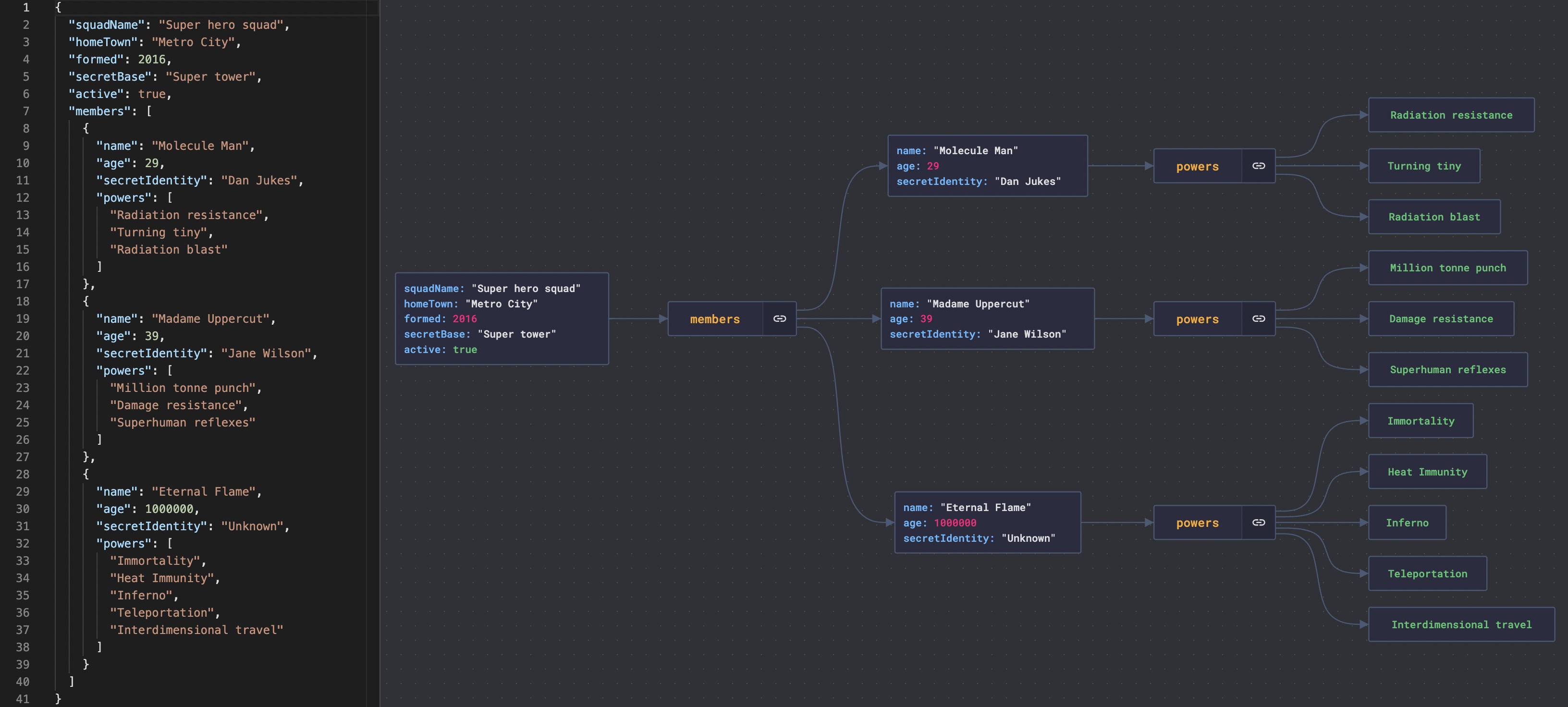
可视化 JSON 文件
嵌套的 JSON 文件很难读取。
JsonCrack 可从 JSON 文件生成图表,并使其易于阅读。
此外,生成的图表还可以下载为图片。
自动将代码转化为架构图
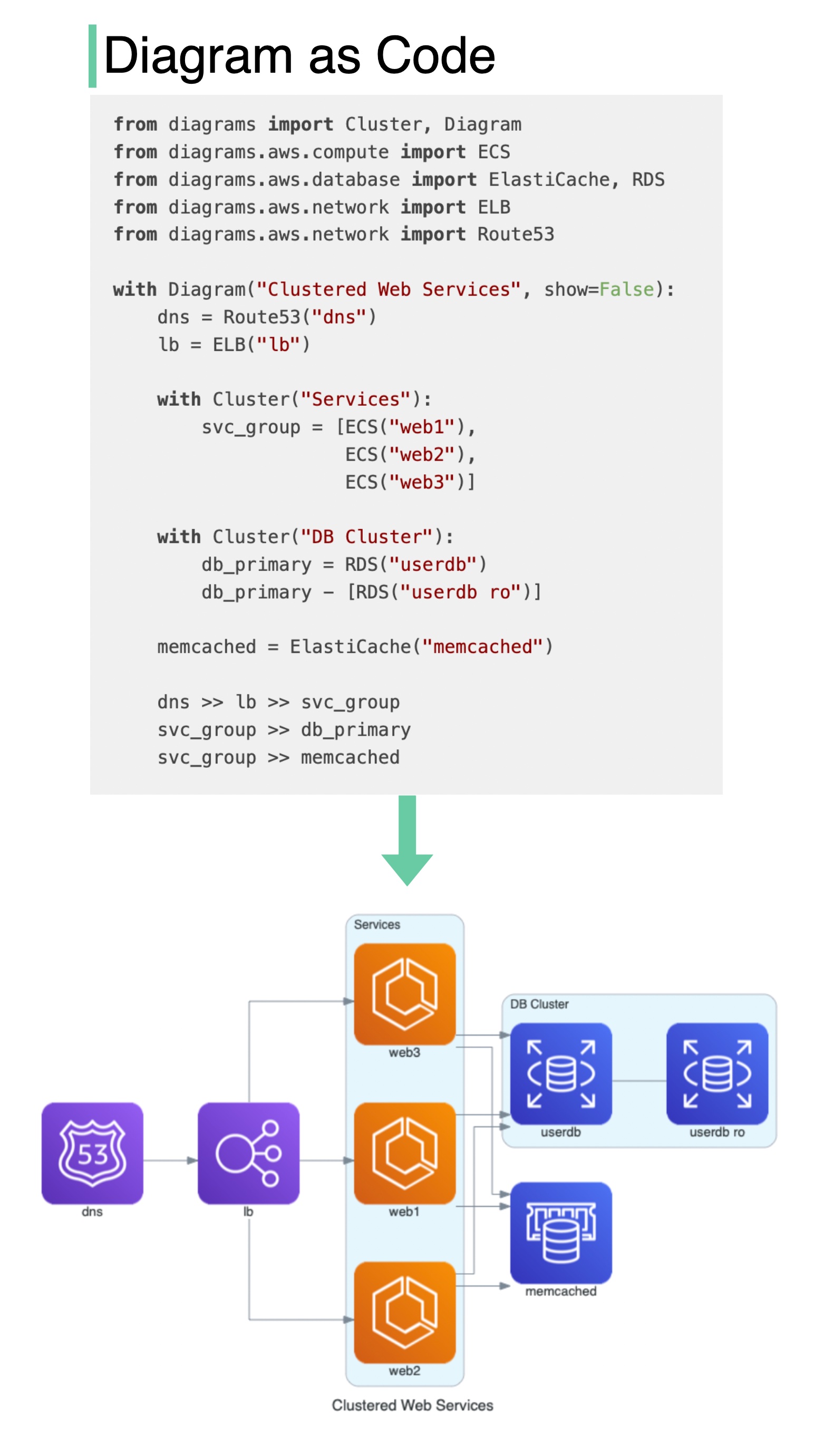
它有什么作用?
- 用 Python 代码绘制云系统架构图。
- 图表也可以直接在 Jupyter 笔记本中呈现。
- 无需设计工具。
- 支持以下提供商:AWS、Azure、GCP、Kubernetes、阿里云、甲骨文云等。
Linux]
Linux 文件系统说明
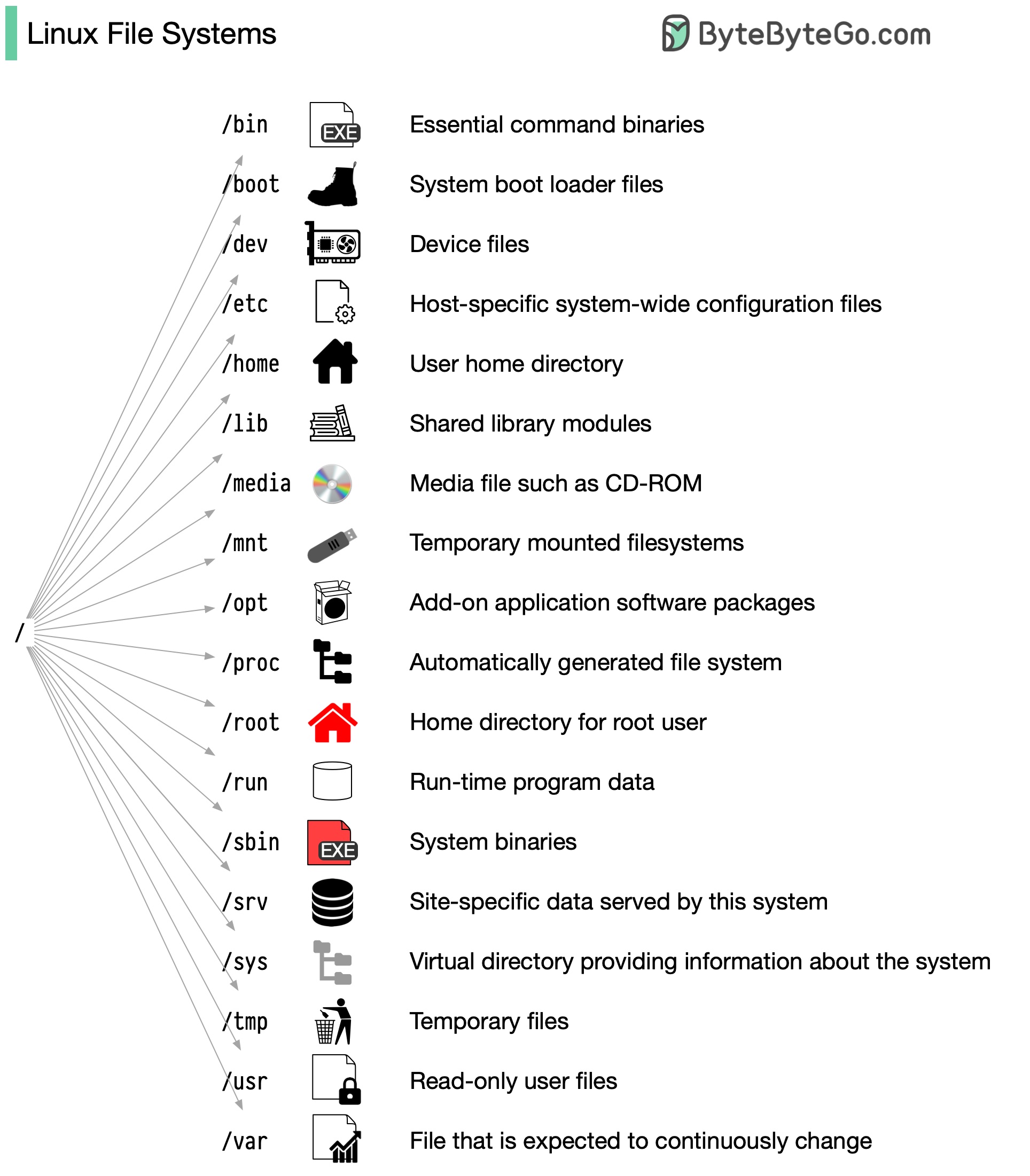
过去,Linux 文件系统就像一个无序的小镇,人们随心所欲地建造自己的房屋。然而,1994 年,文件系统层次标准(FHS)的引入为 Linux 文件系统带来了秩序。
通过实施像 FHS 这样的标准,软件可以确保在不同的 Linux 发行版中使用一致的布局。不过,并非所有 Linux 发行版都严格遵守这一标准。它们通常会融入自己独特的元素或迎合特定的要求。要熟练掌握这一标准,可以从探索开始。使用 “cd “等命令进行导航,使用 “ls “命令列出目录内容。将文件系统想象成一棵树,从根 (/) 开始。随着时间的推移,这将成为你的第二天性,使你成为一名熟练的 Linux 管理员。
你应该知道的 18 种最常用 Linux 命令
Linux 命令是与操作系统交互的指令。它们有助于管理文件、目录、系统进程和系统的许多其他方面。你需要熟悉这些命令,才能高效地浏览和维护基于 Linux 的系统。
下图显示了常用的 Linux 命令:

- ls - 列出文件和目录
- cd - 更改当前目录
- mkdir - 创建新目录
- rm - 删除文件或目录
- cp - 复制文件或目录
- mv - 移动或重命名文件或目录
- chmod - 更改文件或目录权限
- grep - 在文件中搜索模式
- 查找 - 搜索文件和目录
- tar - 处理 tar 包档案文件
- vi - 使用文本编辑器编辑文件
- cat - 显示文件内容
- top - 显示进程和资源使用情况
- ps - 显示进程信息
- kill - 通过发送信号终止进程
- du - 估算文件空间使用情况
- ifconfig - 配置网络接口
- ping - 测试主机之间的网络连通性
安全
HTTPS 如何工作?
超文本传输协议安全(HTTPS)是超文本传输协议(HTTP)的扩展。HTTPS 使用传输层安全(TLS)传输加密数据。

如何加密和解密数据?
步骤 1 - 客户端(浏览器)和服务器建立 TCP 连接。
第 2 步 - 客户端向服务器发送 “客户端你好 “信息。该信息包含一组必要的加密算法(密码套件)和可支持的最新 TLS 版本。服务器响应 “服务器你好”,以便浏览器知道自己是否支持这些算法和 TLS 版本。
然后,服务器将 SSL 证书发送给客户端。证书包含公钥、主机名、有效期等信息。客户端验证证书。
第 3 步 - 验证 SSL 证书后,客户端生成会话密钥,并使用公钥对其进行加密。服务器接收加密的会话密钥,并用私钥解密。
第 4 步 - 既然客户端和服务器都持有相同的会话密钥(对称加密),加密数据就会在安全的双向信道中传输。
为什么 HTTPS 会在数据传输过程中切换到对称加密?主要有两个原因:
- 安全性:非对称加密只能单向进行。这意味着,如果服务器尝试将加密数据发送回客户端,任何人都可以使用公开密钥解密数据。
- 服务器资源:非对称加密增加了大量数学开销。它不适合长时间的数据传输。
Oauth 2.0 简明解释
OAuth 2.0 是一个强大而安全的框架,它允许不同的应用程序代表用户进行安全交互,而无需共享敏感凭据。

参与 OAuth 的实体包括用户、服务器和身份提供者(IDP)。
OAuth 令牌能做什么?
使用 OAuth 时,您会得到一个代表您的身份和权限的 OAuth 令牌。这个令牌可以做几件重要的事情:
单点登录(SSO):有了 OAuth 令牌,只需登录一次,就能登录多个服务或应用程序,让生活更轻松、更安全。
跨系统授权:OAuth 令牌可让您在不同系统间共享授权或访问权限,这样您就不必到处单独登录。
访问用户配置文件:拥有 OAuth 令牌的应用程序可以访问您允许访问的用户配置文件的某些部分,但不会看到所有内容。
请记住,OAuth 2.0 的目的是保证您和您的数据安全,同时让您的在线体验在不同的应用程序和服务之间无缝衔接、轻松自如。
四大认证机制形式
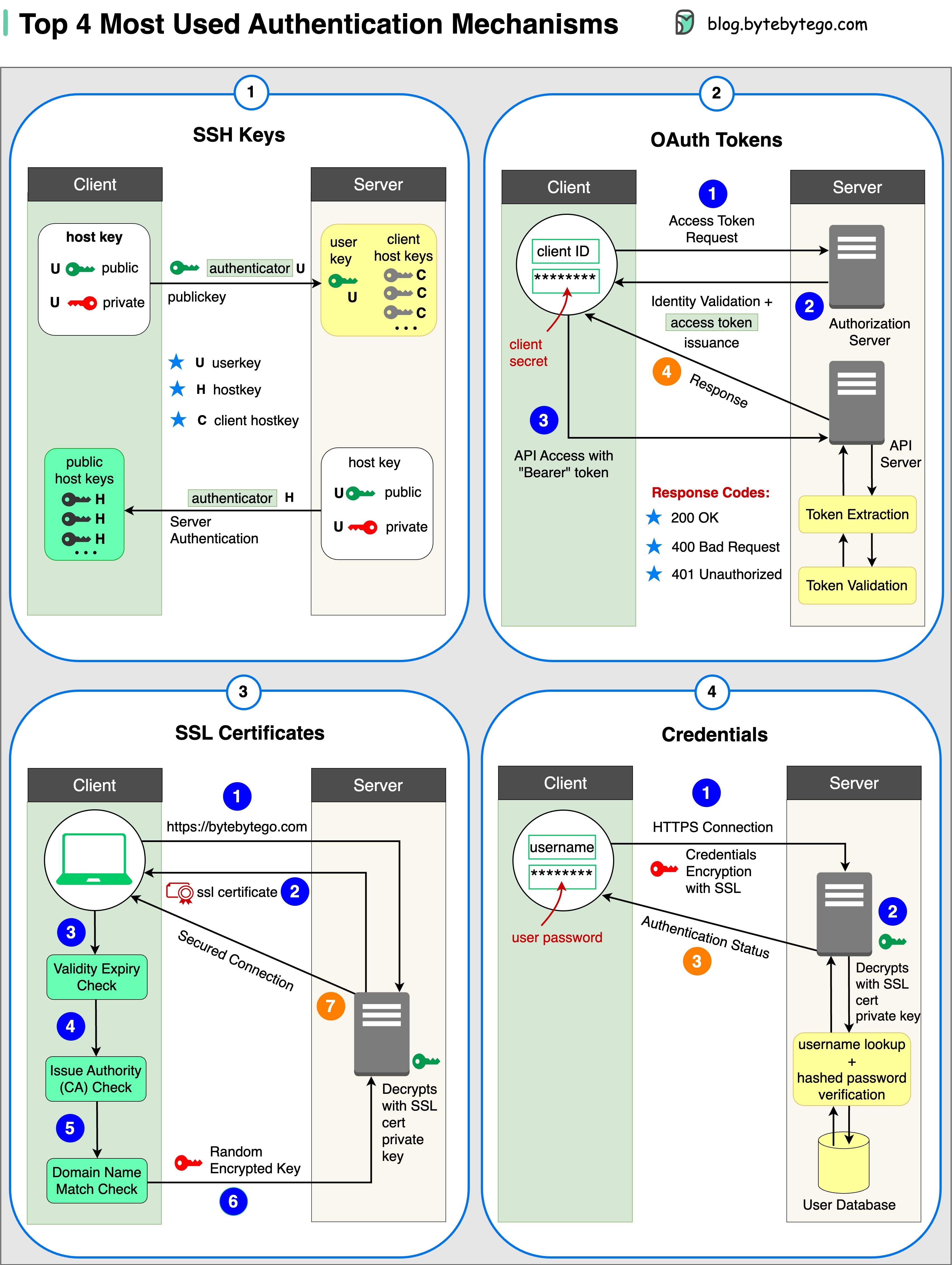
- SSH 密钥:
加密密钥用于安全访问远程系统和服务器
- OAuth 标记:
可在第三方应用程序上有限访问用户数据的令牌
- SSL 证书:
数字证书确保服务器和客户端之间的通信安全和加密
- 证书
用户身份验证信息用于验证和授予对各种系统和服务的访问权限
会话、Cookie、JWT、令牌、SSO 和 OAuth 2.0 - 它们是什么?
这些术语都与用户身份管理有关。当你登录一个网站时,你要声明你是谁(身份识别)。你的身份会得到验证(认证),并被授予必要的权限(授权)。过去已经提出了许多解决方案,而且这个清单还在不断扩大。
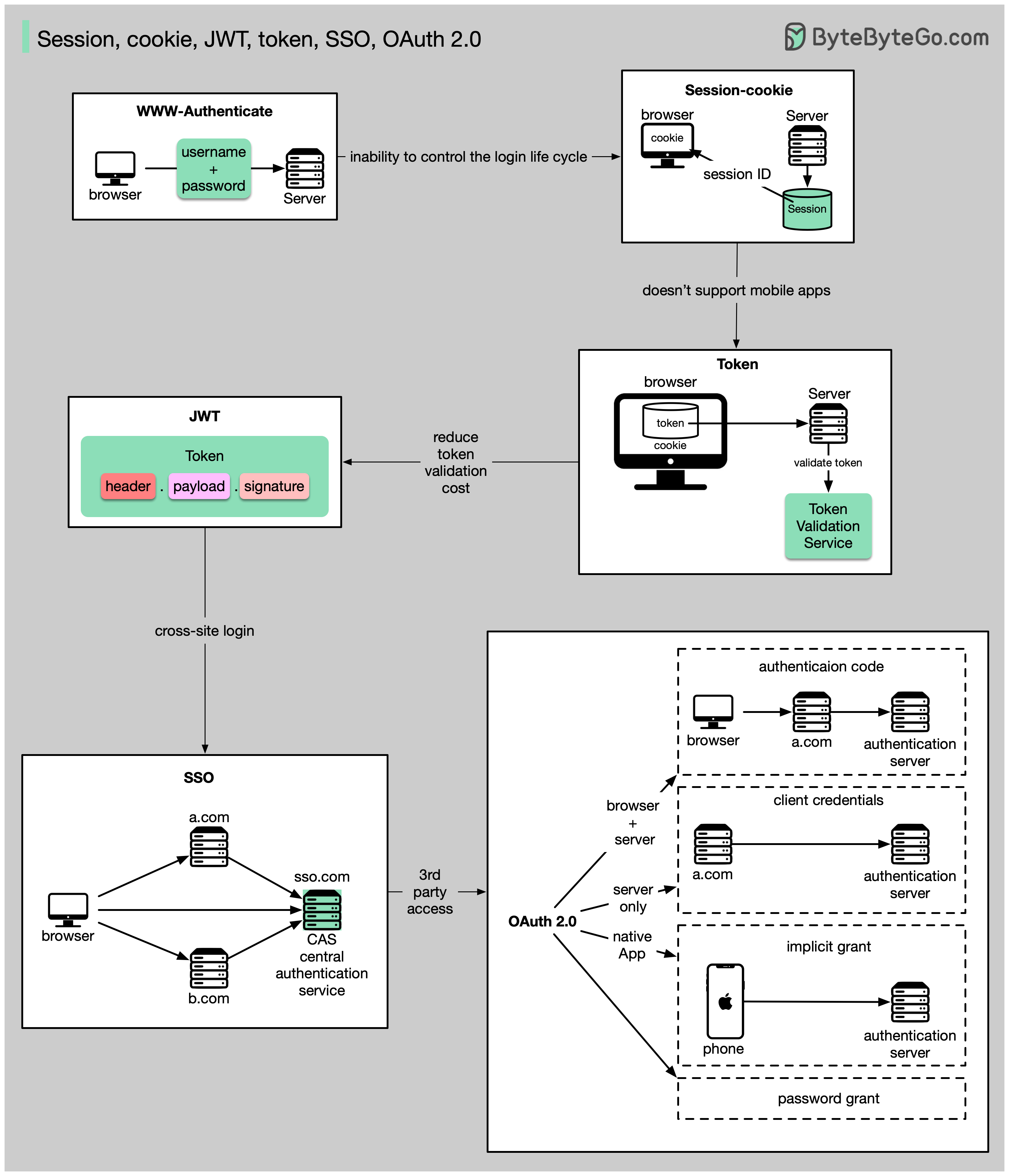
从简单到复杂,这就是我对用户身份管理的理解:
- WWW 身份验证是最基本的方法。浏览器会要求你输入用户名和密码。由于无法控制登录生命周期,这种方法如今已很少使用。
- 会话 Cookie 是对登录生命周期更精细的控制。服务器保存会话存储,浏览器保存会话 ID。cookie 通常只适用于浏览器,对移动应用程序不友好。
- 为了解决兼容性问题,可以使用令牌。客户端向服务器发送令牌,服务器验证令牌。缺点是需要对令牌进行加密和解密,这可能会比较耗时。
- JWT 是表示令牌的标准方式。由于该信息经过数字签名,因此可以验证和信任。由于 JWT 包含签名,因此无需在服务器端保存会话信息。
- 通过使用 SSO(单点登录),您只需登录一次,即可登录多个网站。它使用 CAS(中央验证服务)来维护跨网站信息。
- 通过使用 OAuth 2.0,您可以授权一个网站访问您在另一个网站上的信息。
如何在数据库中安全存储密码以及如何验证密码?

不该做的事
- 用纯文本存储密码不是一个好主意,因为任何有内部访问权限的人都可以看到它们。
- 直接存储密码哈希值是不够的,因为它会受到预计算攻击,如彩虹表。
- 为了减少预计算攻击,我们对密码进行了加盐处理。
盐是什么?
根据 OWASP 指南,“盐是一个随机生成的唯一字符串,作为散列过程的一部分添加到每个密码中”。
如何存储密码和盐值?
- 每个密码的哈希结果都是唯一的。
- 密码可以使用以下格式存储在数据库中:hash(password + salt)。
如何验证密码?
要验证密码,可以通过以下过程:
- 客户输入密码。
- 系统会从数据库中获取相应的盐。
- 系统会将盐添加到密码中并进行散列。我们将散列值称为 H1。
- 系统会比较 H1 和 H2,其中 H2 是存储在数据库中的哈希值。如果两者相同,则密码有效。
向 10 岁的孩子解释 JSON 网络令牌 (JWT)

想象一下,你有一个叫做 JWT 的特殊盒子。在这个盒子里,有三个部分:头、有效载荷和签名。
页眉就像盒子外面的标签。它告诉我们这是什么类型的盒子,以及它是如何固定的。它通常以一种名为 JSON 的格式编写,这是一种使用大括号 { } 和冒号 : 来组织信息的方式。
有效载荷就像您要发送的实际信息或资讯。它可以是你的姓名、年龄或任何其他你想分享的数据。它也是用 JSON 格式编写的,因此很容易理解和使用。现在,签名是保证 JWT 安全的关键。它就像一个特殊的印章,只有发送方才知道如何创建。签名是用密码创建的,有点像口令。这个签名可以确保没有人可以在发送方不知情的情况下篡改 JWT 的内容。
当您要将 JWT 发送到服务器时,您需要将标头、有效载荷和签名放在盒子里。然后发送给服务器。服务器可以很容易地读取标头和有效载荷,以了解您是谁以及您想做什么。
Google Authenticator(或其他类型的双因素身份验证器)如何工作?
当启用双因素身份验证时,Google Authenticator 通常用于登录我们的账户。它如何保证安全?
Google Authenticator 是一款基于软件的验证器,可实现两步验证服务。下图提供了详细信息。
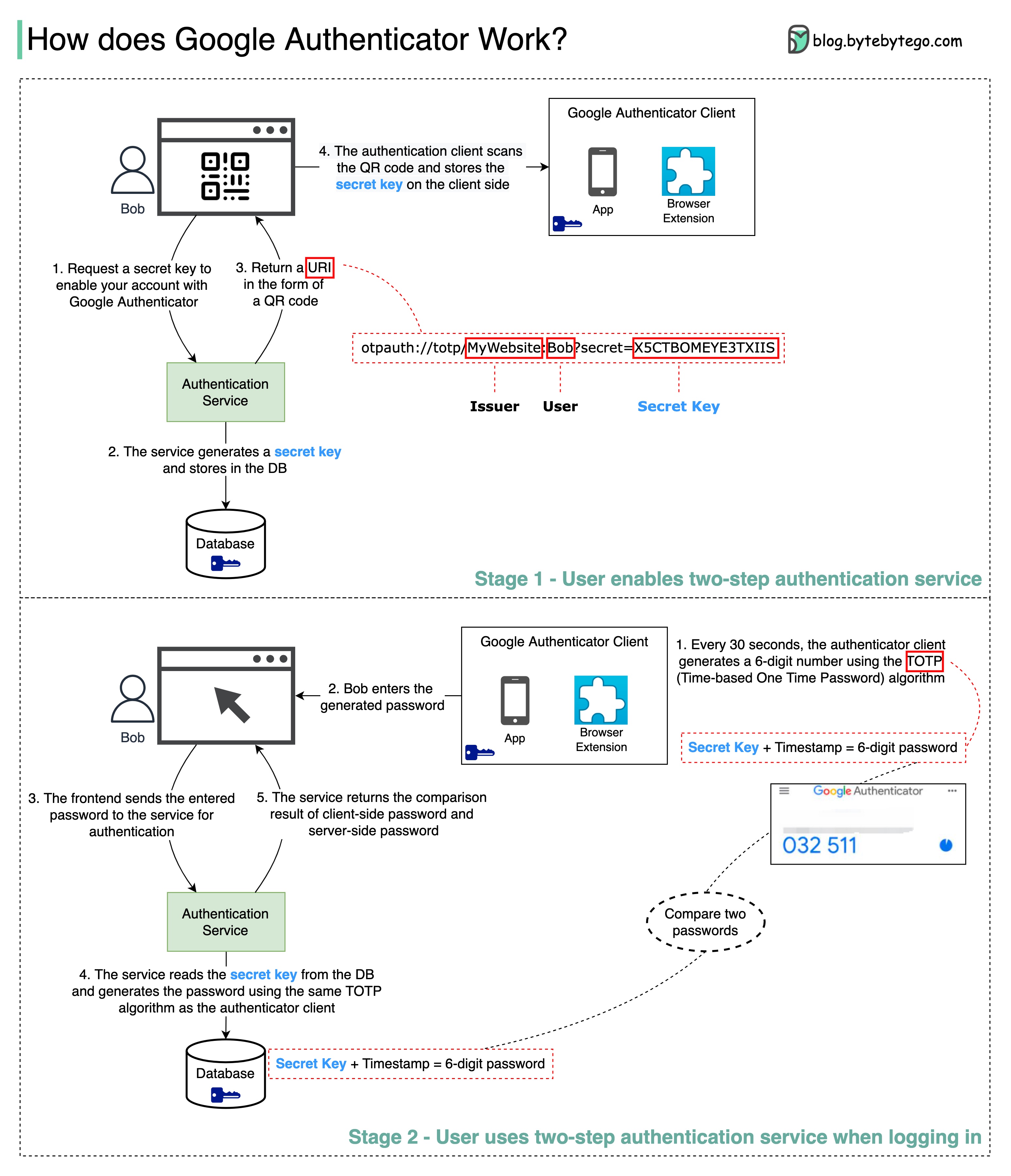
这涉及两个阶段:
- 阶段 1 - 用户启用 Google 两步验证。
- 第 2 阶段 - 用户使用验证器登录等。
让我们来看看这些阶段。
第 1 阶段
步骤 1 和 2:Bob 打开网页,启用两步验证。前端请求输入秘钥。验证服务会为鲍勃生成秘钥,并将其存储在数据库中。
步骤 3:验证服务向前端返回一个 URI。URI 由密钥发放者、用户名和密钥组成。URI 以 QR 码的形式显示在网页上。
步骤 4:然后,鲍勃使用 Google Authenticator 扫描生成的 QR 码。秘钥存储在验证器中。
第 2 阶段 第 1 步和第 2 步:Bob 想通过 Google 两步验证登录一个网站。为此,他需要密码。每隔 30 秒,Google Authenticator 会使用 TOTP(基于时间的一次性密码)算法生成一个 6 位数的密码。鲍勃使用密码进入网站。
步骤 3 和 4:前台将鲍勃输入的密码发送到后台进行验证。身份验证服务从数据库中读取秘钥,并使用与客户端相同的 TOTP 算法生成一个 6 位数密码。
步骤 5:身份验证服务比较客户端和服务器生成的两个密码,并将比较结果返回前端。只有当两个密码匹配时,鲍勃才能继续登录。
这种验证机制安全吗?
-
他人能否获取秘钥?
我们需要确保使用 HTTPS 传输秘钥。验证器客户端和数据库都会存储秘钥,我们需要确保秘钥经过加密。
-
6 位数密码会被黑客猜到吗?
密码有 6 位数字,因此生成的密码有 100 万种可能的组合。另外,密码每 30 秒就会更改一次。如果黑客想在 30 秒内猜出密码,他们每秒需要输入 3 万个密码组合。
真实世界案例研究
Netflix 的技术栈
本文章基于对许多 Netflix 工程博客和开源项目的研究。如果您发现任何不准确之处,请随时告知我们。
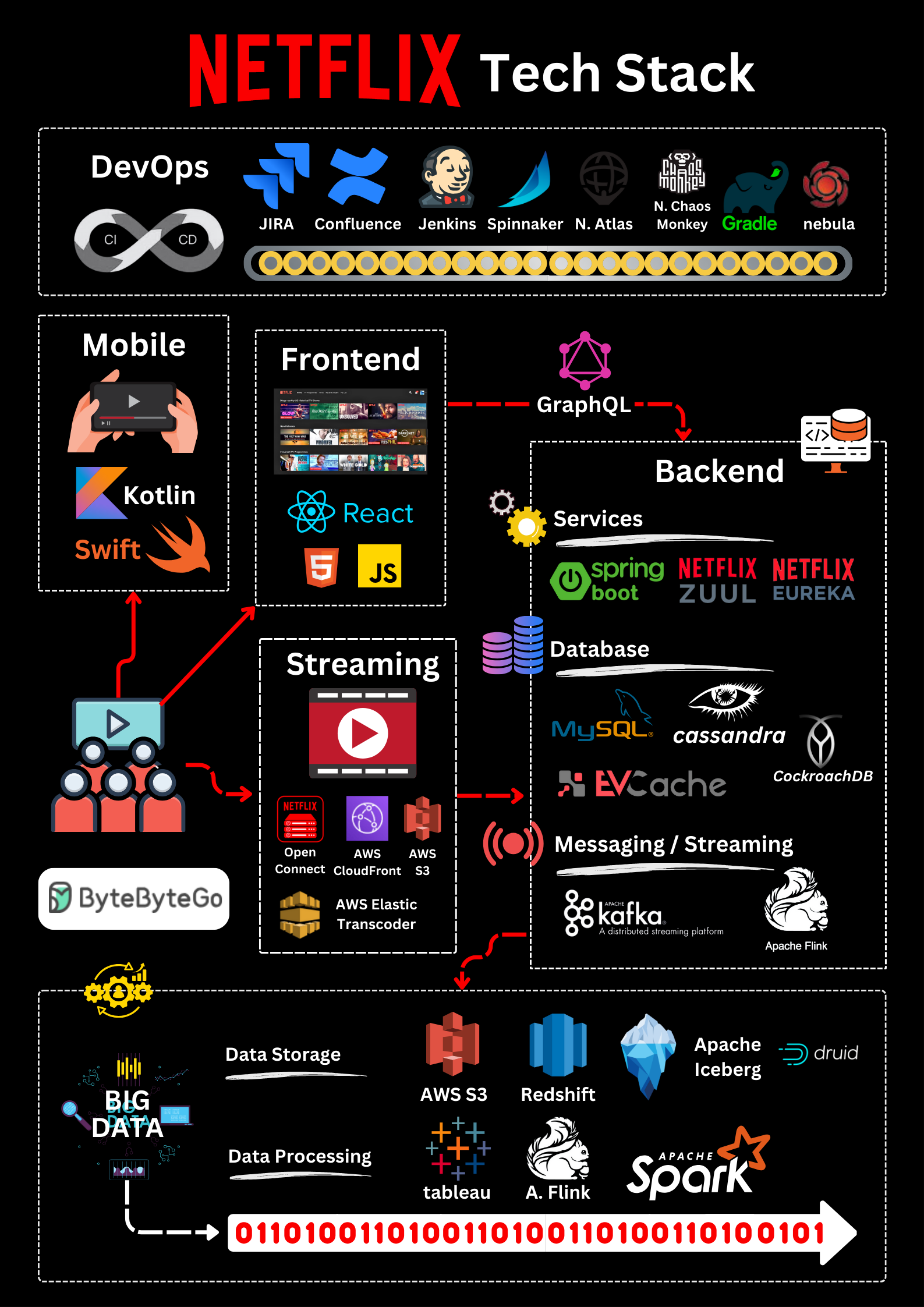
移动和网络:Netflix 采用 Swift 和 Kotlin 构建本地移动应用程序。在网络应用方面,它使用 React。
前端/服务器通信:Netflix 使用 GraphQL。
后台服务:Netflix 依靠 ZUUL、Eureka、Spring Boot 框架和其他技术。
数据库:Netflix 使用 EV 缓存、Cassandra、CockroachDB 和其他数据库。
消息传递/流媒体:Netflix 采用 Apache Kafka 和 Fink 进行消息传递和流媒体处理。
视频存储:Netflix 使用 S3 和 Open Connect 进行视频存储。
数据处理:Netflix 利用 Flink 和 Spark 进行数据处理,然后使用 Tableau 将数据可视化。Redshift 用于处理结构化数据仓库信息。
CI/CD:Netflix 在 CI/CD 流程中使用了 JIRA、Confluence、PagerDuty、Jenkins、Gradle、Chaos Monkey、Spinnaker、Atlas 等多种工具。
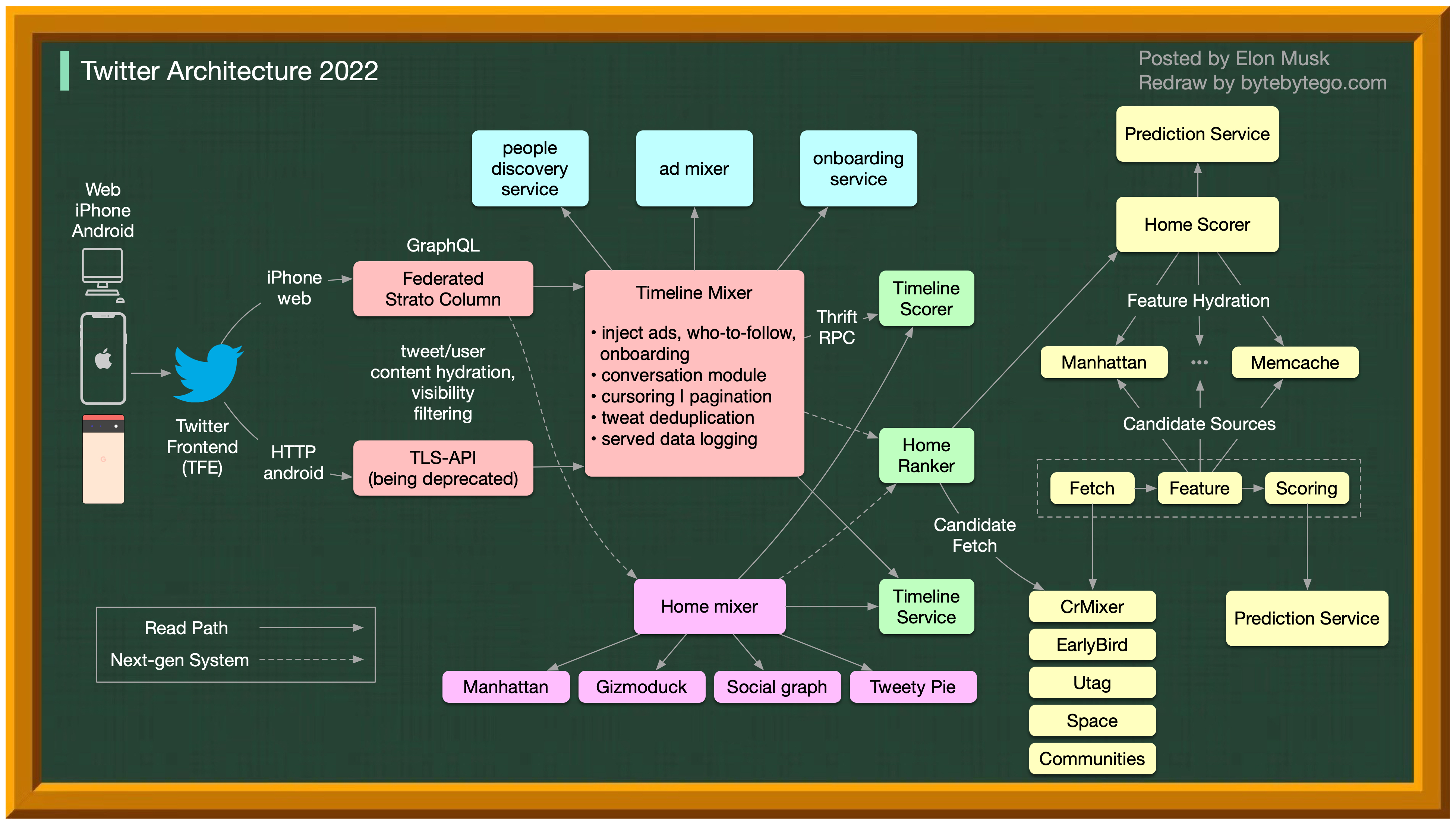
推特架构 2022
没错,这就是真正的 Twitter 架构。它是由埃隆-马斯克发布的,我们重新绘制了它,以提高可读性。
Airbnb 微服务架构在过去 15 年中的演变
Airbnb 的微服务架构主要经历了三个阶段。
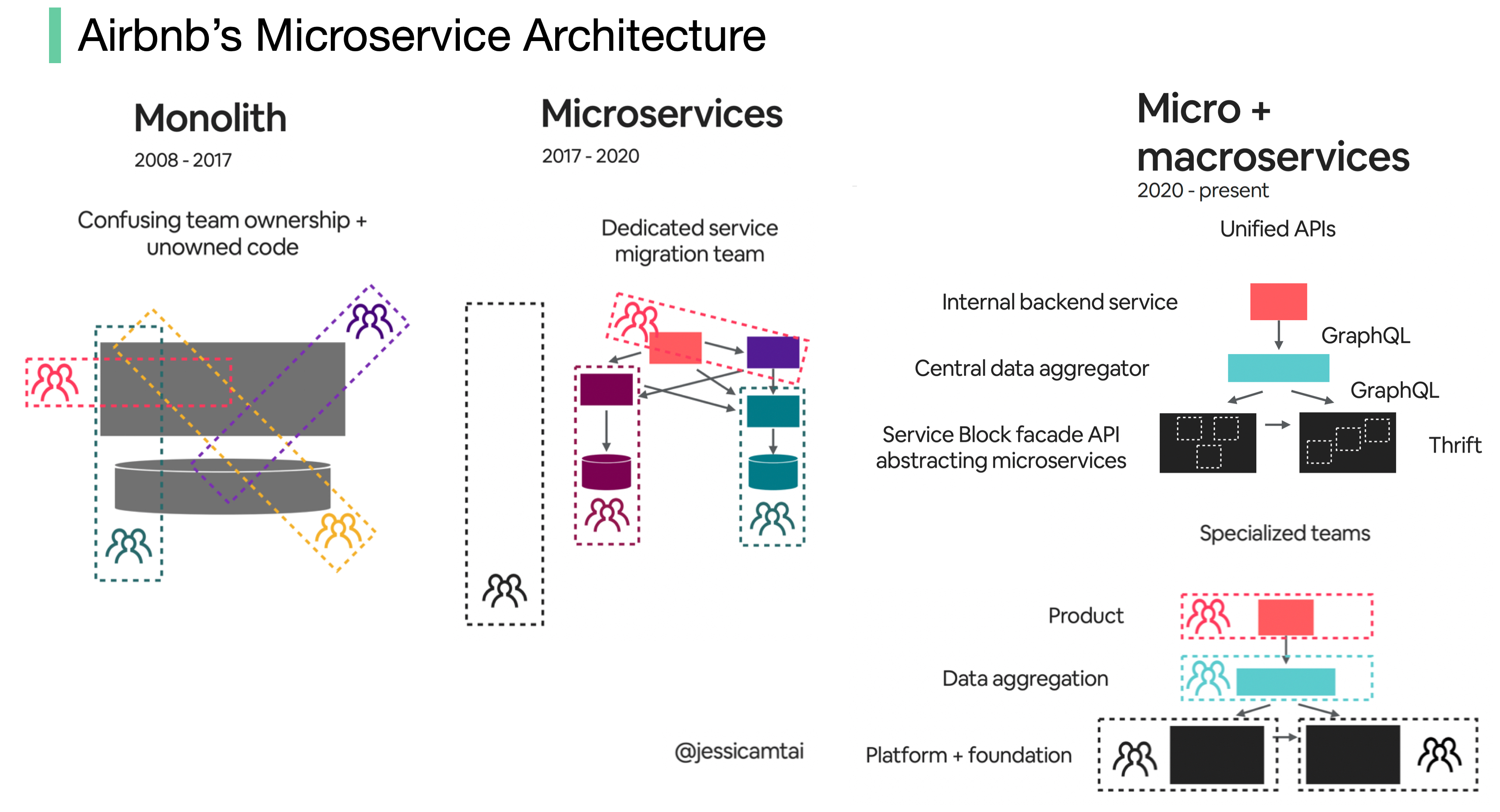
巨石(2008 - 2017)
Airbnb 最初只是一个简单的房东和客人市场。它是由 Ruby on Rails 应用程序构建而成的,即单体。
挑战是什么?
- 混淆团队所有权和非所有权代码
- 部署缓慢
微服务(2017 - 2020 年)
微服务旨在解决这些挑战。在微服务架构中,关键服务包括
- 数据获取服务
- 业务逻辑数据服务
- 编写工作流程服务
- 用户界面聚合服务
- 每项服务都有一个拥有团队
挑战是什么?
数以百计的服务和依赖关系是人类难以管理的。
微服务 + 宏服务(2020 年至今)
这就是 Airbnb 目前正在努力的方向。微服务和宏服务混合模式的重点是统一应用程序接口。
Monorepo 与 Microrepo。
哪种方案最好?为什么不同的公司选择不同的方案?
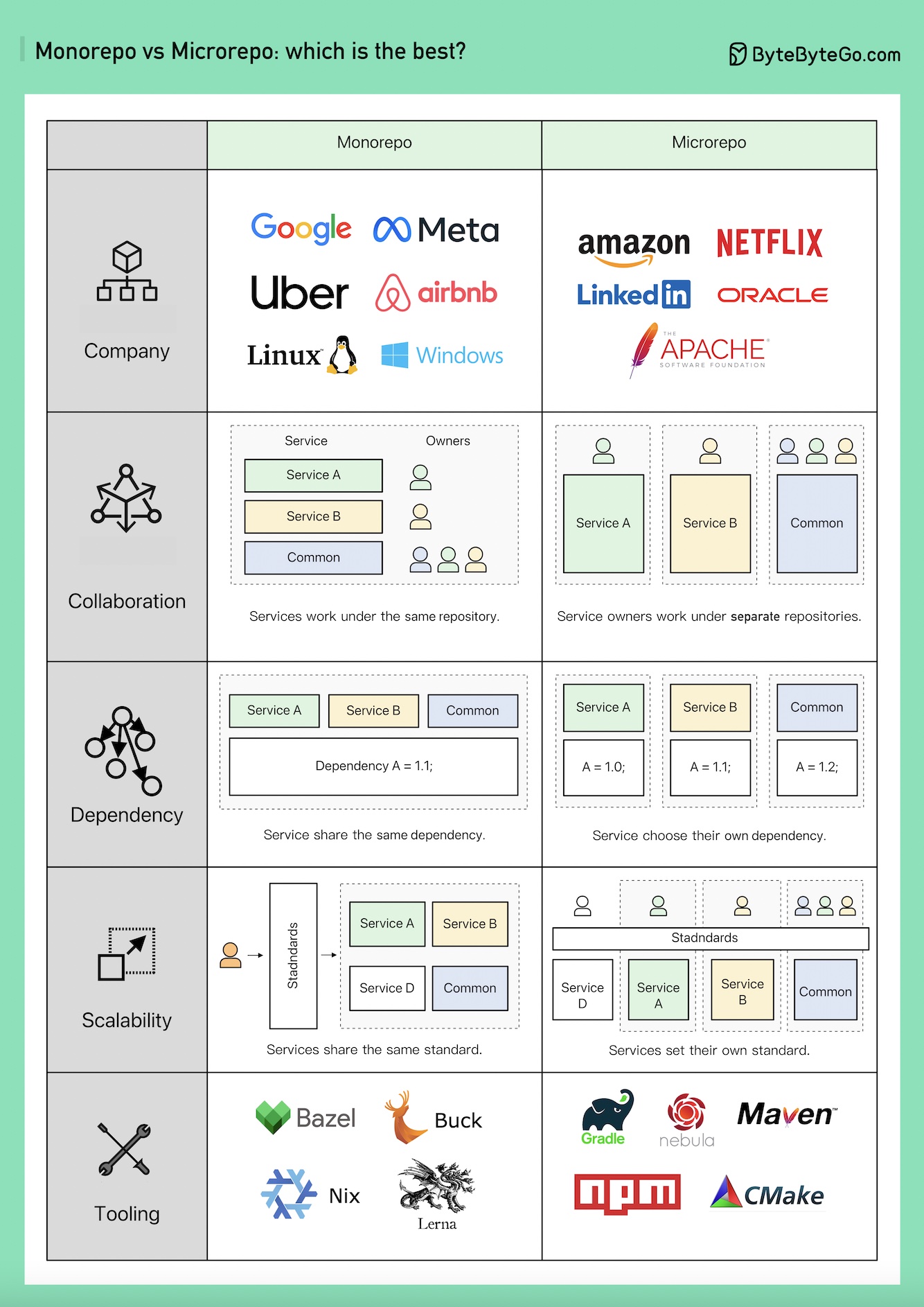
Monorepo 并不新鲜;Linux 和 Windows 都是使用 Monorepo 创建的。为了提高可扩展性和构建速度,谷歌开发了内部专用工具链以加快扩展速度,并制定了严格的编码质量标准以保持一致性。
亚马逊和 Netflix 是微服务理念的主要倡导者。这种方法自然而然地将服务代码分离到不同的资源库中。它的扩展速度更快,但可能会导致日后的治理痛点。
在 Monorepo 中,每个服务都是一个文件夹,每个文件夹都有 BUILD 配置和 OWNERS 权限控制。每个服务成员负责自己的文件夹。
另一方面,在 Microrepo 中,每个服务负责自己的版本库,通常为整个版本库设置构建配置和权限。
在 Monorepo 中,依赖关系在整个代码库中共享,与业务无关,因此当版本升级时,每个代码库都会升级自己的版本。
在 Microrepo 中,依赖关系受控于每个版本库。企业可根据自己的时间表选择何时升级版本。
Monorepo 有一个签到标准。谷歌的代码审查流程以设置高标准而闻名,确保 Monorepo 的质量标准一致,无论业务如何。
Microrepo 既可以制定自己的标准,也可以通过采纳最佳实践来采用共享标准。它可以更快地扩展业务,但代码质量可能会有些不同。谷歌工程师开发了 Bazel,Meta 开发了 Buck。还有其他开源工具,包括 Nix、Lerna 等。
多年来,Microrepo 支持的工具越来越多,包括 Java 的 Maven 和 Gradle、NodeJS 的 NPM 和 C/C++ 的 CMake 等等。
您将如何设计 Stack Overflow 网站?
如果你的答案是内部部署服务器和单片机(如下图底部),你很可能无法通过面试,但这就是现实中的构建方式!

人们认为它应该是什么样子
面试官可能希望看到类似图片上半部分的内容。
- 微服务用于将系统分解成小的组件。
- 每个服务都有自己的数据库。大量使用缓存。
- 服务是分片的。
- 服务之间通过消息队列进行异步对话。
- 该服务是利用 CQRS 的事件源功能实现的。
- 展示分布式系统知识,如最终一致性、CAP 定理等。
它究竟是什么
Stack Overflow 仅使用 9 台内部网络服务器为所有流量提供服务,而且是单体服务器!它有自己的服务器,不在云上运行。
这与我们如今的流行观念背道而驰。
亚马逊 Prime Video 监控为何从无服务器转向单体?如何节省 90% 的成本?
下图显示了迁移前后的架构对比。
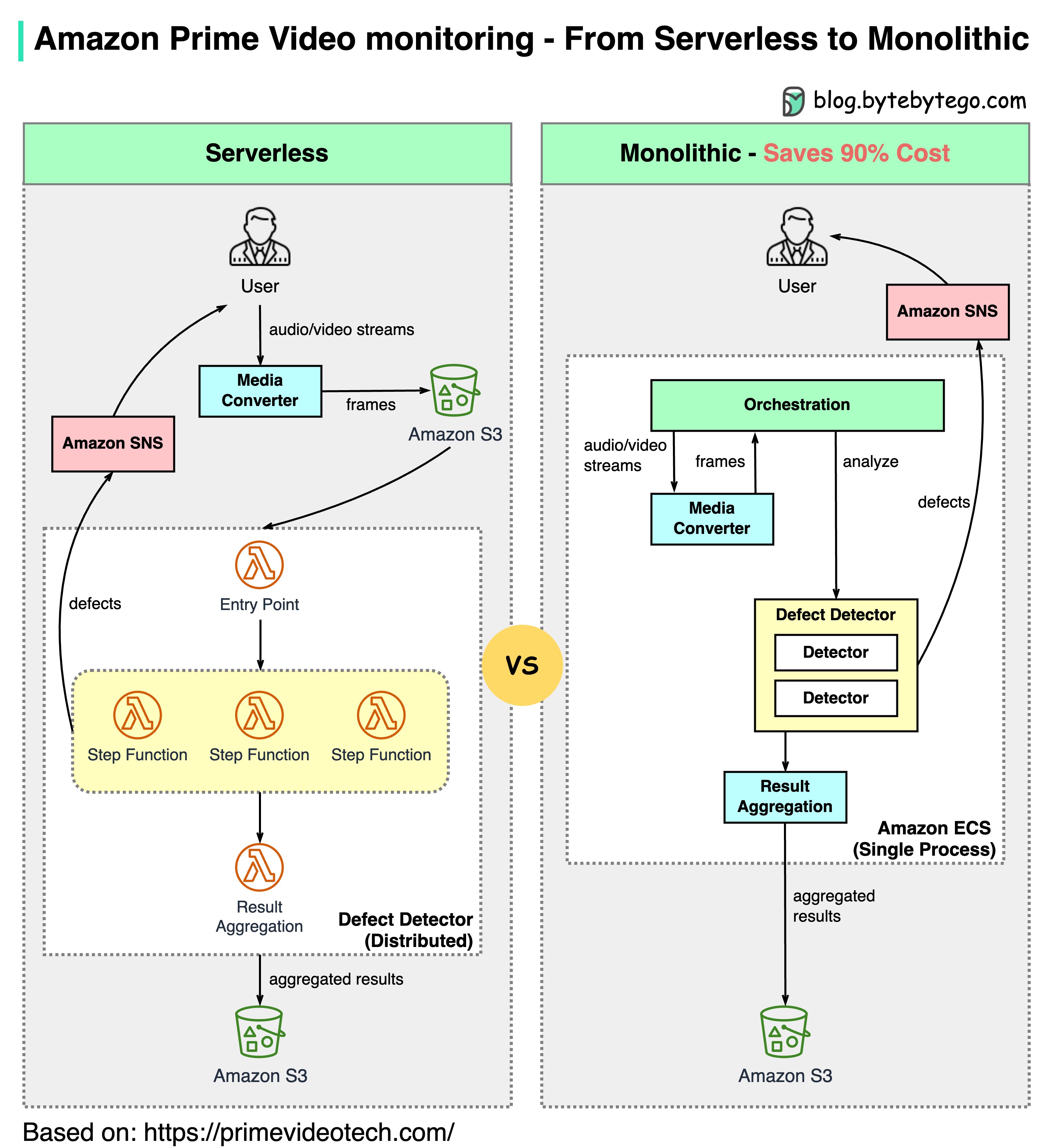
什么是亚马逊 Prime 视频监控服务?
Prime Video 服务需要监控数千个直播流的质量。监控工具会自动对流媒体进行实时分析,并识别块损坏、视频冻结和同步问题等质量问题。这是提高客户满意度的重要流程。
共有 3 个步骤:媒体转换器、缺陷检测器和实时通知。
-
旧架构有什么问题?
旧架构基于亚马逊 Lambda,适合快速构建服务。但是,在大规模运行该架构时,其成本效益并不高。最昂贵的两个操作是
- 协调工作流–AWS 步进功能通过状态转换向用户收费,协调每秒执行多个状态转换。
- 分布式组件之间的数据传递–中间数据存储在亚马逊 S3 中,以便下一阶段下载。当数据量较大时,下载的成本可能会很高。
-
单片架构可节省 90% 的成本
设计单片架构是为了解决成本问题。虽然仍有 3 个组件,但媒体转换器和缺陷检测器部署在同一流程中,从而节省了通过网络传输数据的成本。令人惊讶的是,这种部署架构变革方法节省了 90% 的成本!
这是一个有趣而独特的案例研究,因为微服务已成为科技行业的首选和时尚。令人欣慰的是,我们正在就架构的发展进行更多的讨论,并对其利弊进行更坦诚的讨论。将组件分解成分布式微服务是有代价的。
-
亚马逊领导对此有何评论?
亚马逊首席技术官 Werner Vogels:“构建可进化的软件系统是一种战略,而不是一种信仰。以开放的心态重新审视你的架构是必须的”。
前亚马逊可持续发展副总裁 Adrian Cockcroft:“Prime Video 团队走的是一条我称之为无服务器优先(Serverless First)的道路……我并不主张只使用无服务器”。
迪斯尼 Hotstar 如何在一场比赛中捕获 50 亿个表情符号?
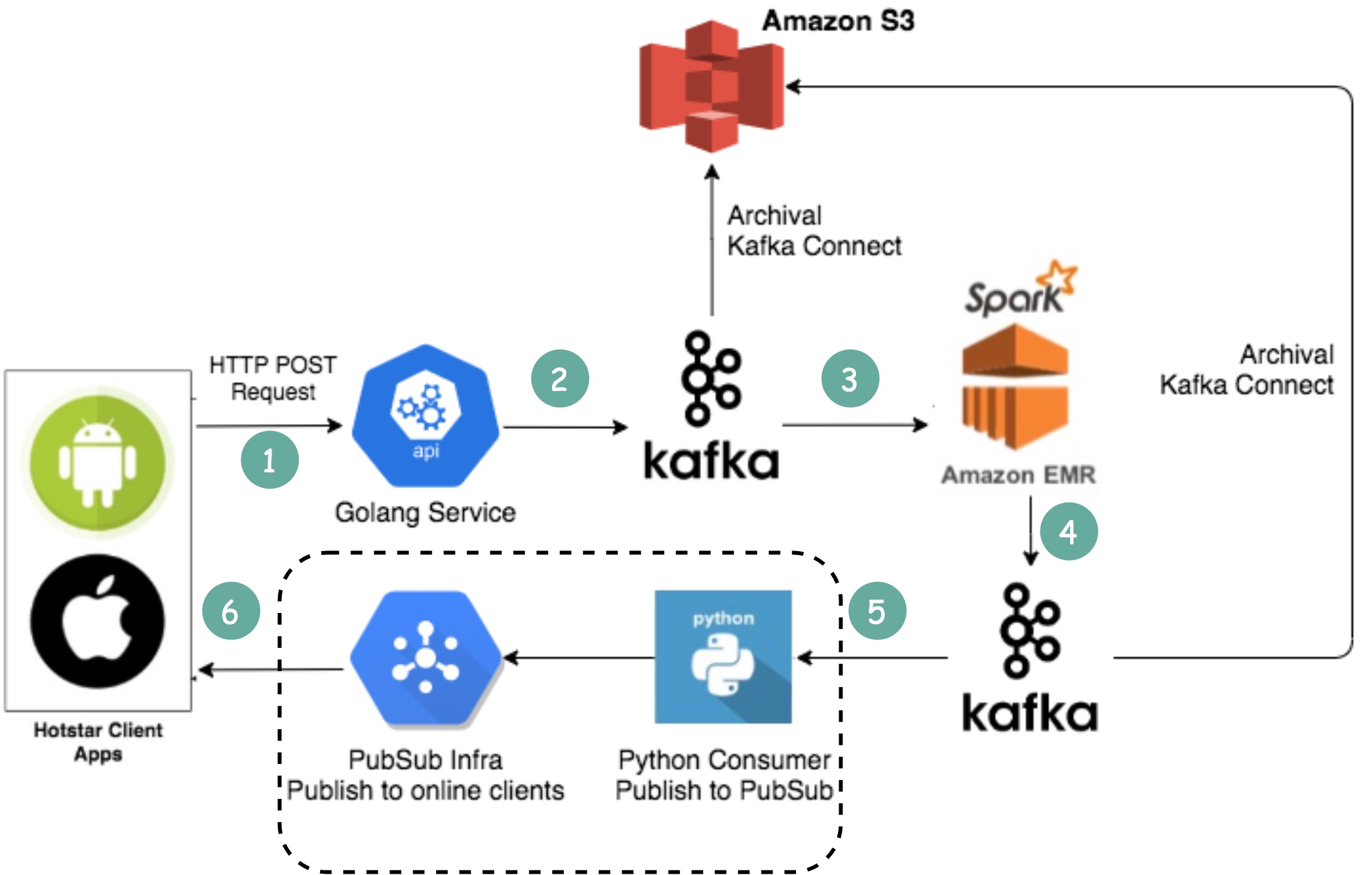
- 客户端通过标准 HTTP 请求发送表情符号。您可以将 Golang 服务视为典型的 Web 服务器。之所以选择 Golang,是因为它能很好地支持并发性。Golang 中的线程是轻量级的。
- 由于写入量非常大,Kafka(消息队列)被用作缓冲区。
- Emoji 数据由名为 Spark 的流式处理服务聚合。它每 2 秒钟聚合一次数据,这个时间间隔是可以配置的。需要根据时间间隔进行权衡。更短的时间间隔意味着表情符号能更快地传送到其他客户端,但也意味着需要更多的计算资源。
- 汇总后的数据将写入另一个 Kafka。
- PubSub 消费者从 Kafka 提取表情符号聚合数据。
- 表情符号通过 PubSub 基础设施实时传送到其他客户端。PubSub 基础设施非常有趣。Hotstar 考虑了以下协议:Socketio、NATS、MQTT 和 gRPC,最终选择了 MQTT。
LinkedIn 也采用了类似的设计,它能以每秒一百万个赞的速度传播信息。
Discord 如何存储数以万亿计的信息
下图显示了 Discord 消息存储的演变过程:
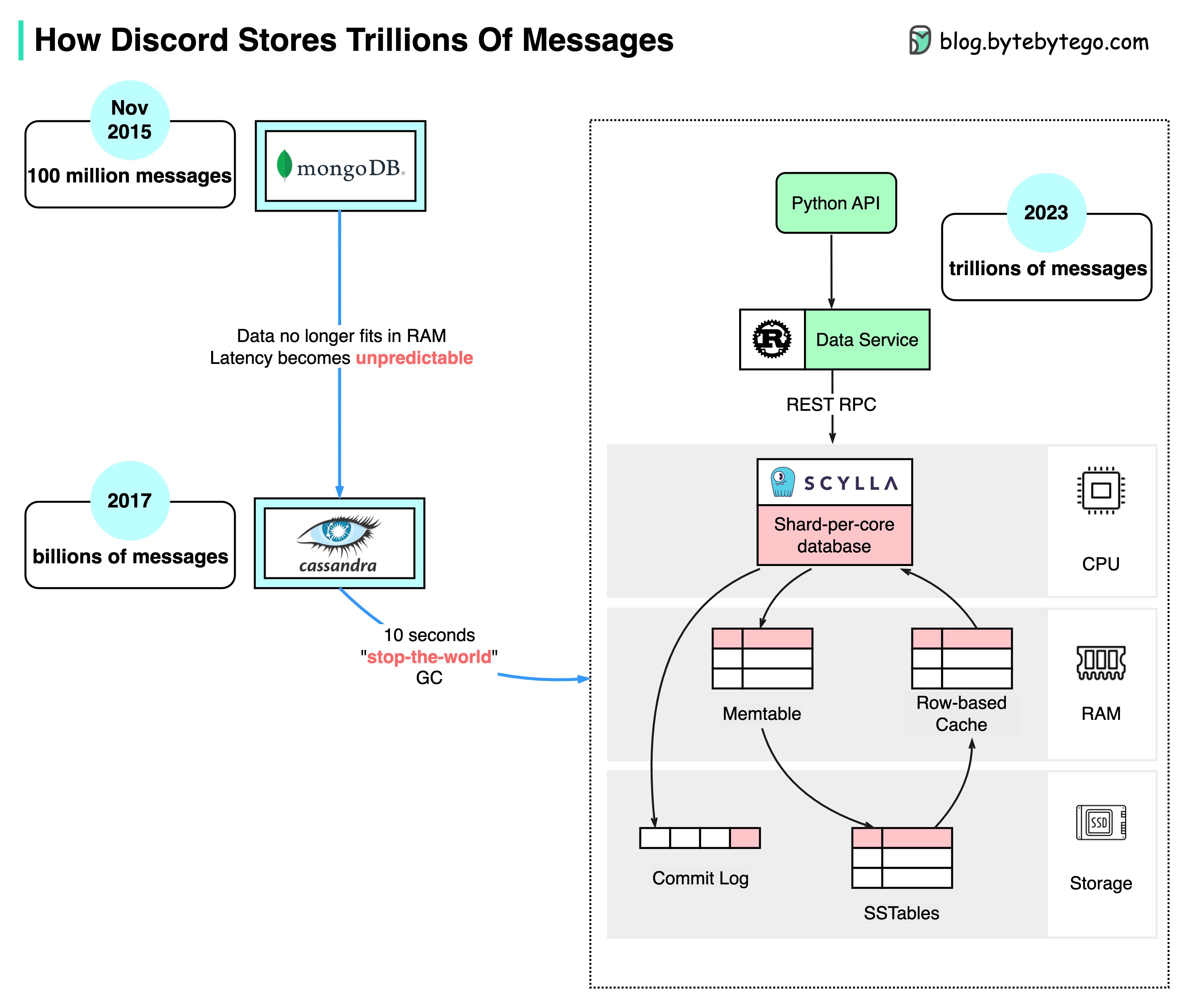
MongoDB ➡️ Cassandra ➡️ ScyllaDB
2015 年,Discord 的第一个版本建立在单个 MongoDB 复制之上。2015 年 11 月左右,MongoDB 存储了 1 亿条消息,RAM 无法再容纳数据和索引。延迟变得不可预测。消息存储需要转移到另一个数据库。最终选择了 Cassandra。
2017 年,Discord 拥有 12 个 Cassandra 节点,存储了数十亿条信息。
2022 年初,它拥有 177 个节点,信息量达数万亿条。此时,延迟不可预测,维护操作成本过高。
造成这一问题的原因有几个:
- Cassandra 使用 LSM 树作为内部数据结构。读取比写入更昂贵。在一台拥有数百名用户的服务器上,可能会有很多并发读取,从而产生热点。
- 维护群集(如压缩 SST 表)会影响性能。
- 垃圾收集暂停会导致明显的延迟峰值
ScyllaDB 是用 C++ 编写的 Cassandra 兼容数据库。Discord 重新设计了自己的架构,使其具有单片式 API、用 Rust 编写的数据服务和基于 ScyllaDB 的存储。
ScyllaDB 的 p99 读取延迟为 15 毫秒,而 Cassandra 为 40-125 毫秒。p99 的写延迟为 5 毫秒,而 Cassandra 为 5-70 毫秒。
YouTube、TikTok Live 或 Twitch 上的视频直播是如何进行的?
实时流媒体不同于普通流媒体,因为视频内容是通过互联网实时发送的,延迟时间通常只有几秒钟。
下图解释了实现这一点的幕后原因。
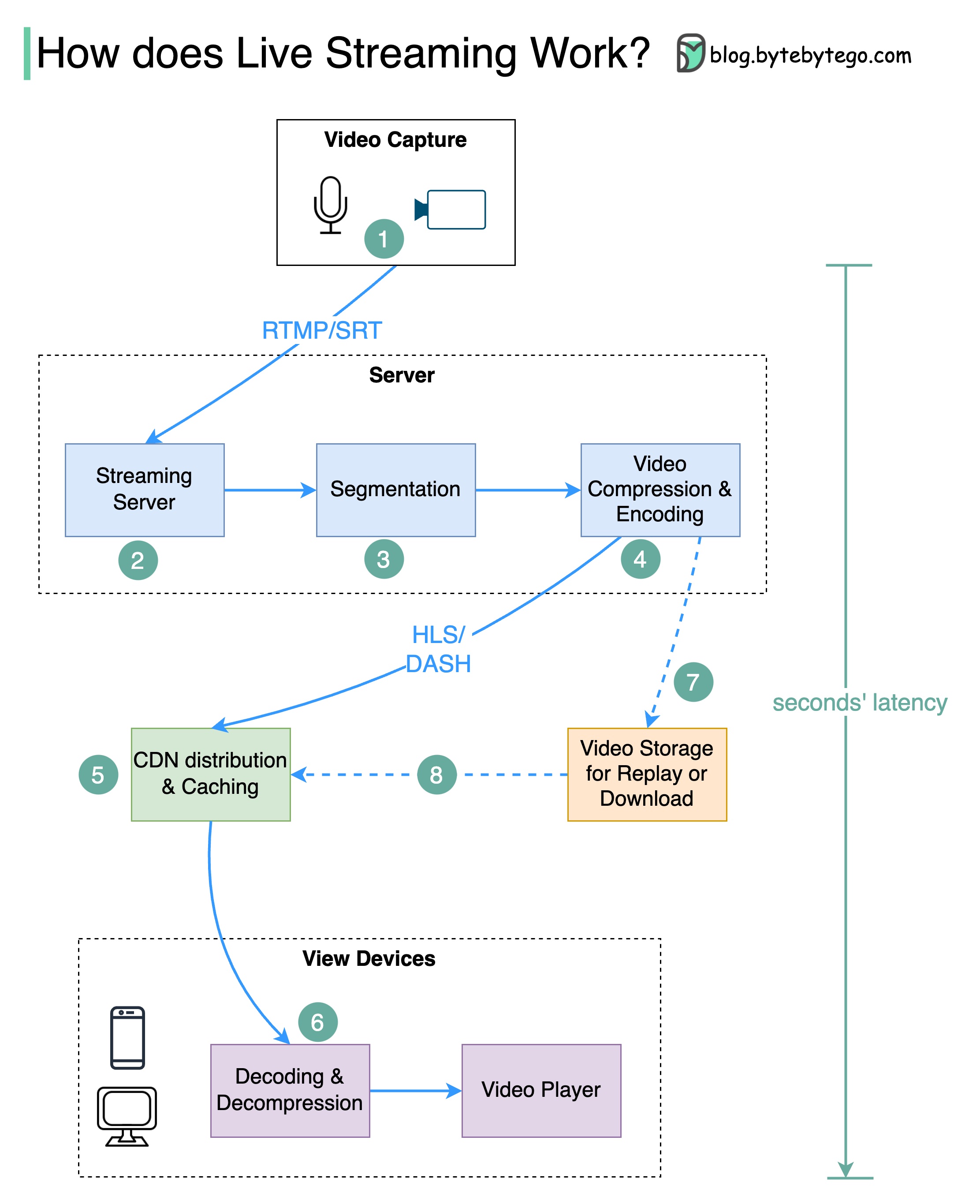
步骤 1:原始视频数据由麦克风和摄像头采集。数据被发送到服务器端。
步骤 2:对视频数据进行压缩和编码。例如,压缩算法会分离背景和其他视频元素。压缩后,按照 H.264 等标准对视频进行编码。经过这一步骤后,视频数据的大小会小得多。
步骤 3:编码后的数据被分成较小的片段,长度通常为几秒钟,因此下载或流式传输所需的时间更短。
步骤 4:将分段数据发送到流媒体服务器。流媒体服务器需要支持不同的设备和网络条件。这就是所谓的 “自适应比特率流”。这意味着我们需要在步骤 2 和 3 中以不同的比特率生成多个文件。
步骤 5:将实时流媒体数据推送到 CDN(内容分发网络)支持的边缘服务器。CDN 大大降低了数据传输延迟。
步骤 6:观众的设备对视频数据进行解码和解压,并在视频播放器中播放视频。
第 7 步和第 8 步:如果视频需要存储以便重放,则将编码数据发送到存储服务器,观众可在稍后要求重放。
实时流媒体的标准协议包括
- RTMP(实时信息传输协议):最初由 Macromedia 开发,用于在 Flash 播放器和服务器之间传输数据。现在,它用于在互联网上传输视频数据流。请注意,Skype 等视频会议应用程序使用 RTC(实时通信)协议,以降低延迟。
- HLS(HTTP 实时流):它需要 H.264 或 H.265 编码。苹果设备只接受 HLS 格式。
- DASH(HTTP 动态自适应流):DASH 不支持苹果设备。
- HLS 和 DASH 都支持自适应比特率流媒体。
许可证
本作品采用 CC BY-NC-ND 4.0
许可协议进行许可。